- 지속가능한 데이터를 활용하기 위해 볼륨을 사용할 수 있으며, 호스트볼륨을 공유하거나, 볼륨컨테이터를 만들어 활용하거나, 도커 볼륨을 활용할 수 있다.
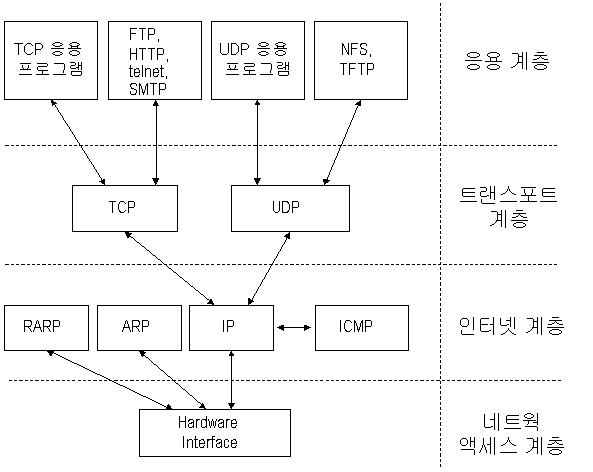
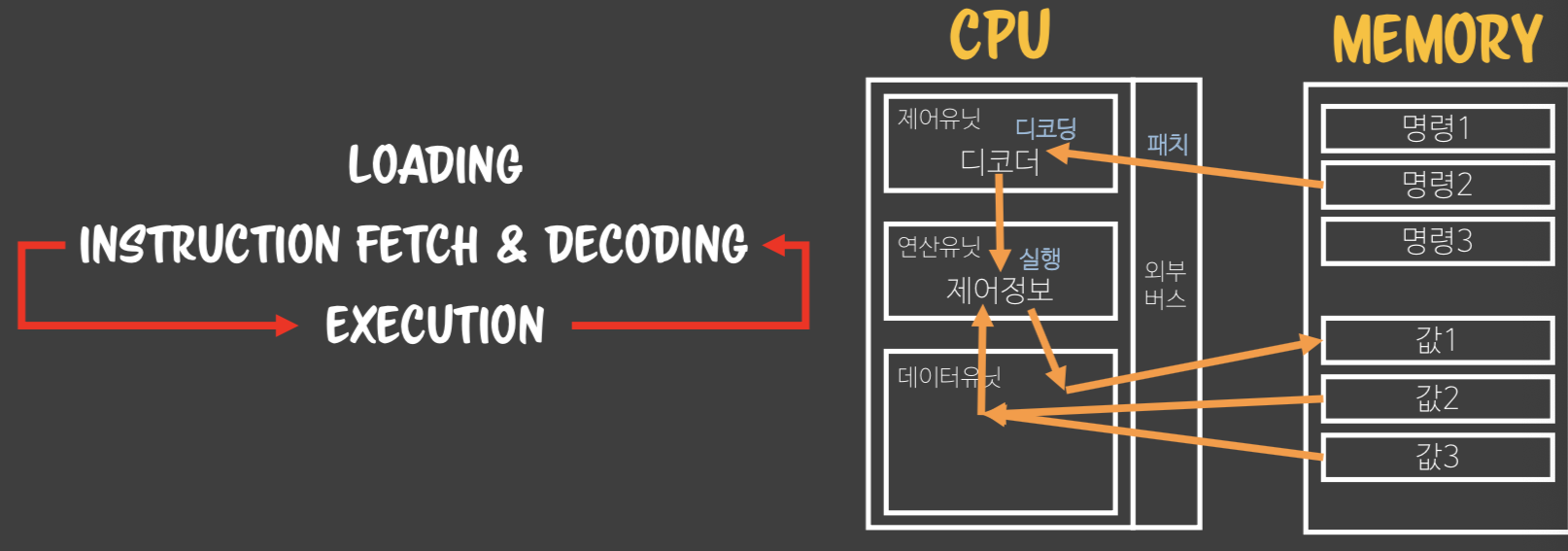
- 도커는 컨테이너 내부IP를 순차적으로 할당하며,(컨테이너 별로 내부망이 생성) veth 인터페이스로 접근가능하다. 도커가 자체적으로 제공하는 5가지 네트워크 드라이버가 존재한다.
- 도커는 컨테이너의 표준출력과 에러출력을 별도로 메타데이터 파일로 저장하며, 이를 확인가능하도록 한다. 로깅을 도와주는 써드파티 드라이버들도 존재한다.
도커 볼륨?
- 도커 이미지로 컨테이너 생성시 이미지는 read only
- 컨테이너 변경사항만 별도로 저장하여 보존한다.
- 컨테이너 계층에는 DB를 운용하면서 쌓이는 데이터가 저장됨
- 이미지에 mysql을 실행하는데 필요한 어플리케이션 파일이 존재
- 컨테이너는 생성,삭제가 쉬우므로 위험 발생 가능성 높음.
- 이를 방지하기위해 데이터를 Persistent데이터로 활용할 수 있는 방법이 몇가지 있다.
- 볼륨을 활용한다.
- 호스트 볼륨을 공유하는 방법
- 볼륨 컨테이너를 활용하는 방법
- 도커가 관리하는 볼륨을 생성할 수 있다.
1. 호스트 볼륨을 공유하는 방법
복사개념으로 컨테이너 directory를 host directory에 마운트한다.
예시
컨테이너 2가지 생성
- mysql DB container
- 워드프레스 웹 서버 container
1. mysql DB container
1 | ❯ docker run -d \ |
- 이름: wordpressdb_hostvolume
- 컨테이너 directory(
/home/wordpress_db)를 Host directory(/var/lib/mysql)에 마운트-v: [호스트 공유 디렉토리]:[컨테이너의 공유 디렉터리]-v /home/wordpress_db:/var/lib/mysql
2. 워드프레스 웹 서버 container
1 | ❯ docker run -d \ |
- 이름: wordpress_hostvolume
wordpressdb_hostvolume:mysql
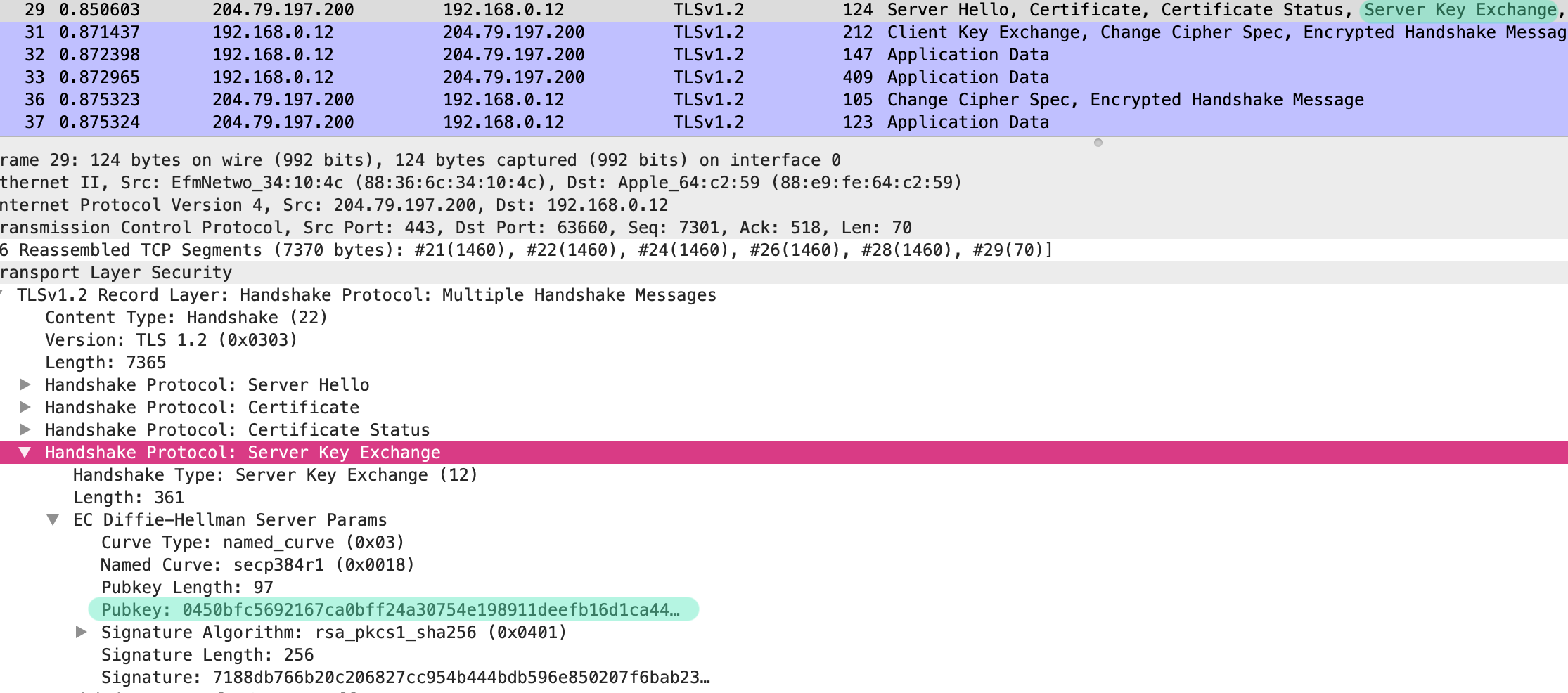
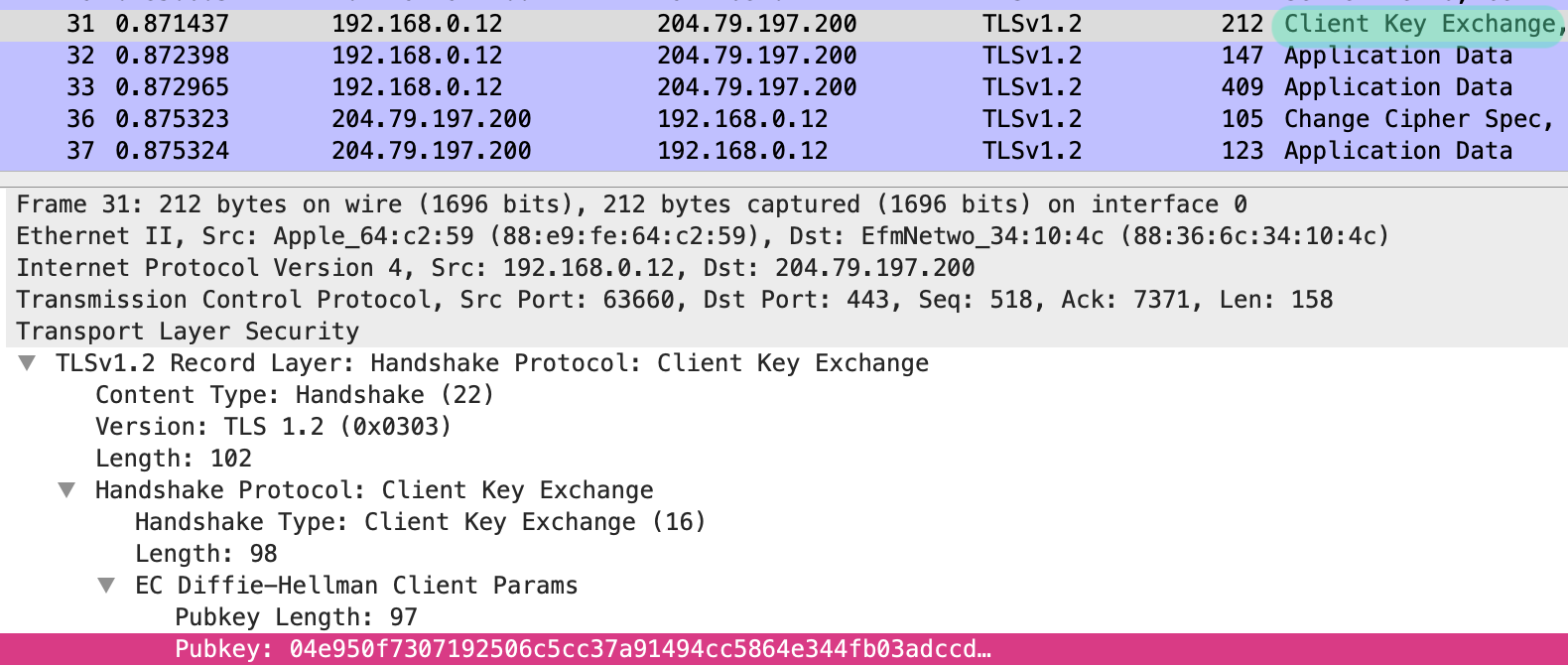
fyi; -v [호스트 공유 디렉토리]:[컨테이너의 공유 디렉터리]
- 호스트의 디렉토리와 컨테이너의 디렉토리를 공유한다는 뜻.
- 디렉토리말고 파일단위로 공유 가능
- -v 옵션은 한번에 여러번 쓸 수 있다.
- 동기화 아니고, 복사개념
- 오버라이딩: 호스트 공유할 디렉토리가 신규생성이 아닌경우(해당 경로에 무언가 파일이 있던경우) 오버라이딩 됨.
2. 볼륨 컨테이너를 활용하는 방법 (-volumes-from)
-v옵션으로 볼륨을 사용하는 컨테이너를, 다른 컨테이너와 공유하는 것A 컨테이너 생성시
—volumes-from옵션 설정하면-v옵션 적용한 컨테이너(B)의 볼륨 디렉터리를 공유할 수 있다.1
2
3
4docker run -i -t \
> --name volumes_from_container \
> --volumes-from volume_overide \ #volume_overide가 공유하는 것
> ubuntu:14.04여러개의 컨테이너가 동일한 컨테이너에 —volumes-from 사용하여 볼륨을 공유해 사용할수도 있다.
볼륨 컨테이너
- host에서 볼륨만 공유.
- 별도의 역할을 담당하지 않는 볼륨컨테이너로써 활용하는 것도 가능.
- 직접 호스트에서 공유가 아닌, 볼륨컨테이너를 통해서 간접적으로 공유 받는식
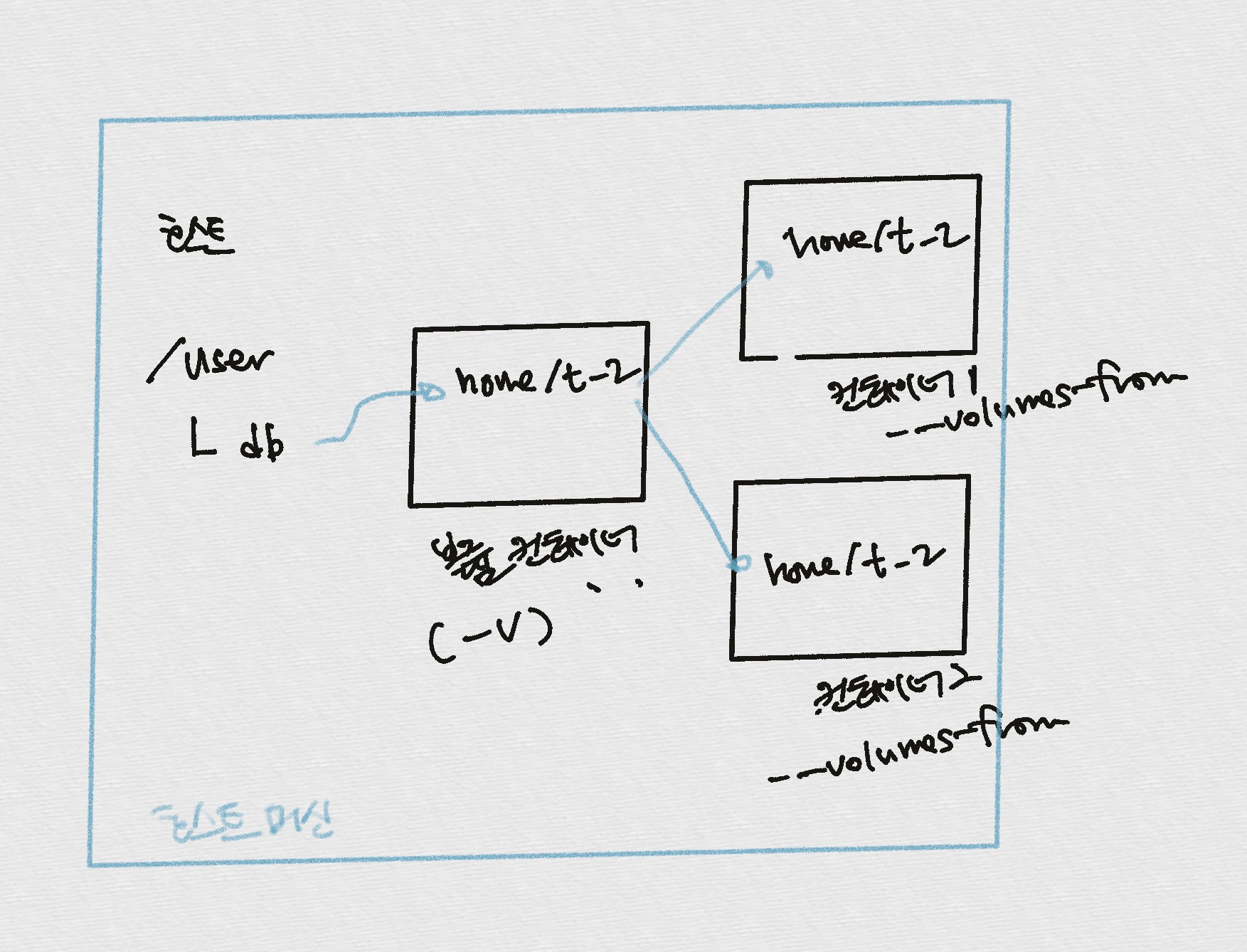
3. 도커가 관리하는 볼륨을 생성할 수 있다.
도커 자체에서 제공하는 볼륨기능을 활용해, 데이터를 보존할 수도 있다.
- 도커 볼륨은 디렉토리 하나에 상응하는 단위. 도커엔진에서 관리한다.
- 도커 볼륨은 호스트에 저장하여 데이터 보존 (어디에 보관되어있는지는 알필요없음 우선순위낮)
1. 볼륨 생성
1 | docker volume create --name myvolume |
- 볼륨 생성시, 플러그인 드라이버를 설정하여, 여러종류의 storage 백엔드 사용가능
- 활하며 동시 생성 가능
- 똑같이
-v사용. 컨테이너 디렉토리만 넣어두면, 도커볼륨 자동 생성
- 똑같이
1 | docker run -i -t \ |
1 | [볼륨의 이름]:[컨테이너의 공유 디렉토리] |
2. 볼륨 삭제
docker volumn prune- 도커볼륨을 사용하고 있는 컨테이너를 삭제해도, 볼륨이 자동으로 삭제되지 않는다.
fy; Stateless 설계
- 컨테이너가 아닌, 외부에서 데이터를 저장하고
컨테이너는 외부에서의 데이터로 동작하도록 설계하는 것 - == 컨테이너 자체는 상태가 없고,
상태를 결정하는 데이터는 외부로부터 제공받는다. - == 컨테이너가 삭제돼도, 데이터는 보존되므로,
stateless한 컨테이너 설계는 도커사용시 바람직한 설계 - stateful한 컨테이너는 지양해야함.
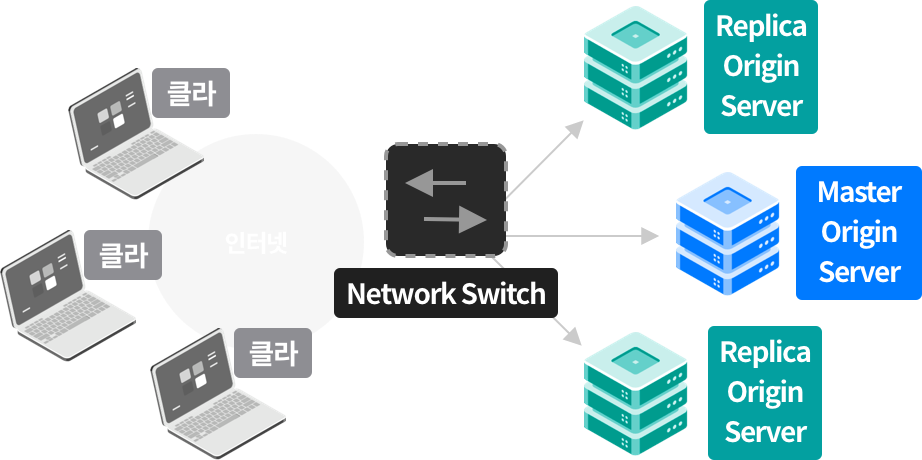
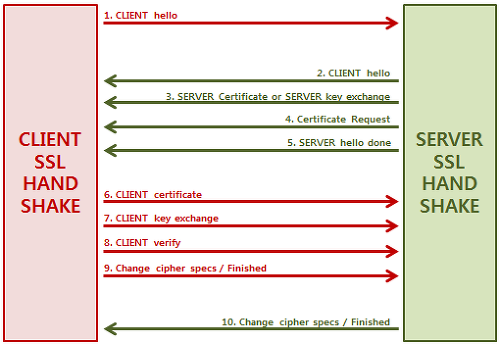
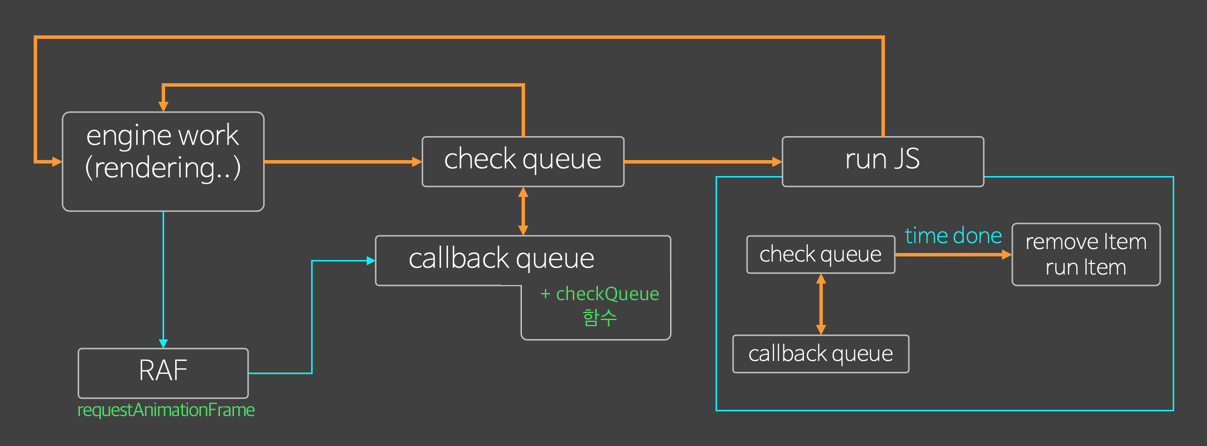
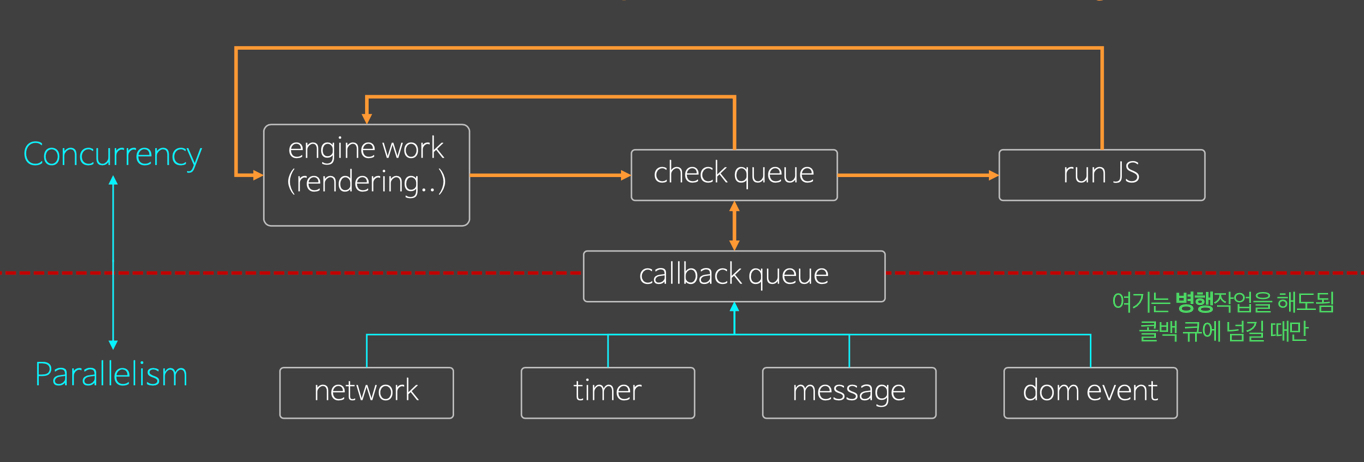
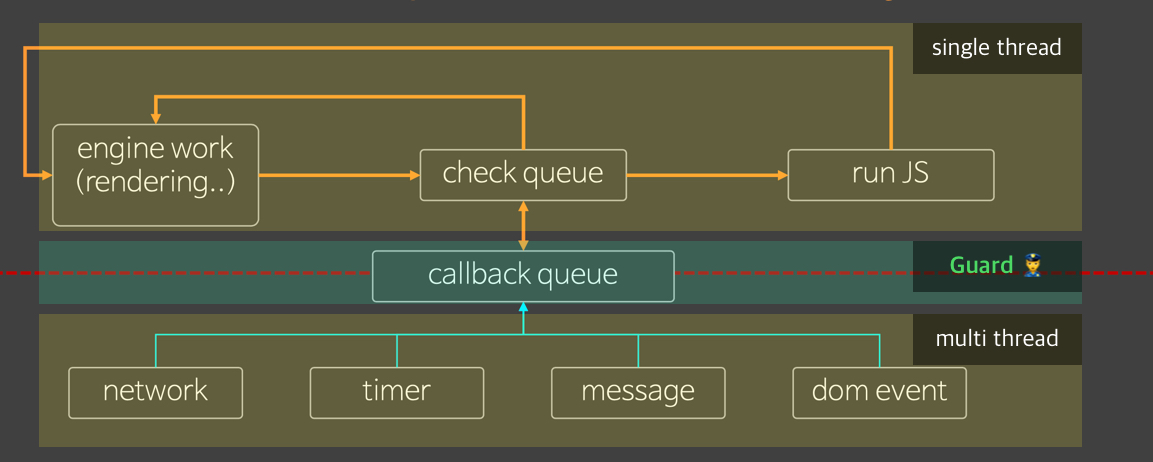
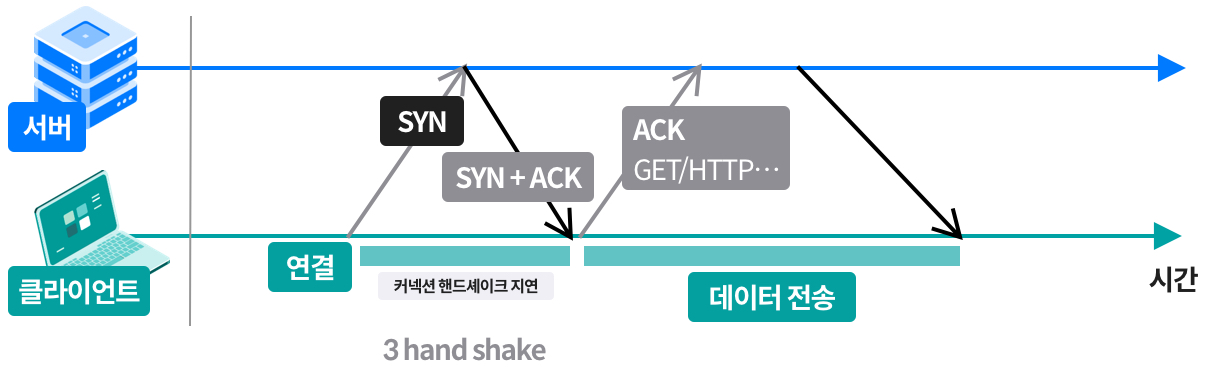
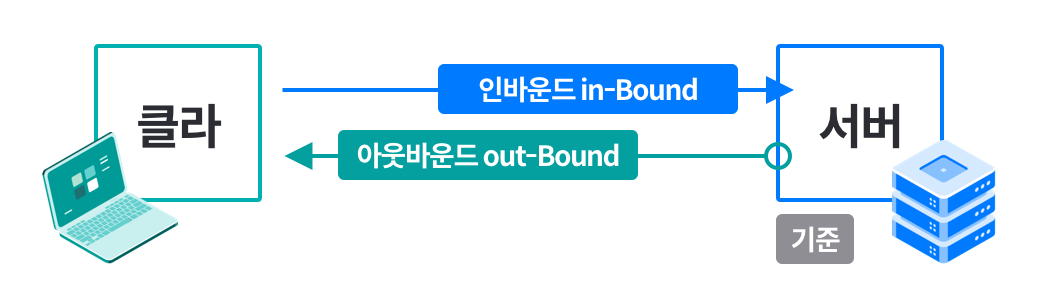
도커 네트워크 구조
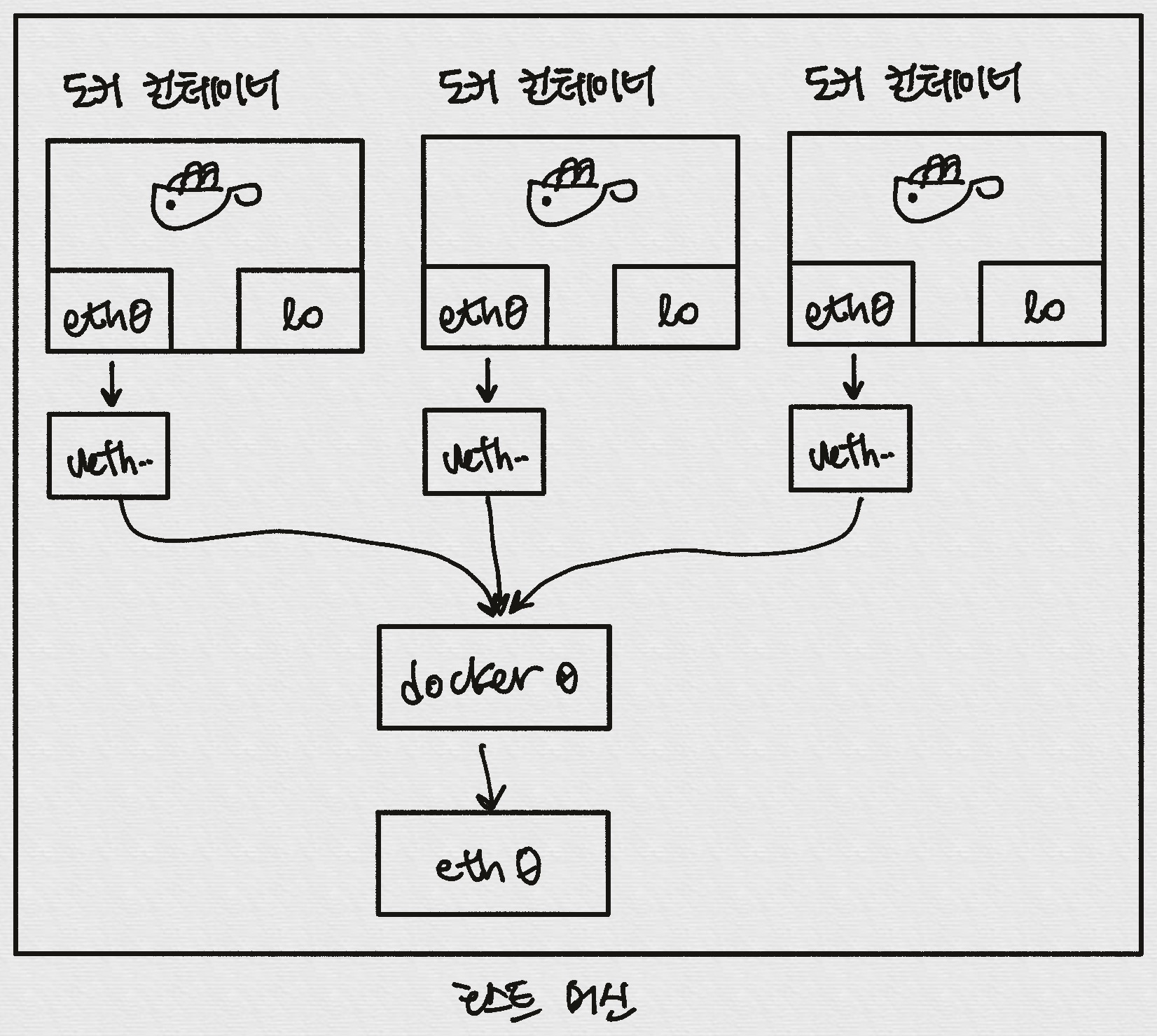
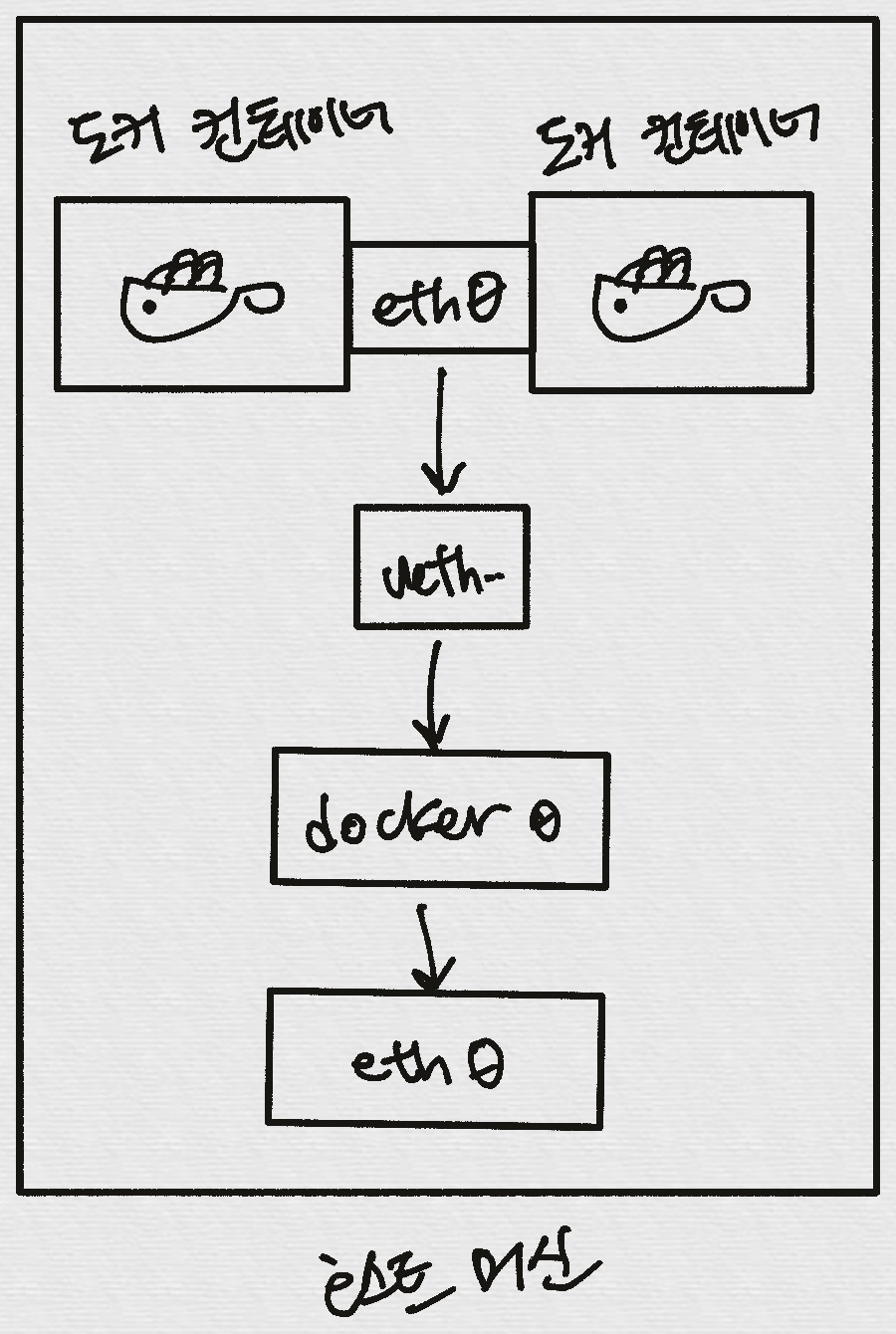
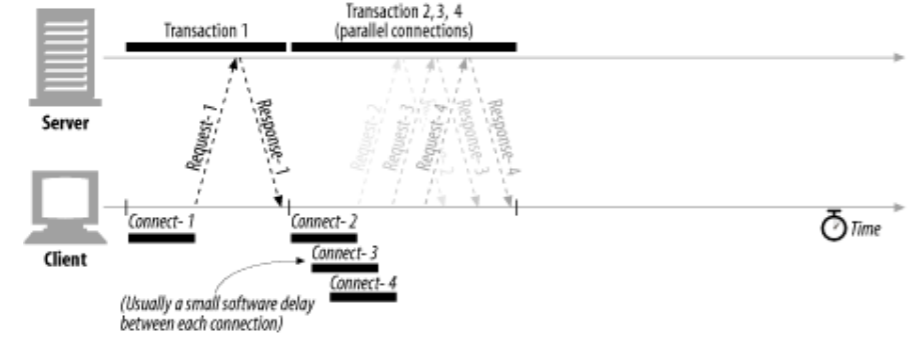
- 도커는 컨테이너 내부IP를 순차적으로 할당
- 내부IP는 내부망(도커가 설치된 host)에서 쓸 수 있는 IP.
- 컨테이너를 시작할때마다, 호스트에
veth..라는 네트워크 인터페이스를 생성함으로써 이루어진다.- fyi;
veth: virtual eth - 도커는 각 컨테이너에 외부와의 네트워크를 제공하기 위해,
컨테이너마다 가상 네트워크 인터페이스를 호스트에 자동 생성
→ veth로 이름이 시작
- fyi;
1 | root@75308a74b2c2:/# ifconfig |
도커 네트워크 기능
컨테이너 생성시
- 기본적으로:
docker0브릿지를 통해, 외부와 통신할 수 있는 환경을 사용할 수 있다. - custom 가능: 사용자의 선택에 따라 여러 네트워크 드라이버 사용가능
도커가 자체적 제공하는 네트워크 드라이버
써드파티 플러그인 솔루션
1 | ❯ docker network ls |
브릿지 bridge
사용자 정의 브릿지를 새로 생성해, 각 컨테이너에 연결하는 네트워크 구조.
컨테이너는 연결된 브릿지를 통해 외부와 통신 가능
브릿지 생성하기
1
docker network create --driver bridge mybridge
--net옵션으로 컨테이너가 네트워크 사용가능1
2
3docker run -i -t --name mynetwork_container \
--net mybridge \
ubuntu:14.04네트워크 연결:
docker network connect네트워크 분리:
docker network disconnect
--net-alias
- 특정 호스트 이름으로, 컨테이너 여러개에 접근 가능
--net-alias- 순차적으로 할당된다. (
172.18.0.3~5)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16❯ docker run -i -t -d --name network_alias_container1 \
> --net mybridge \
> --net-alias alicek106 ubuntu:14.04
616982dd067988f1e76a04709ad74287dceb73410f886f1630b8364634fe4565
~
❯ docker run -i -t -d --name network_alias_container2 \
--net mybridge \
--net-alias alicek106 ubuntu:14.04
4d56a82ace82cc8118e9ef8d5502db76497fce0f7499960f5dcb624c8a006eaf
^[[A
~
❯ docker run -i -t -d --name network_alias_container3 \
--net mybridge \
--net-alias alicek106 ubuntu:14.04
d90963f31e42595264165839fbff2d78f8075640f5a4cea6e6782481636edbf9
- 순차적으로 할당된다. (
Docker DNS, Round-Robin 방식
Round-Robin
- 매번 달라지는 IP를 결정하는 것은 별도의 알고리즘이 아닌, round-robin 방식
- 하나의 중앙처리장치를 여러 프로세스들이 우선순위 없이 돌아가며 할당받아 실행되는 방식
- 도커에 내장된 DNS가 alicek106 호스트 이름을 alicek106 을 설정한 컨테이너로 변환 resolve 하기 때문이다.
dig라는 명령어로 확인가능.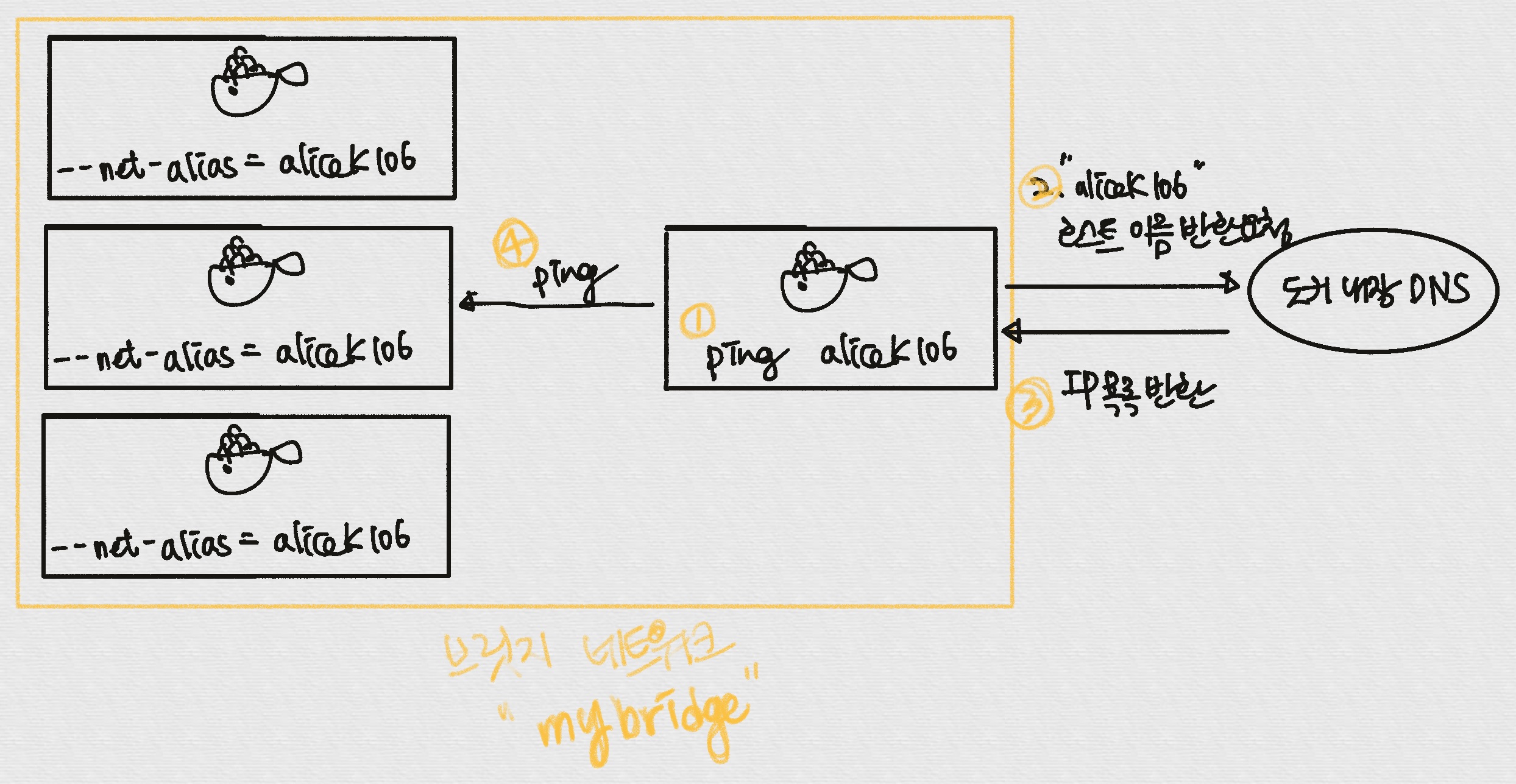
Docker DNS
- 호스트이름으로 유동적인 컨테이너를 찾을 때 주로 사용됨.
—-link: 컨테이너의 IP가 변경돼도, 별명으로 컨테이너를 찾을 수 있게 DNS에 의해 자동관리--not-alias: 도커는 사용자가 정의한 브릿지 네트워크에 사용되는 내장 DNS 서버를 갖는다.- DNS의 IP는 127.0.0.11
- 위 예시에서는 컨티에너의 IP는 DNS 서버에
alicek106이라는 호스트 이름으로 등록됨
호스트 네트워크
- 컨테이너의 네트워크를 → 호스트 모드로 설정하면,
- 컨테이너 내부의 어플리케이션을 별도의 port forwarding없이 바로 서비스할 수 있다.
- 실제 호스트에서 어플리케이션을 외부에 노출하는 것과 같다.
1
2
3docker run -i -t --name mynetwork_host \
--net host \
ubuntu:14.04
none 네트워크
말그대로 아무런 네트워크를 쓰지 않는 것.
- 외부와 연결이 단절됨
lo외에는 존재하지 않는다.
1 | docker run -i -t --name mynetwork_none \ |
container 네트워크
- 다른 컨테이너의 네트워크 네임스페이스 환경을 공유할 수 있다.
- 공유되는 속성 : 내부 IP, 네트워크 인터페이스의 mac주소 등..
1
2
3docker run -i -t --name mynetwork_none \
--net container:network_container_1 \
ubuntu:14.04
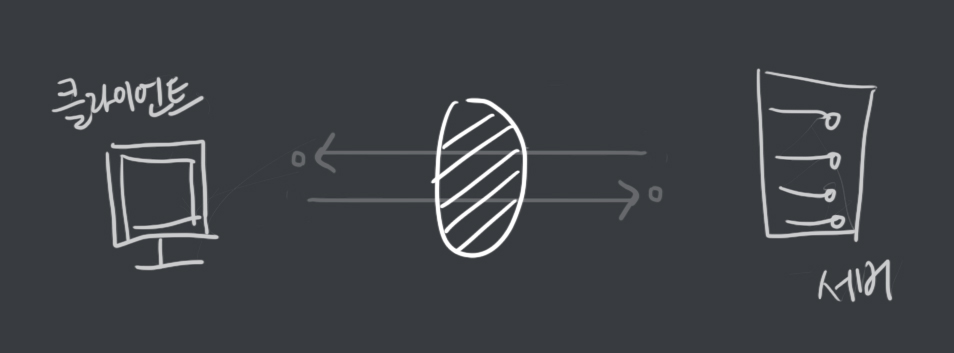
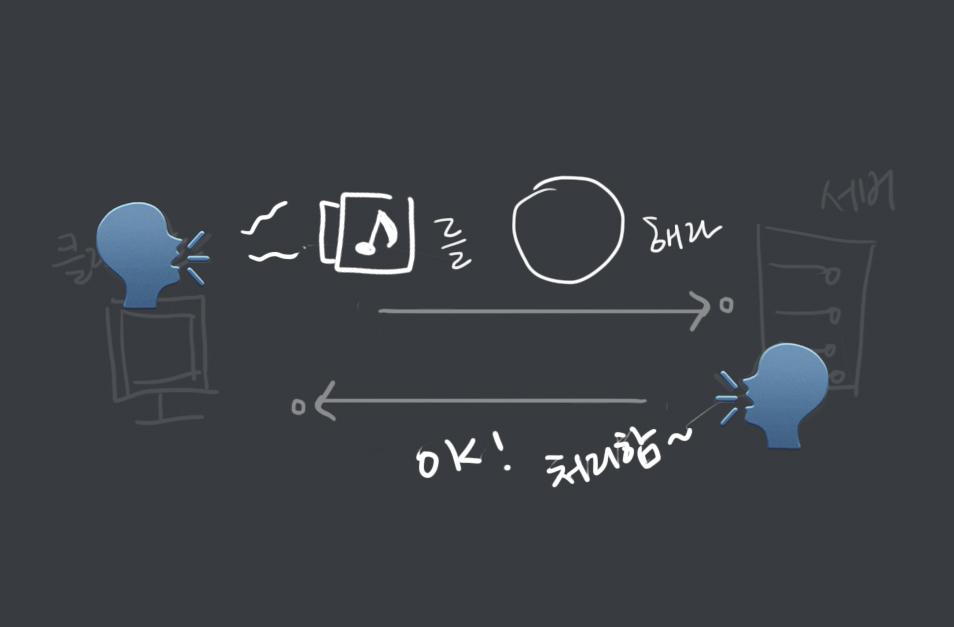
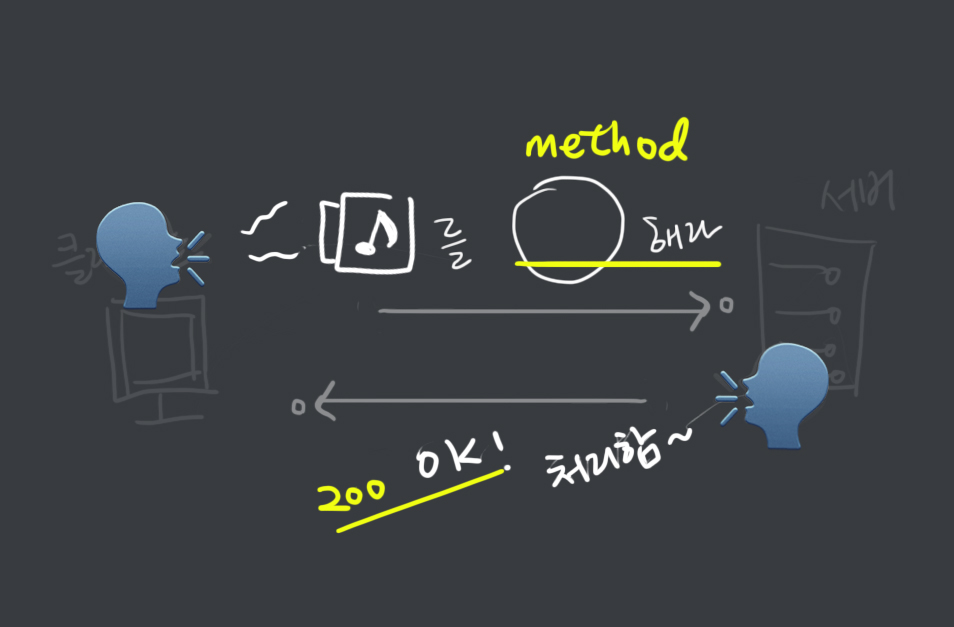
Container Logging
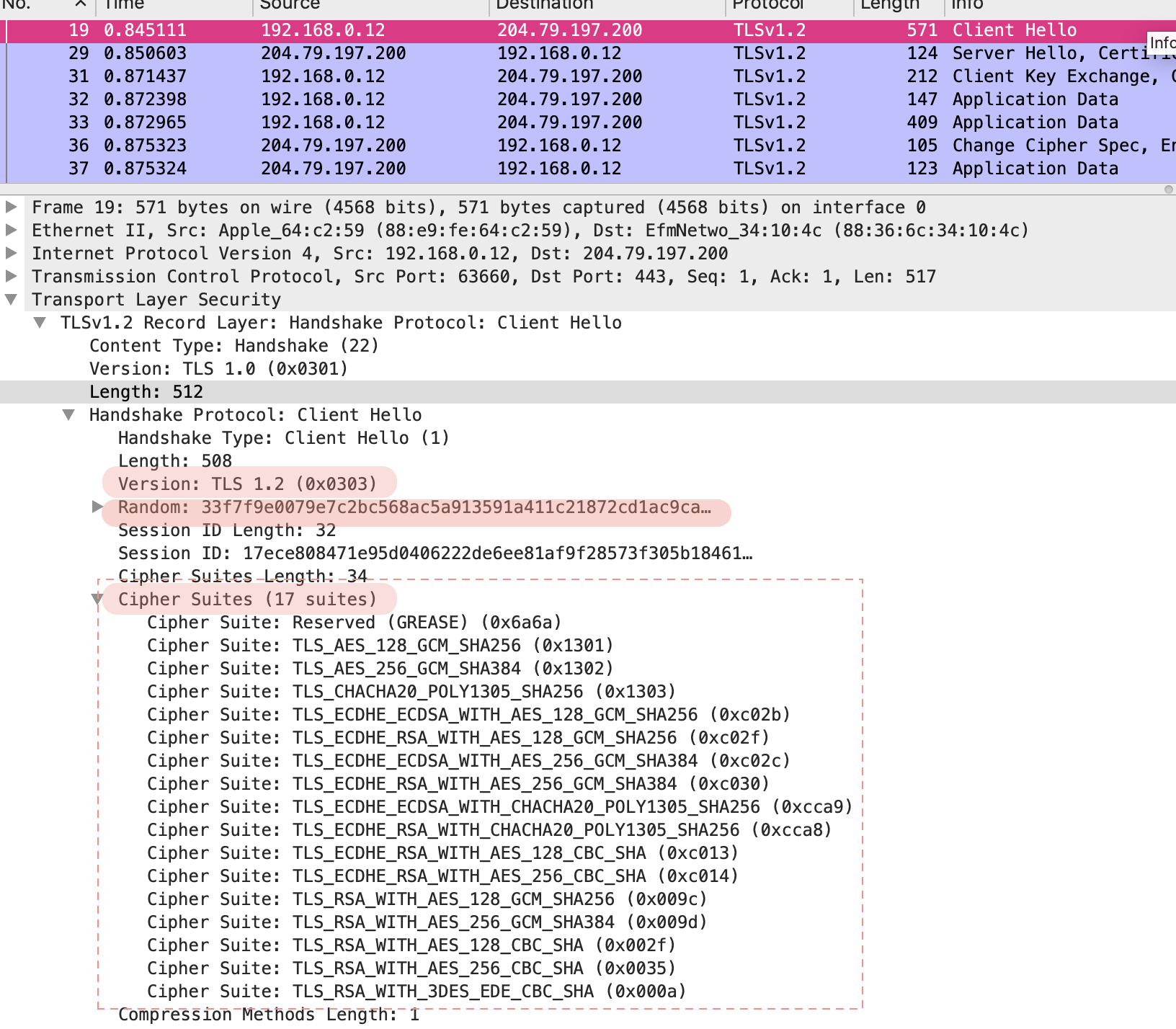
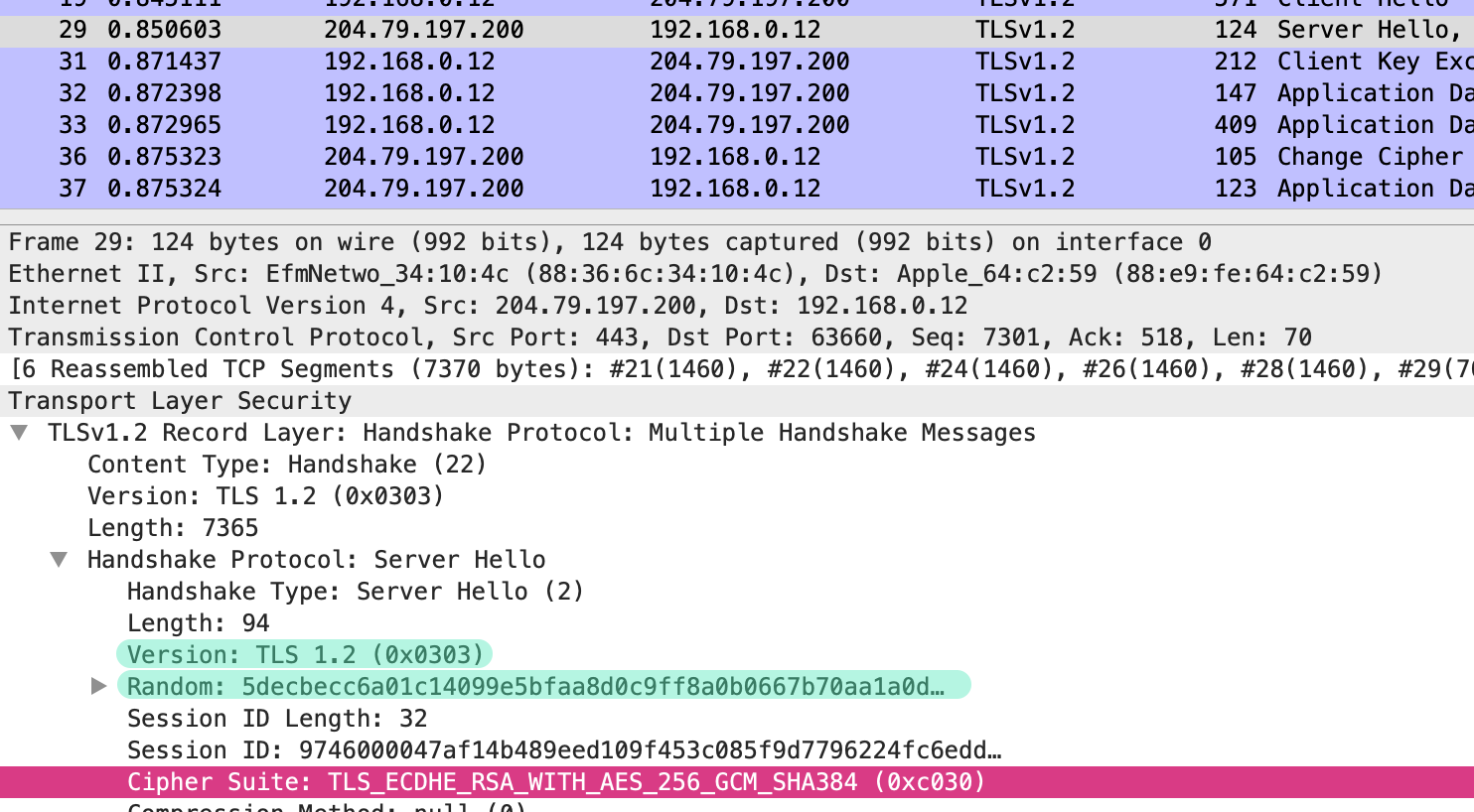
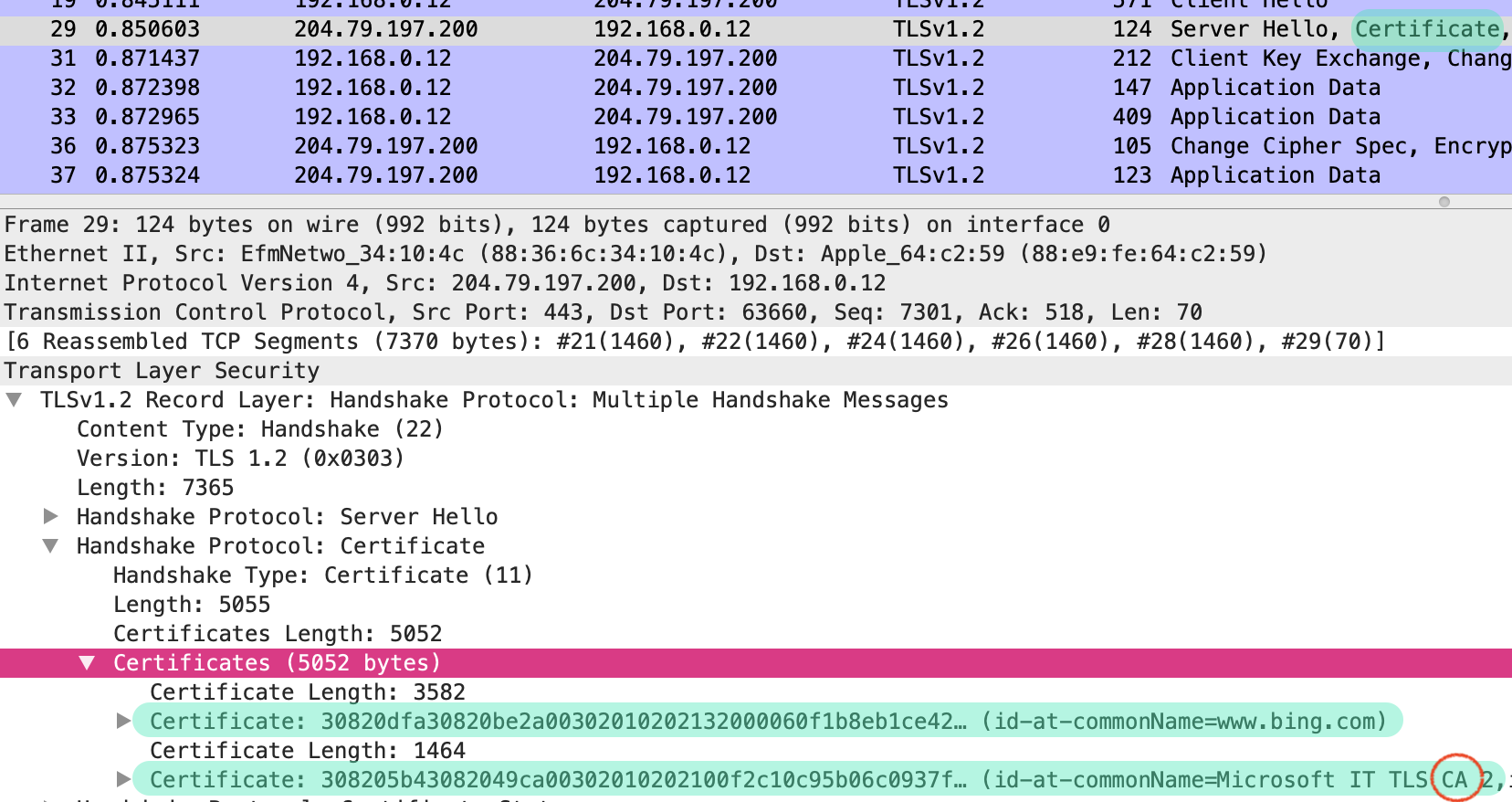
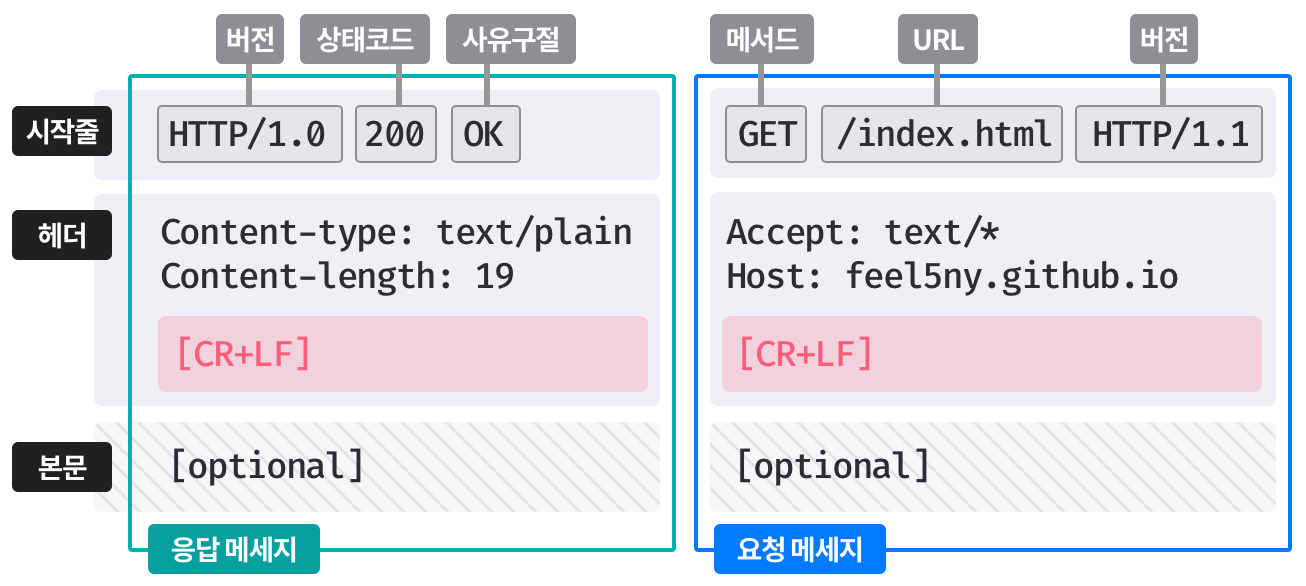
json-file 로그 사용하기
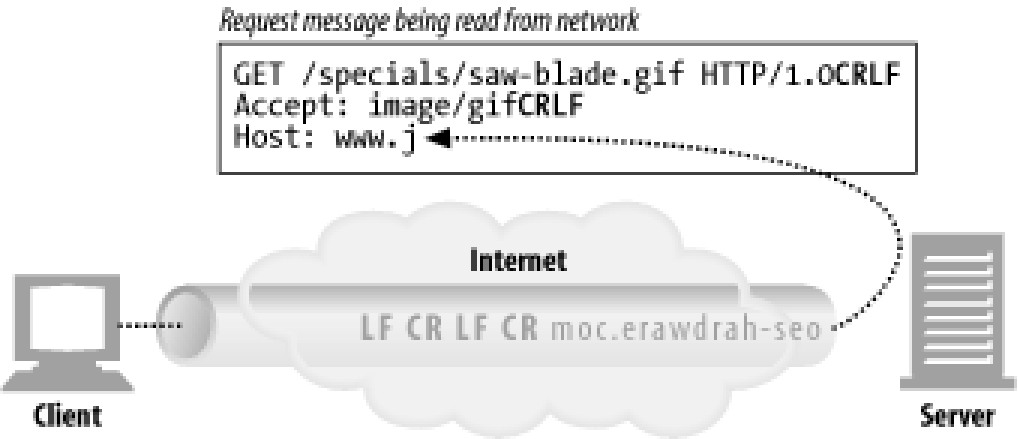
- 도커는 컨테이너의 표준 출력
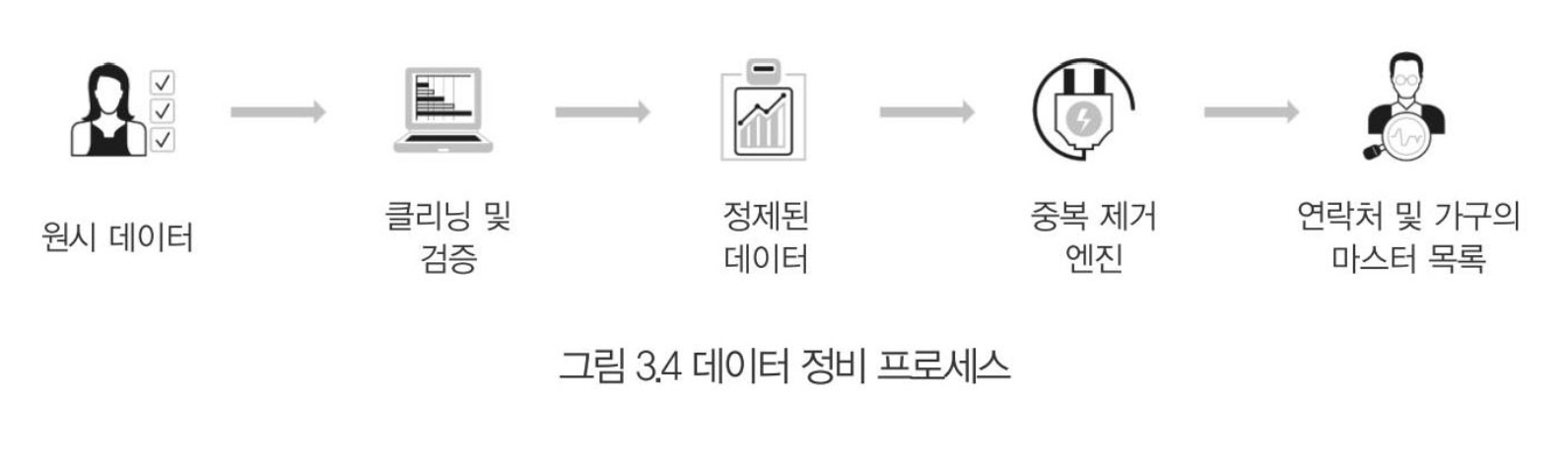
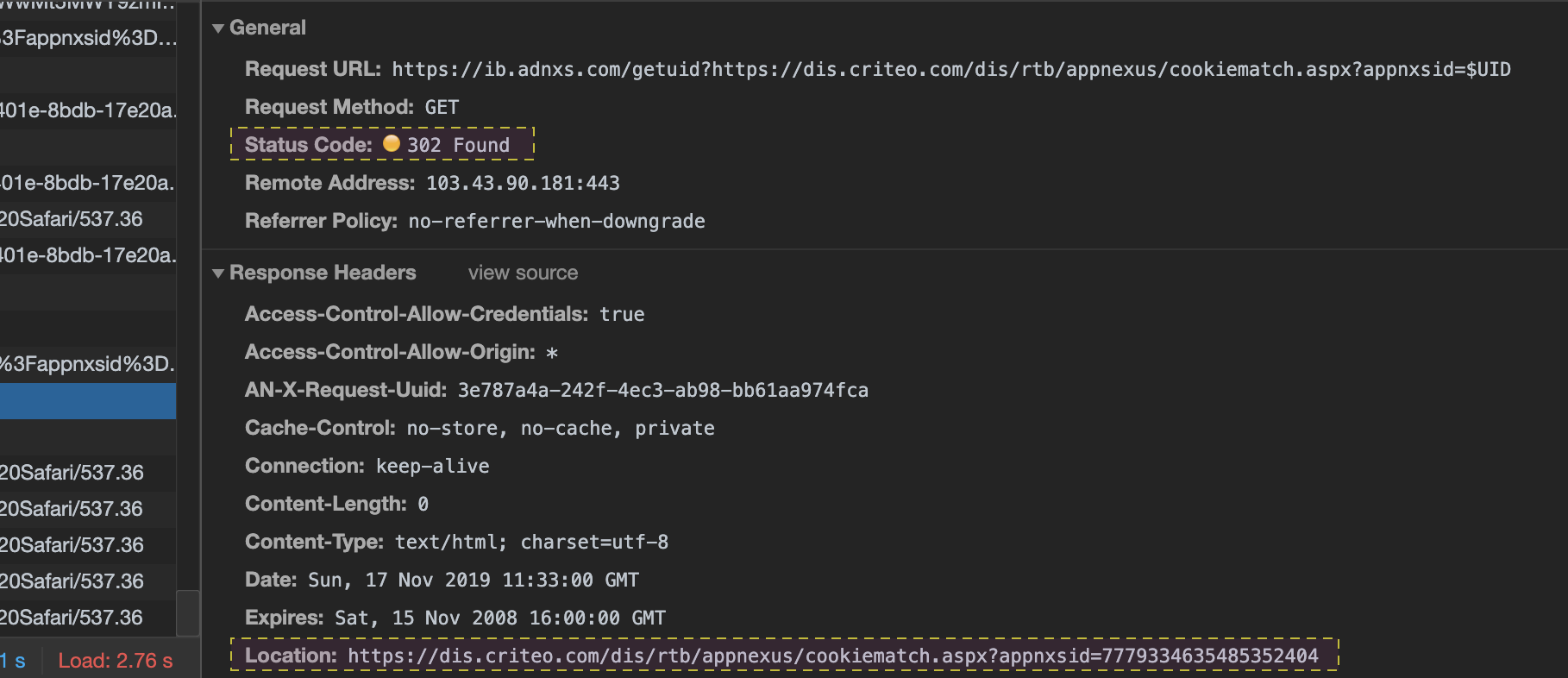
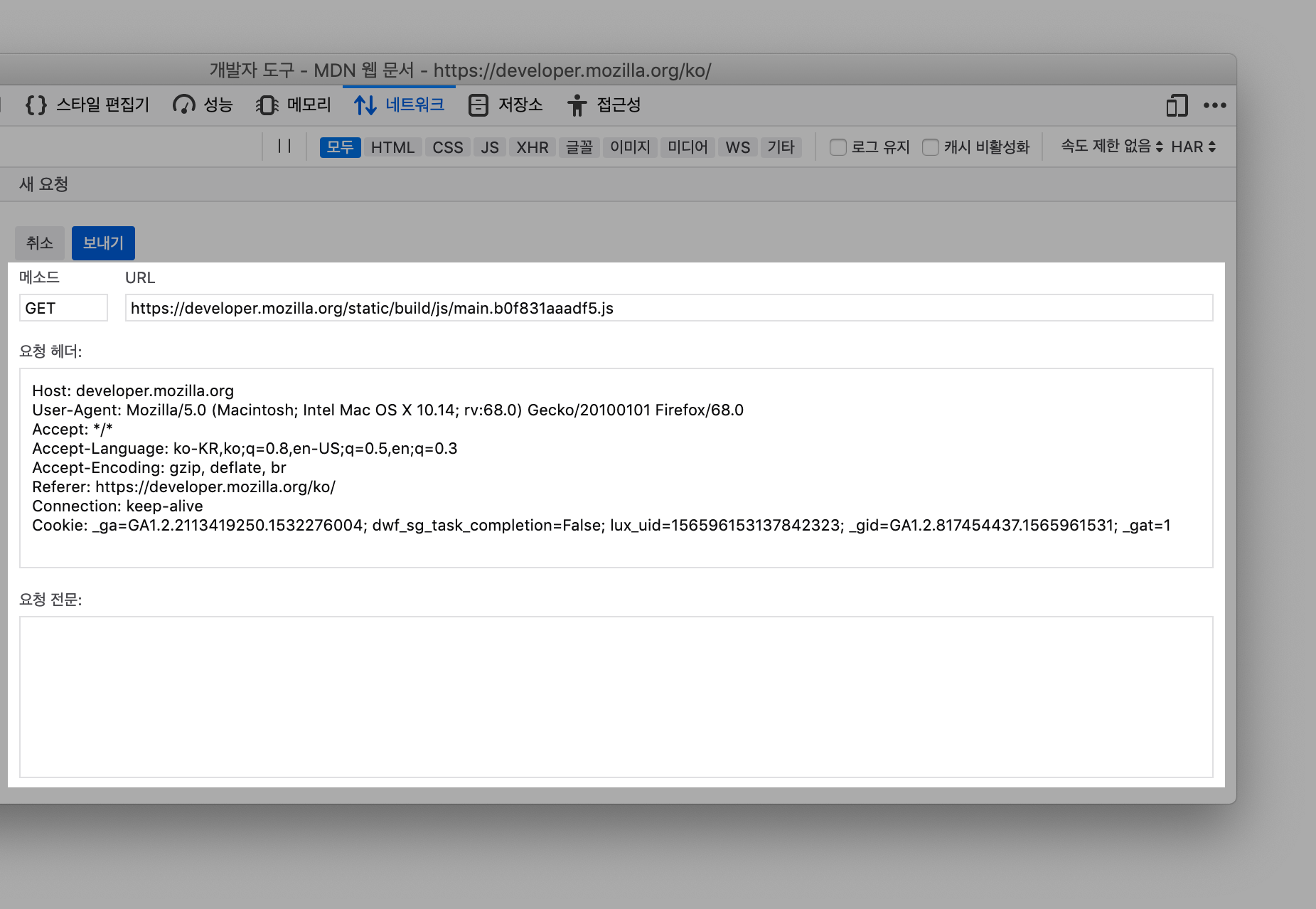
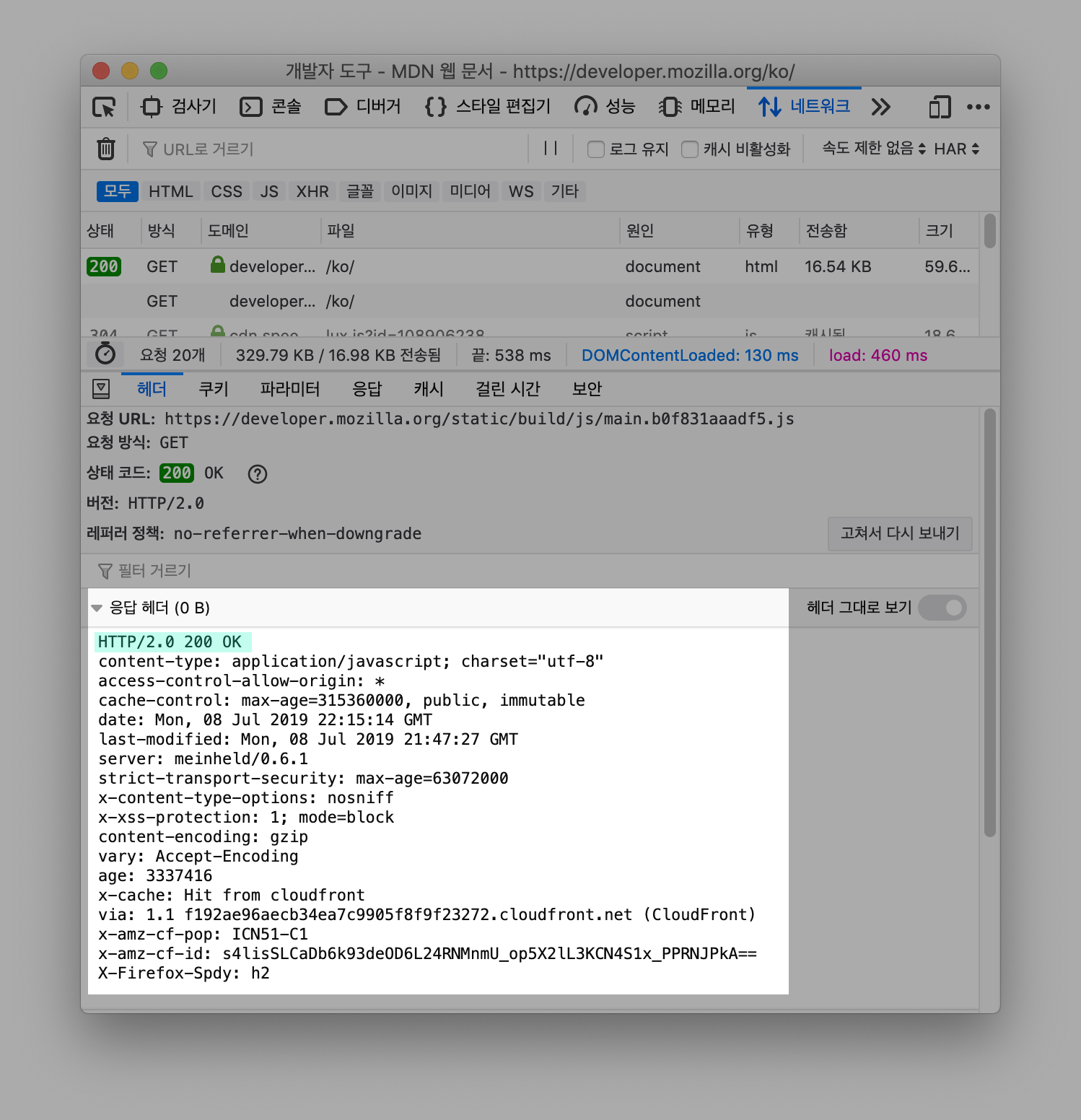
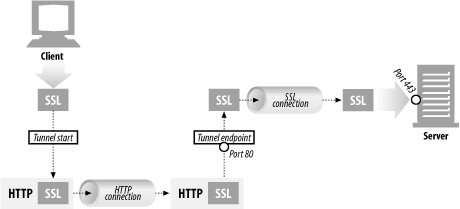
StdOut과 에러StdErr로그를 별도의 메타데이터 파일로 저장하며, 이를 확인하는 명령어를 제공한다. docker logs--since옵션에 유닉스 시간을 입력함. 특정시간 이후의 로그를 확인할 수 있다.
1 | docker logs --tail 2 mysql |
1 | docker logs -f -t mysql # 전체 출력 |
위와같은 컨테이너 로그는 JSON형태로 도커 내부저장
1 | cat /var/lib/docker/container/${CONTAINER_ID}/${CONTAINER_ID}-json.log |
json 파일 크기가 계속 커질 수 있어서, 호스트의 남은 공간도 전부 사용할수도 있음.
- 이를 방지하기 위해서 json 로그파일의 최대크기 지정할 수 있음.
- 로그 파일 최대 갯수도 지정가능
도커의 기본적인 로그뿐만아니라, 드라이버로도 로그 가능
- syslog
- jornald
- fluentd
- awslogs
1. syslog 로그
- 컨테이너 로그는 JSON뿐만아니라, syslog로 보내 저장하도록 설정가능
- syslog: 유닉스 계역 운영체제에서 로그를 수집하는 오래된 표준 중 하나.
- 커널, 보안 등 시스템과 관련된 로그,
다양한 종류의 로그를 수집해 저장.
2. fluentd 로그
- 오픈소스 도구
- 컨테이너 로그를 fluentd를 통해 저장할 수 있도록 플러그인 공식제공
- 수집된 데이터를 aws s3, hdfs(hadoop distributed file system), mongoDB등 다양한 저장소에 저장할 수 있다.
3. 아마존 클라우드워치 로그
- 도커를 aws ec3에서 사용하고 있다면, 다른 도구 별도 설치없이 컨테이너에서 드라이버 옵션을 설정하여, 클라우드워치 로깅 드라이버 사용가능
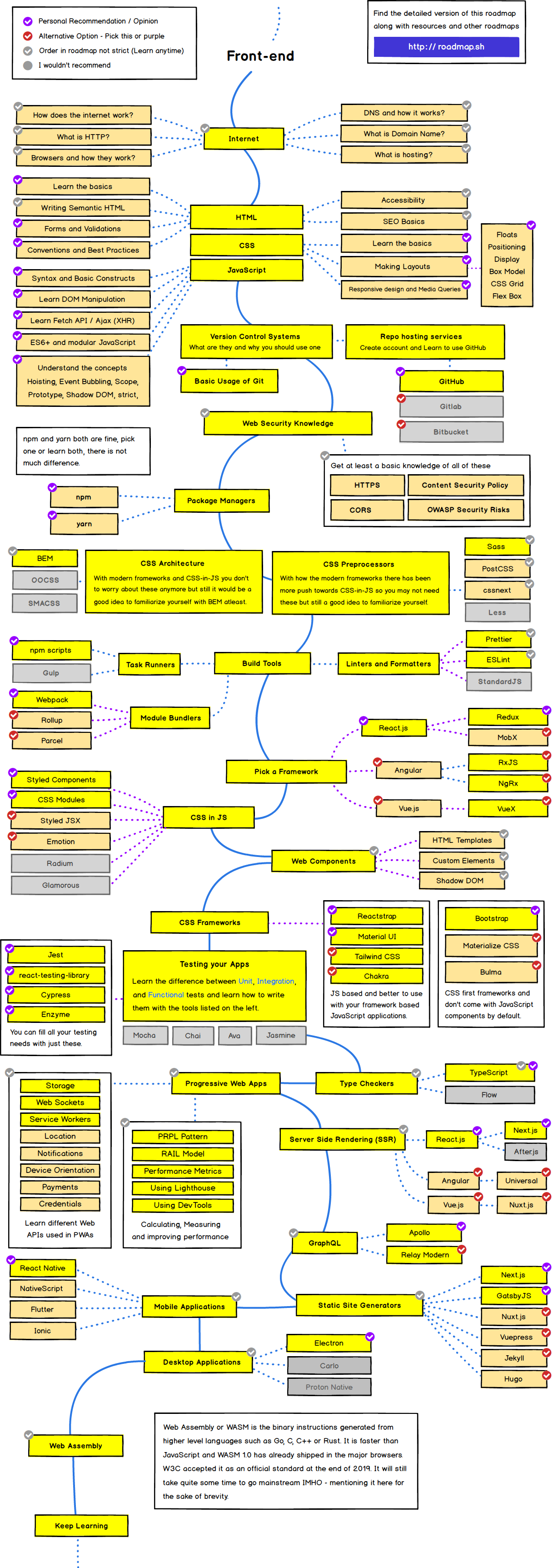
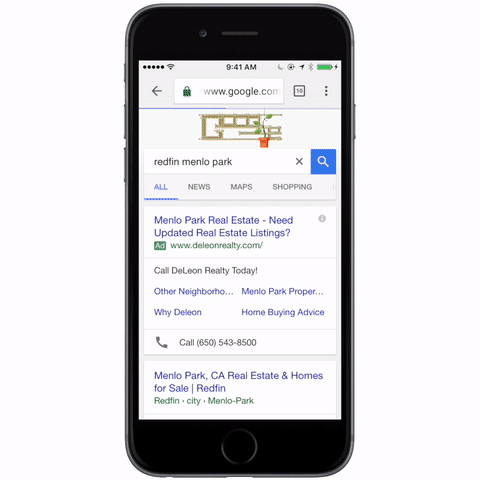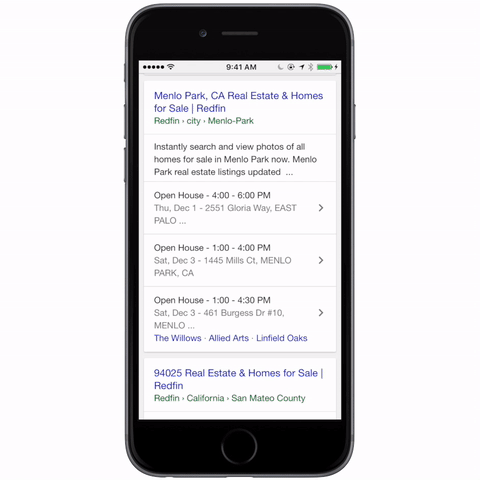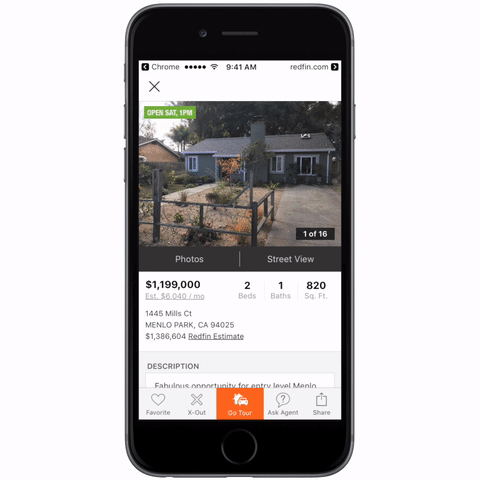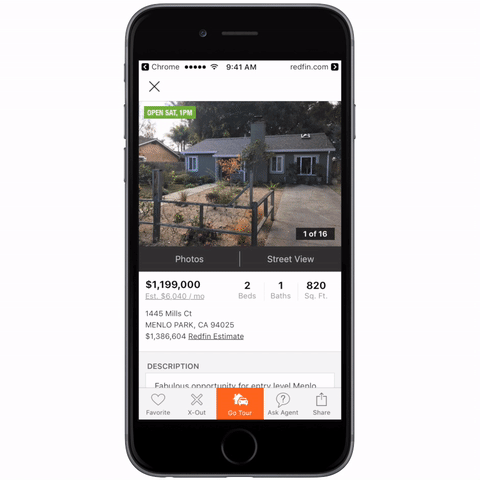
도커 환경으로 구성된 인프라들을 최근들어 자주 접하게 되고, 프론트 리소스도 도커, 쿠버네티스 환경에서 운영됨에 따라, 프론트 개발자도 이에 대한 지식이 필요하다고 느껴 스터디를 진행합니다. 스터디는 “시작하세요 도커/쿠버네티스” 책으로 진행합니다.




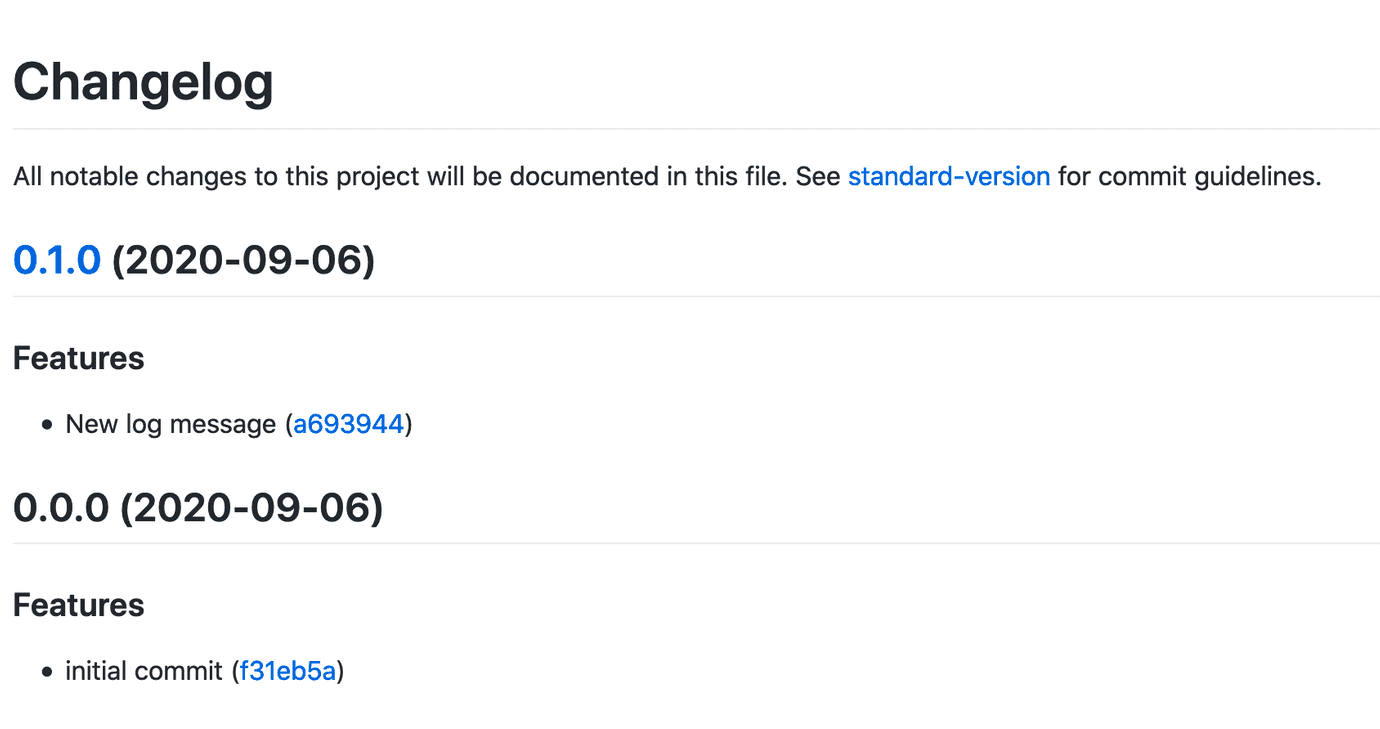











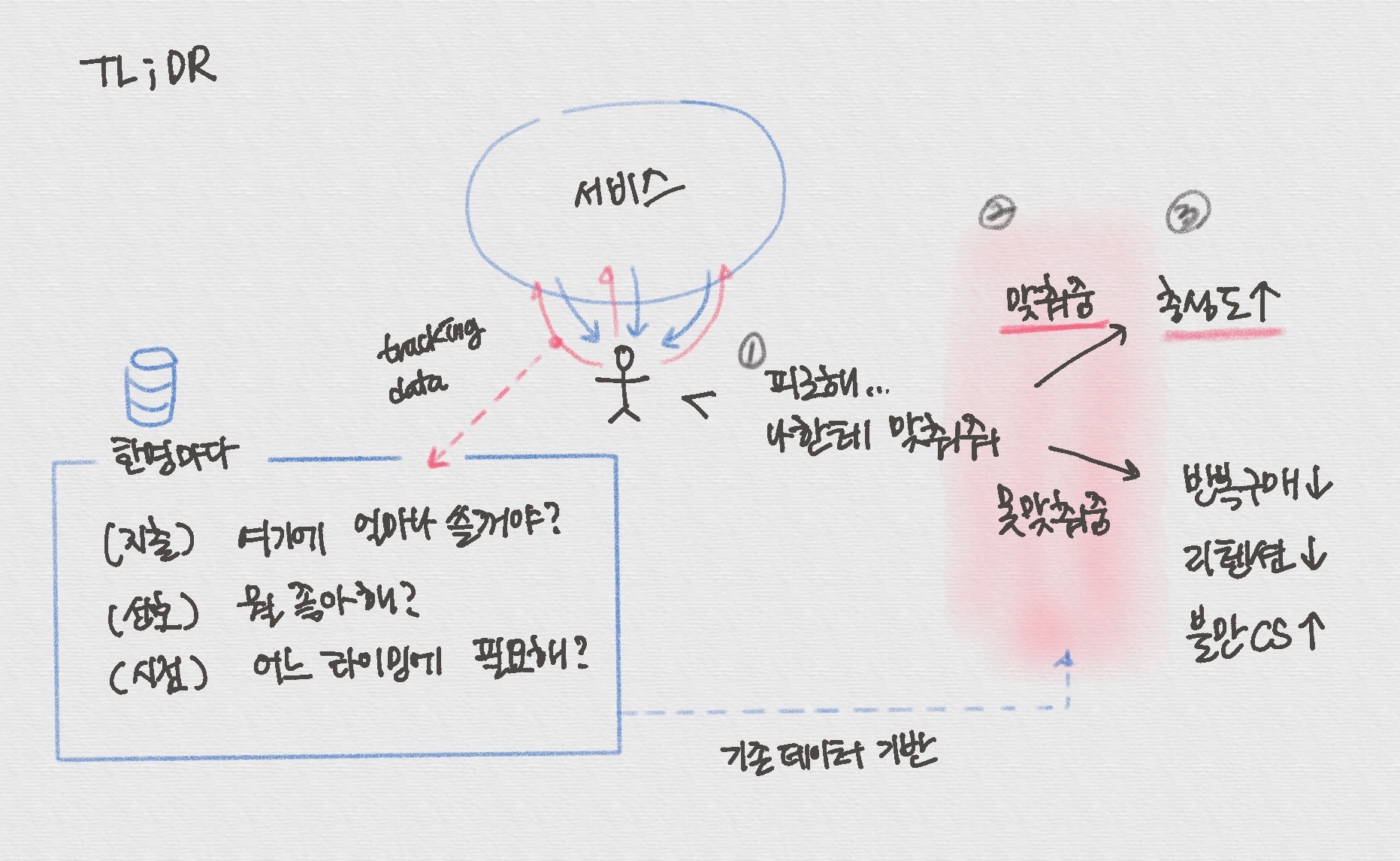
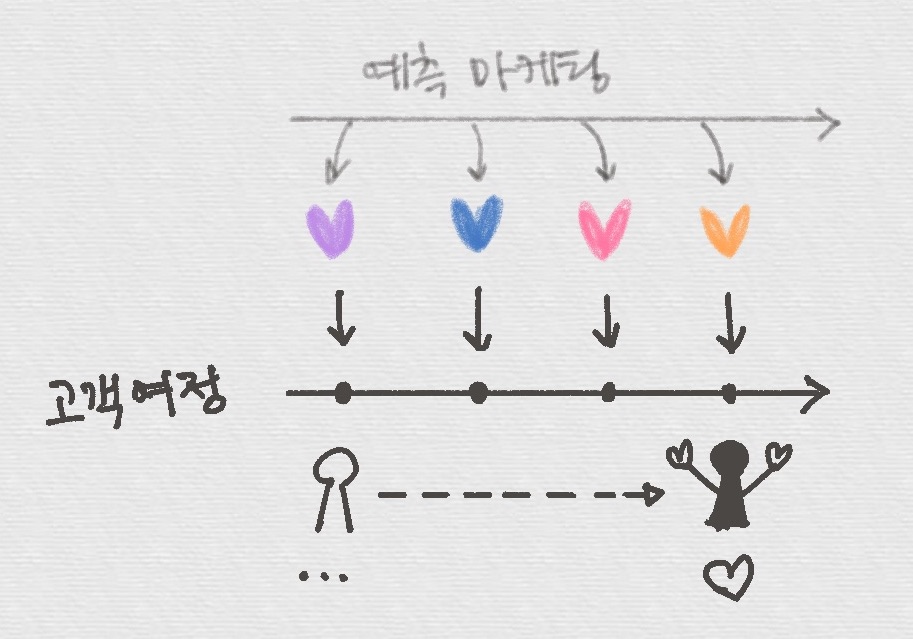
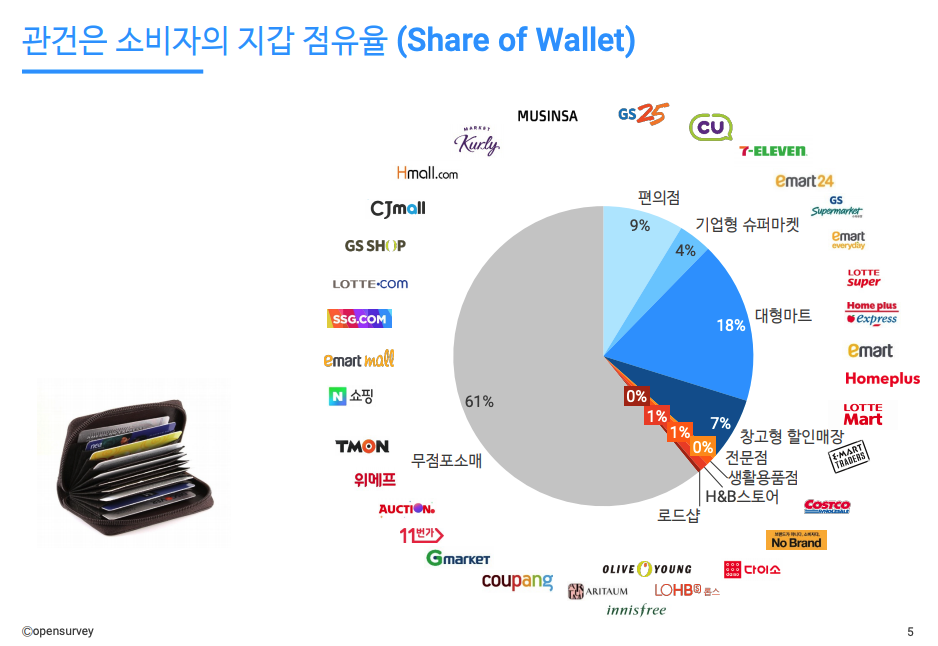

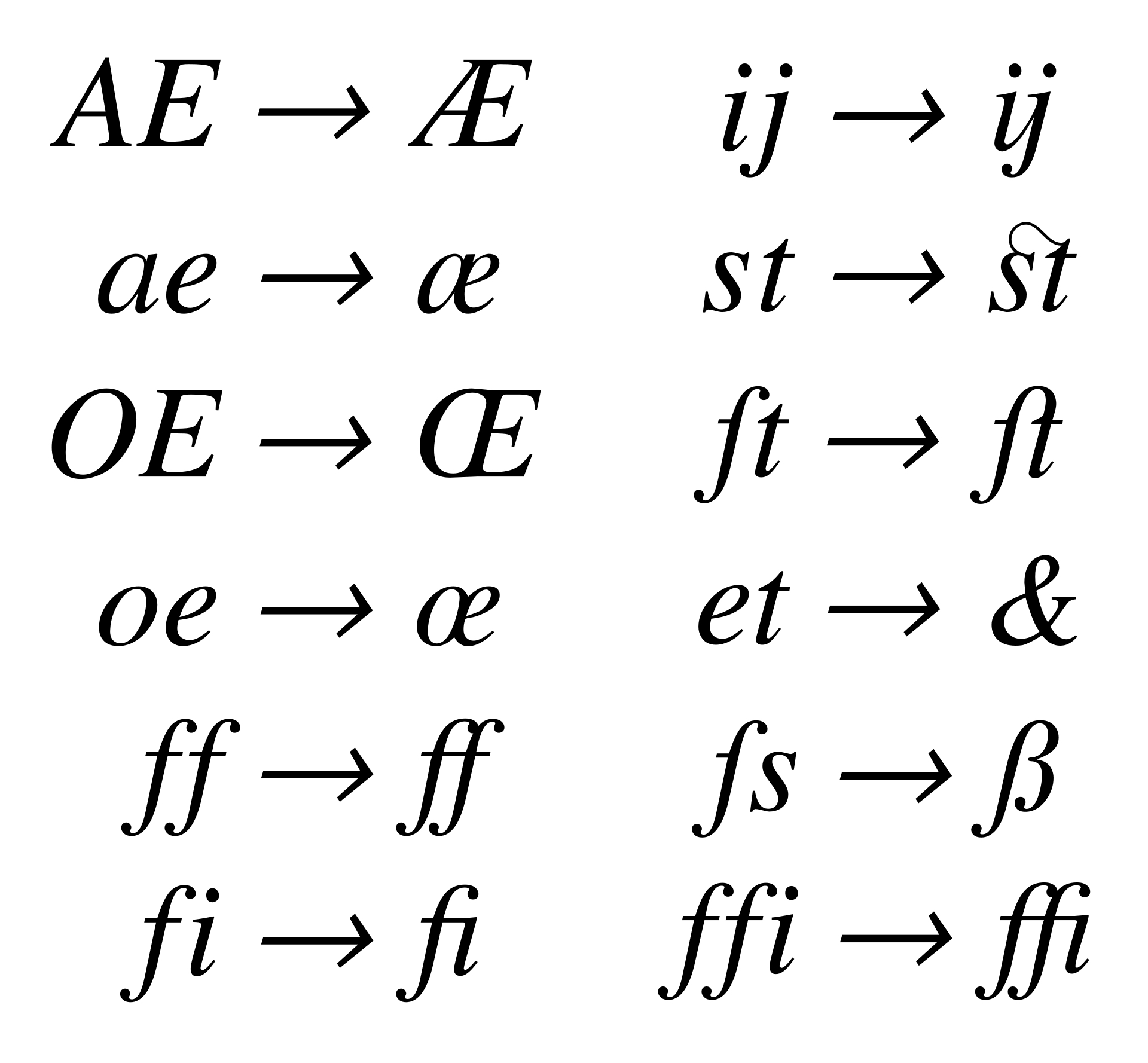

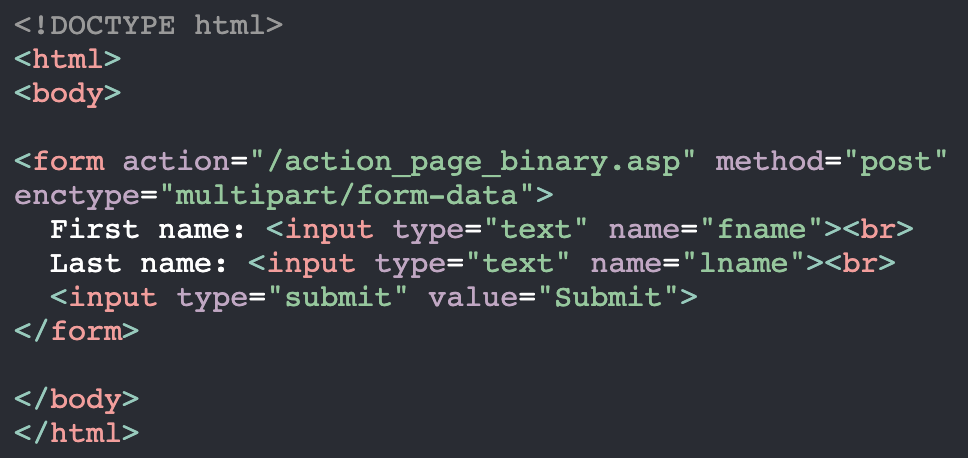
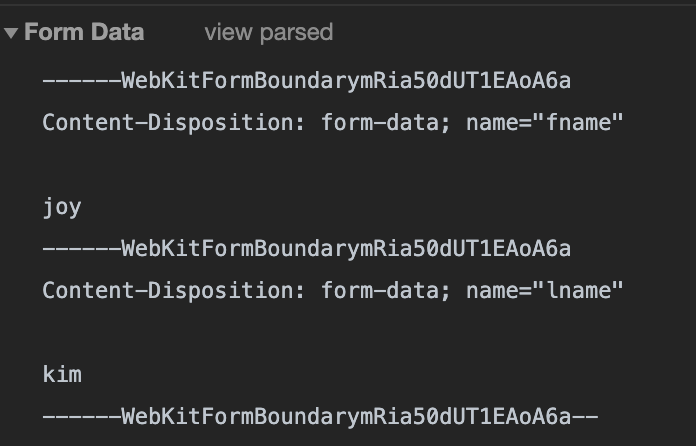
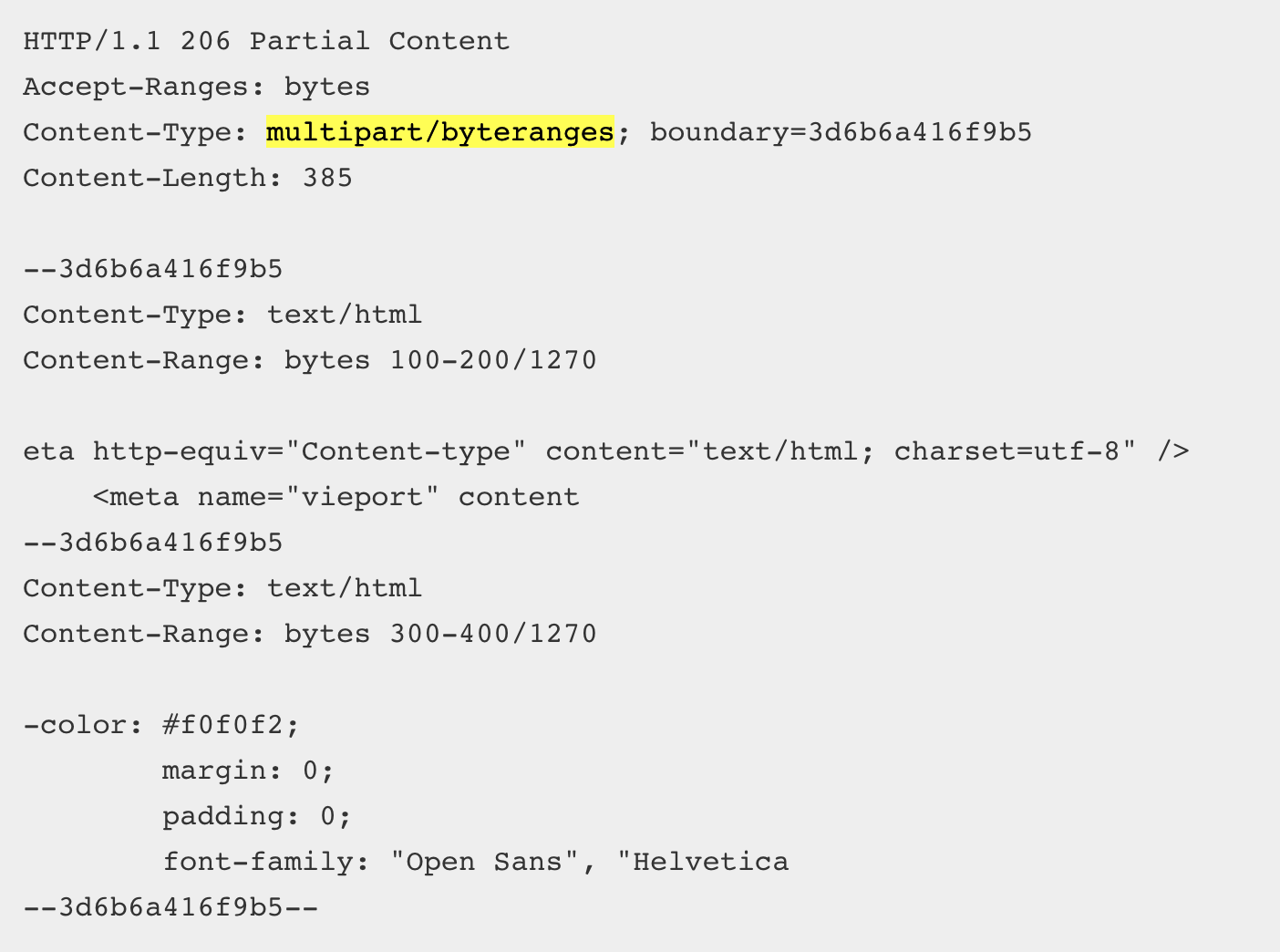














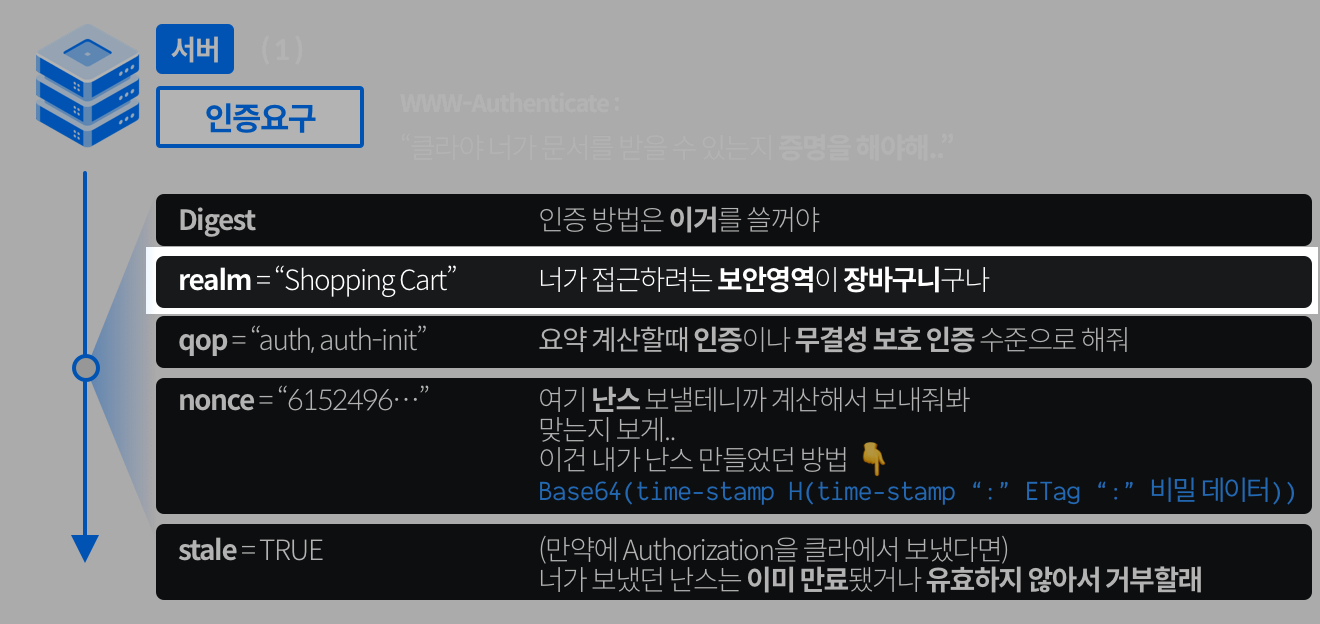
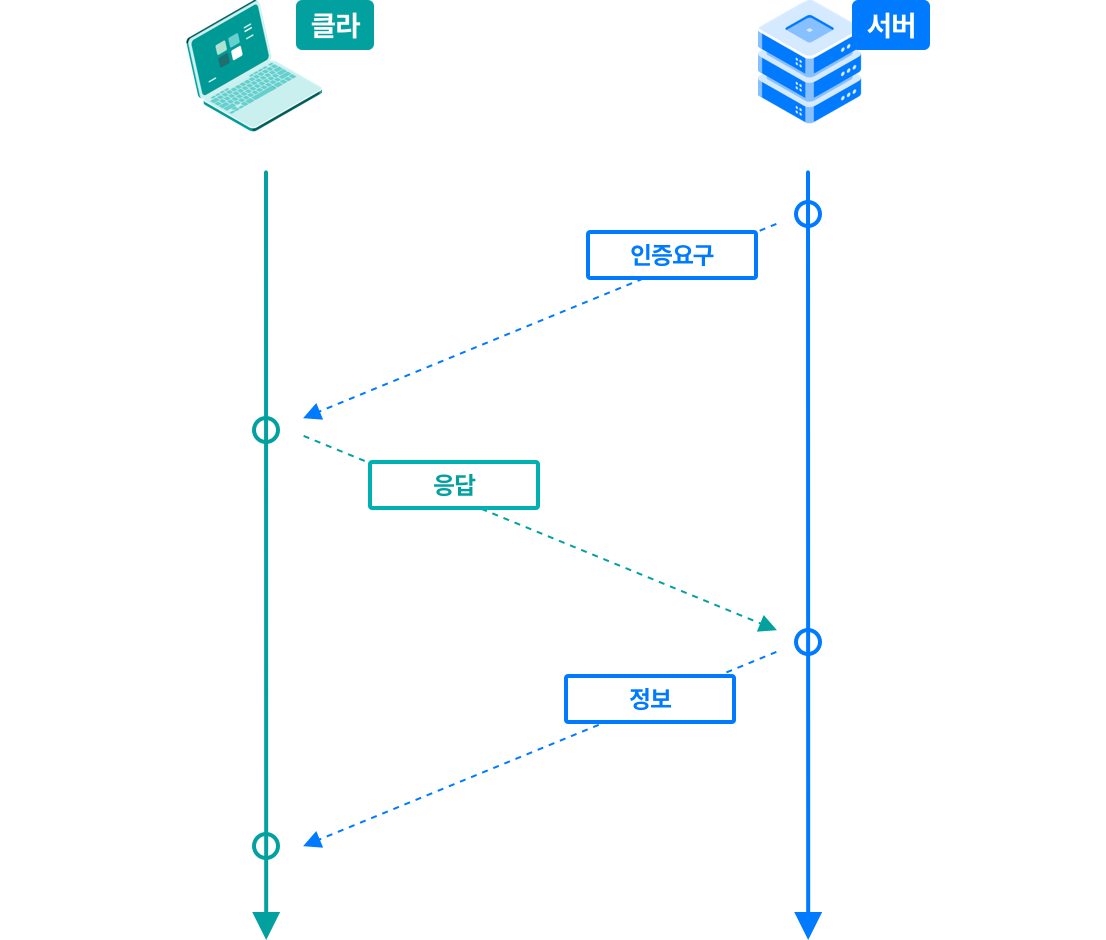

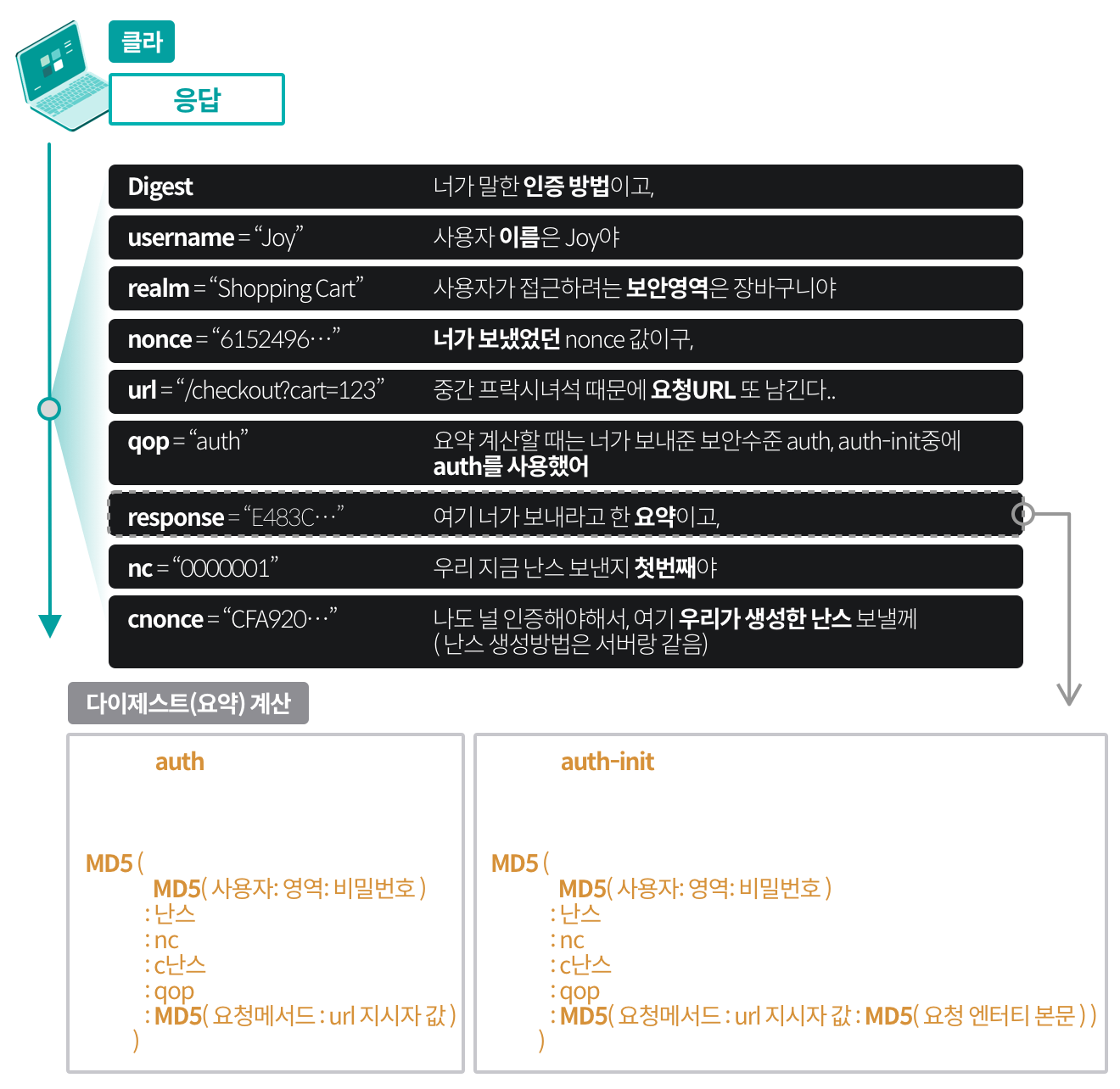
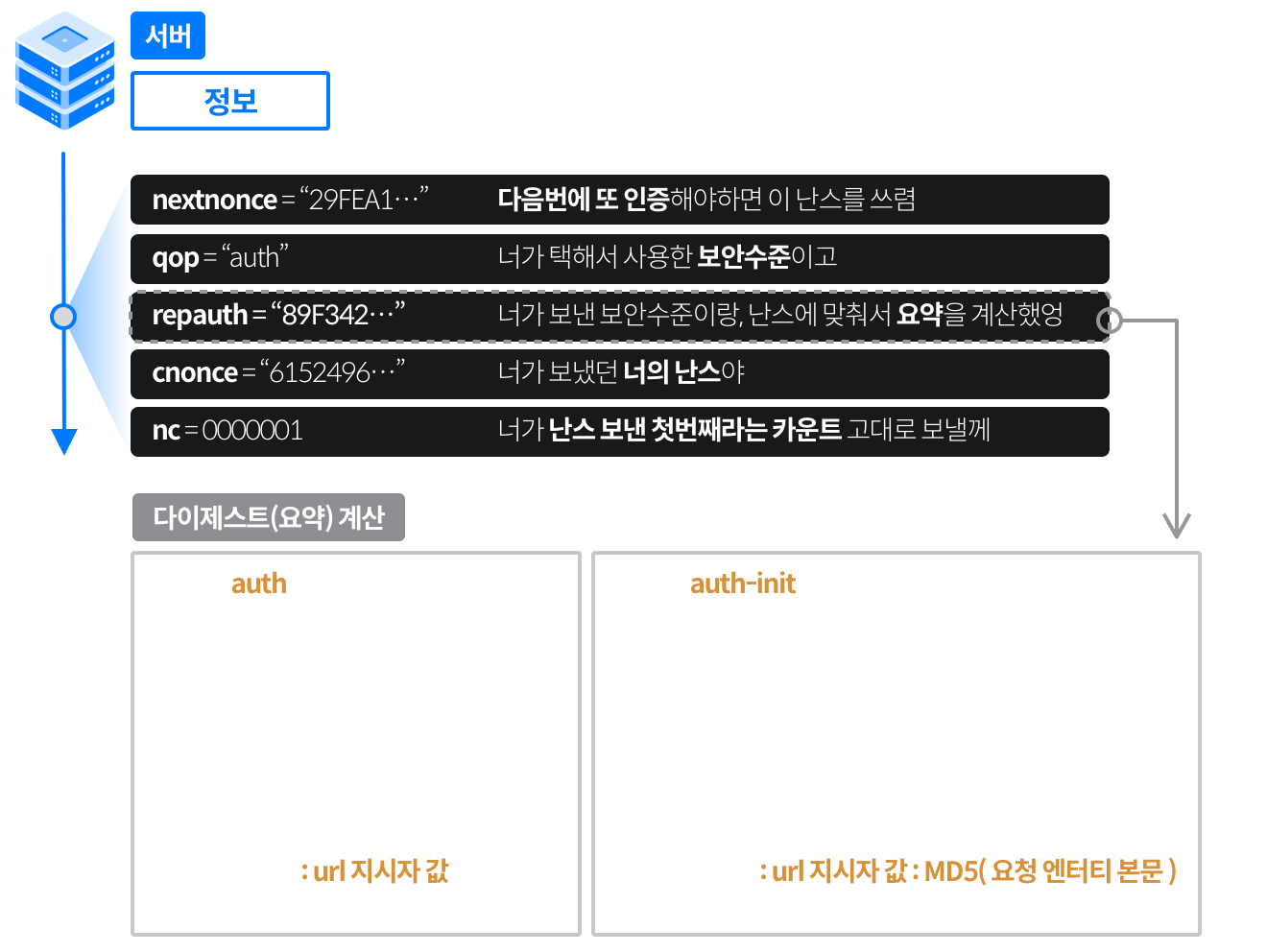
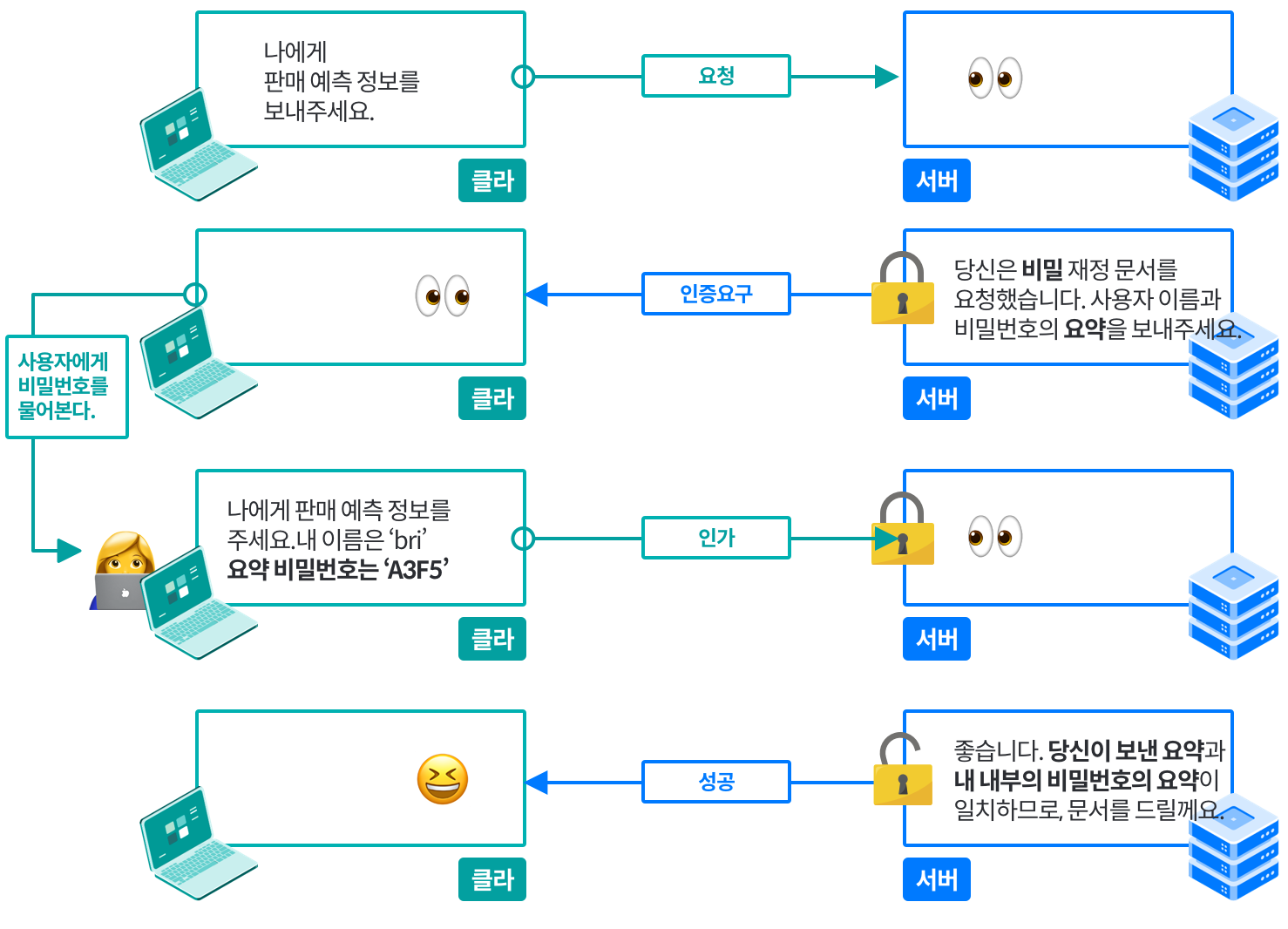
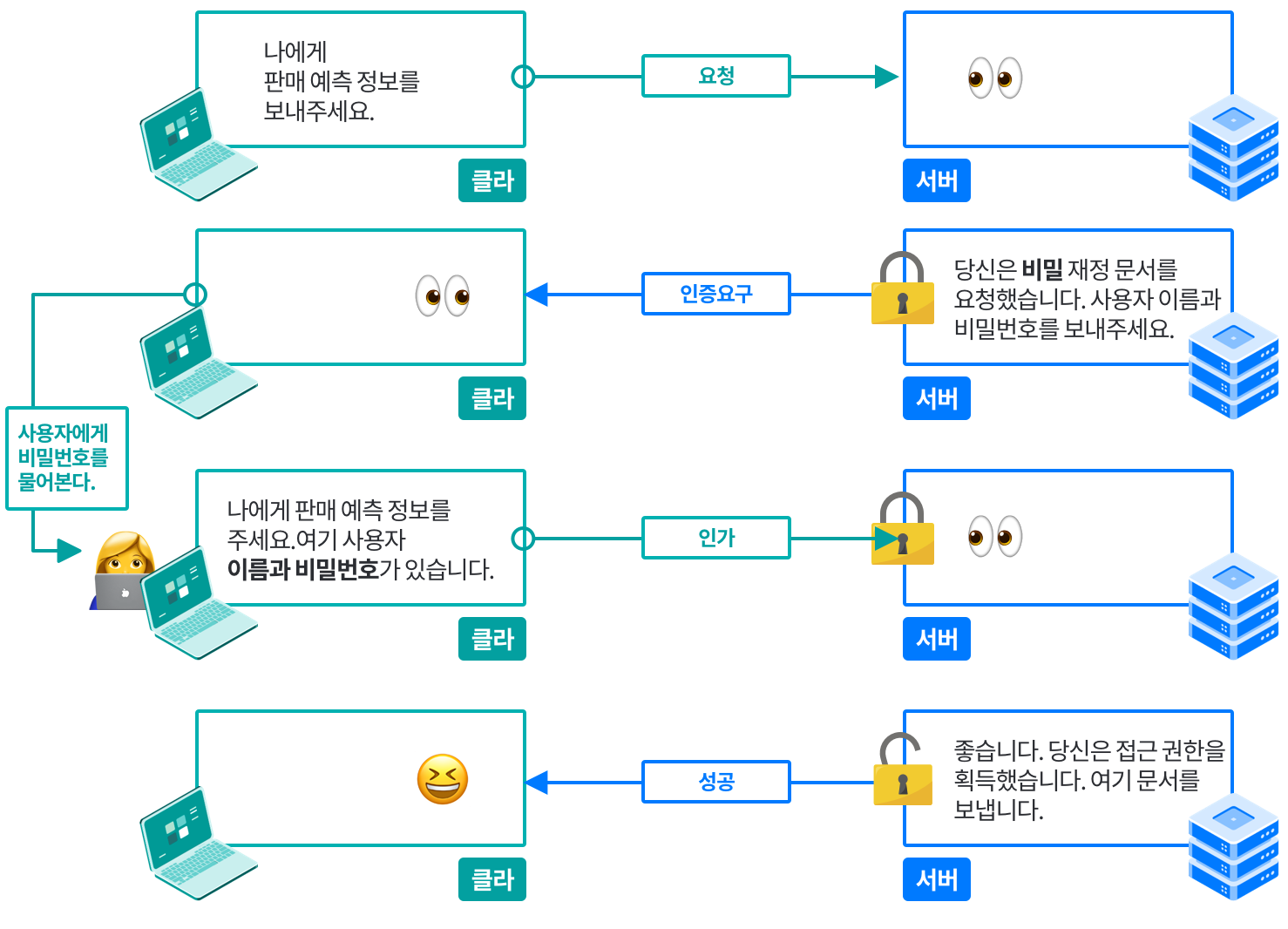






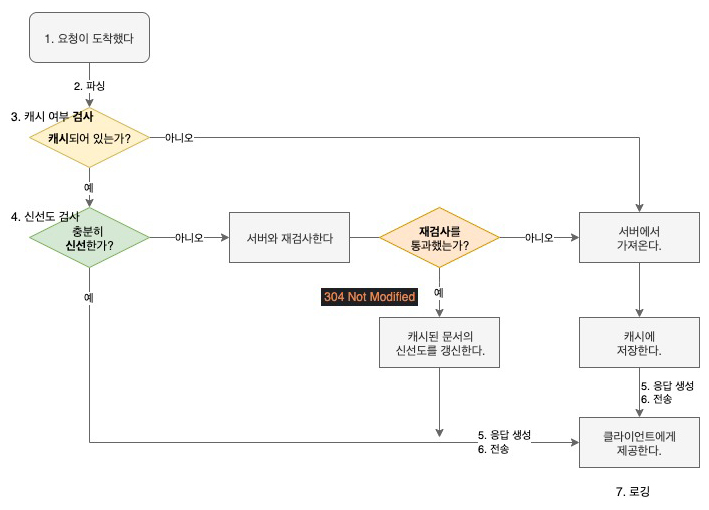
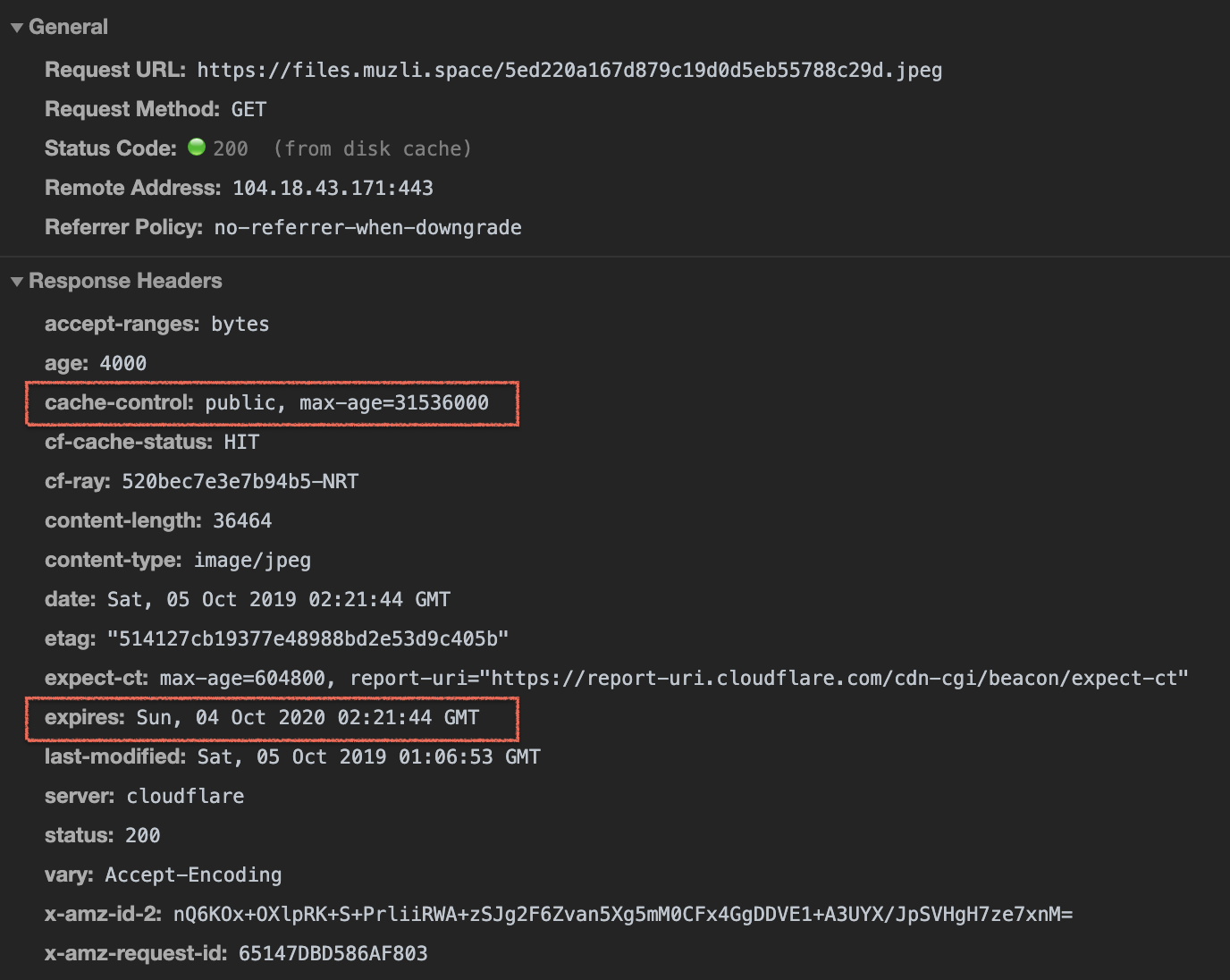
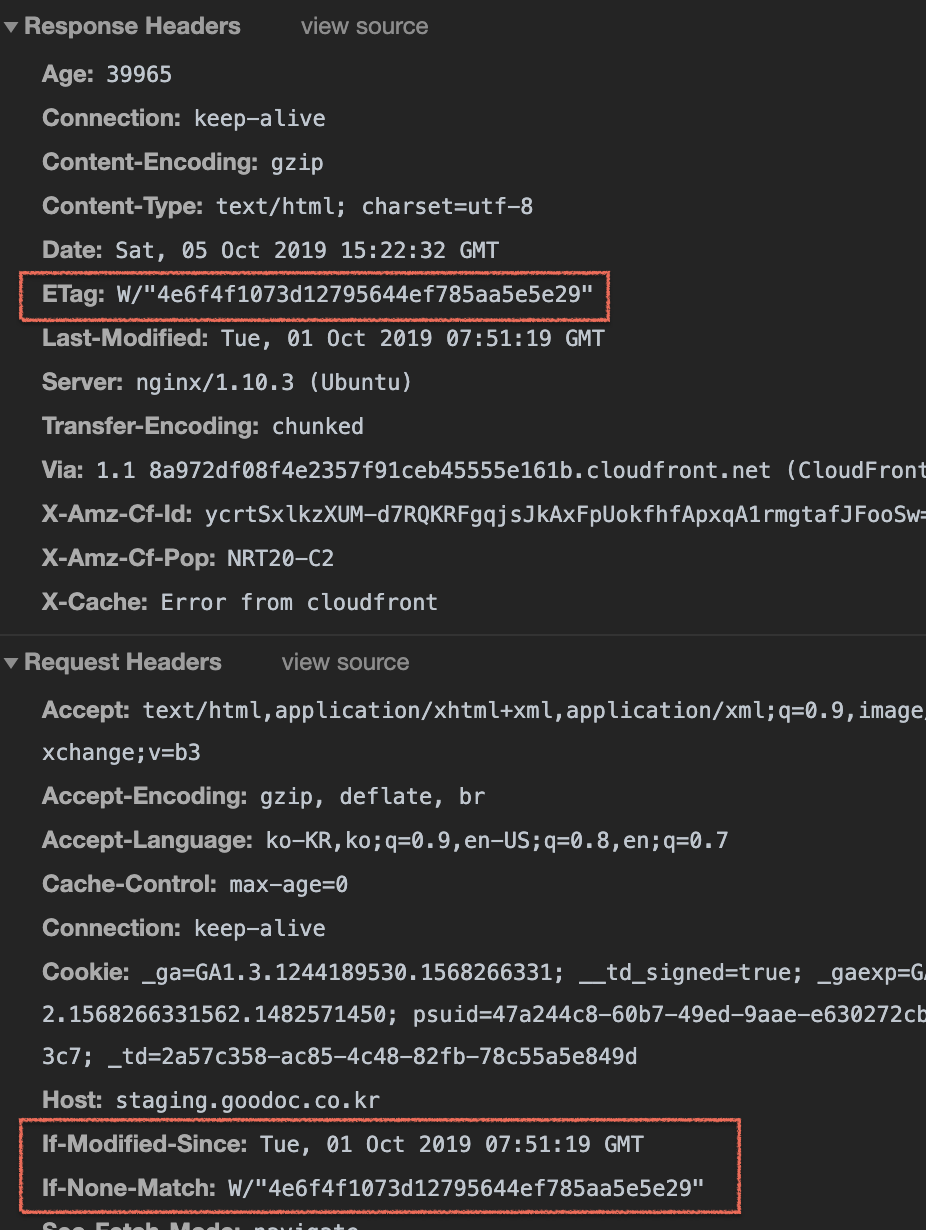
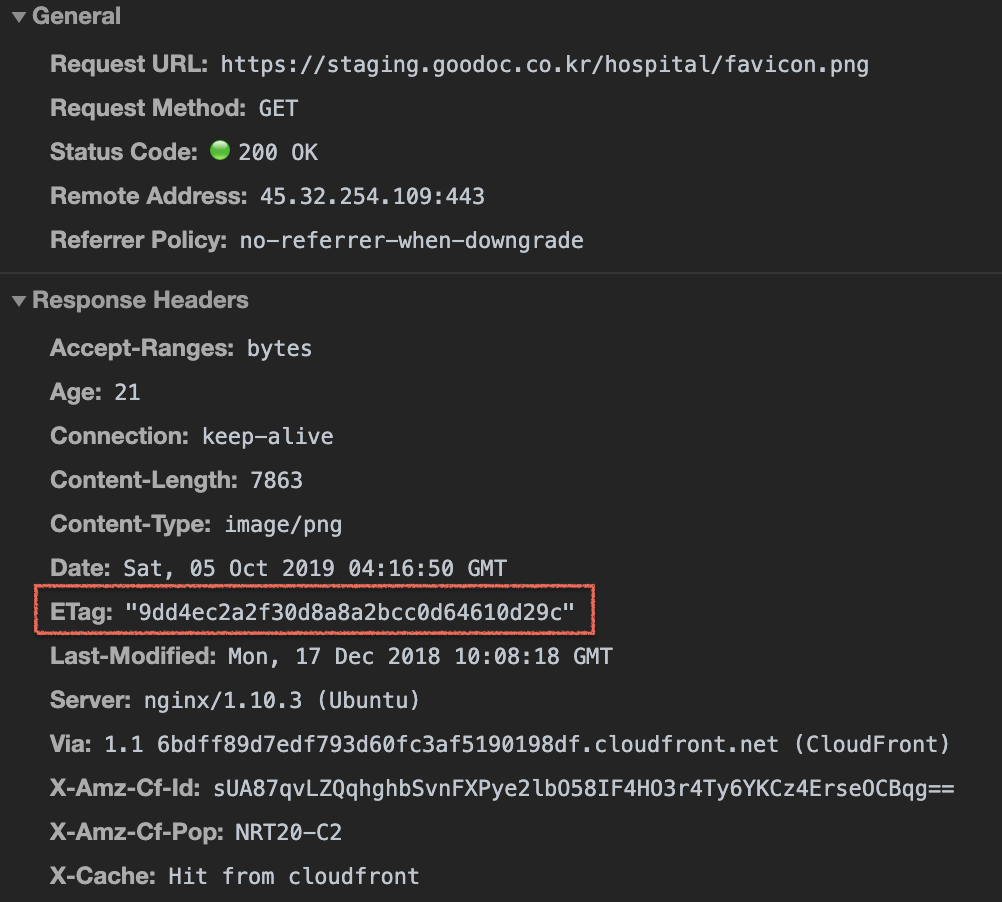
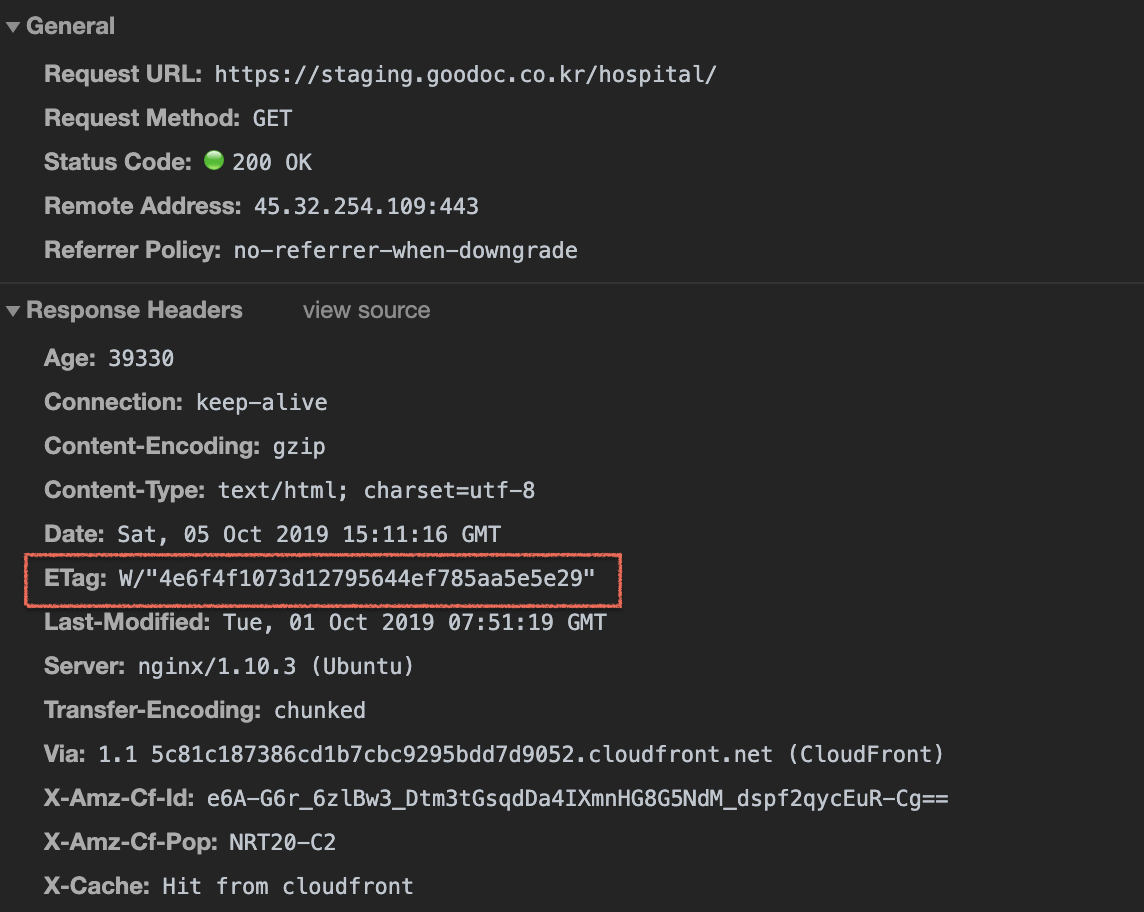
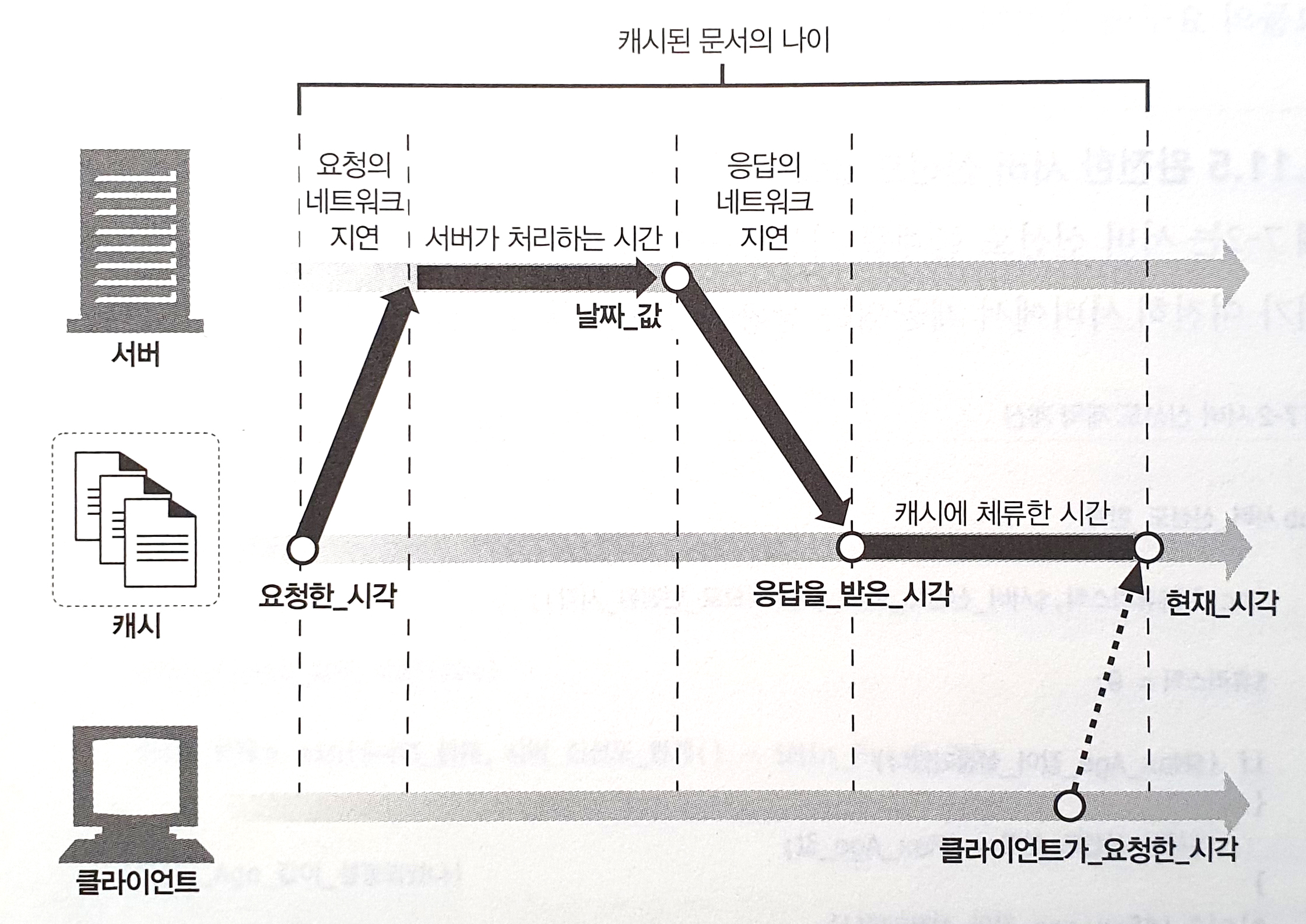
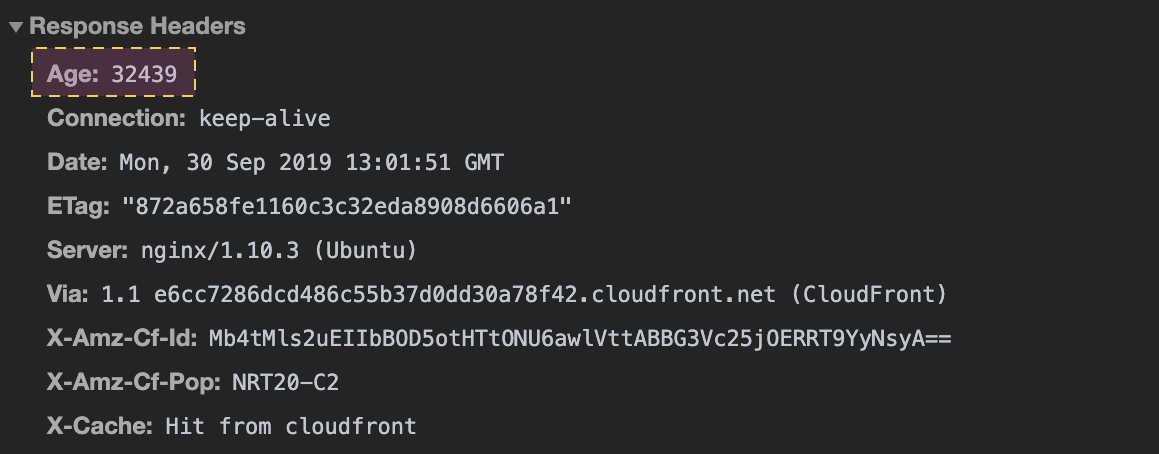
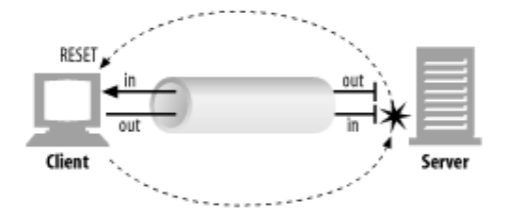
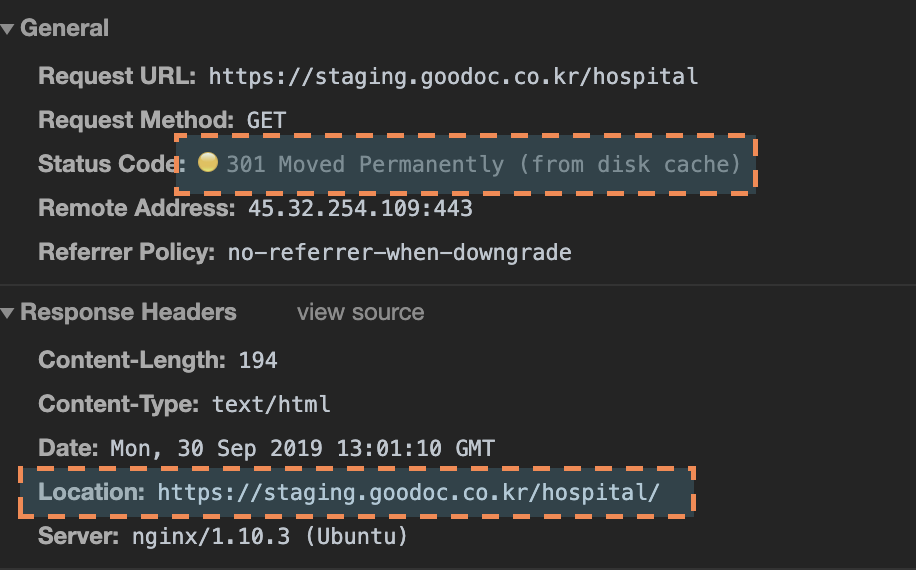
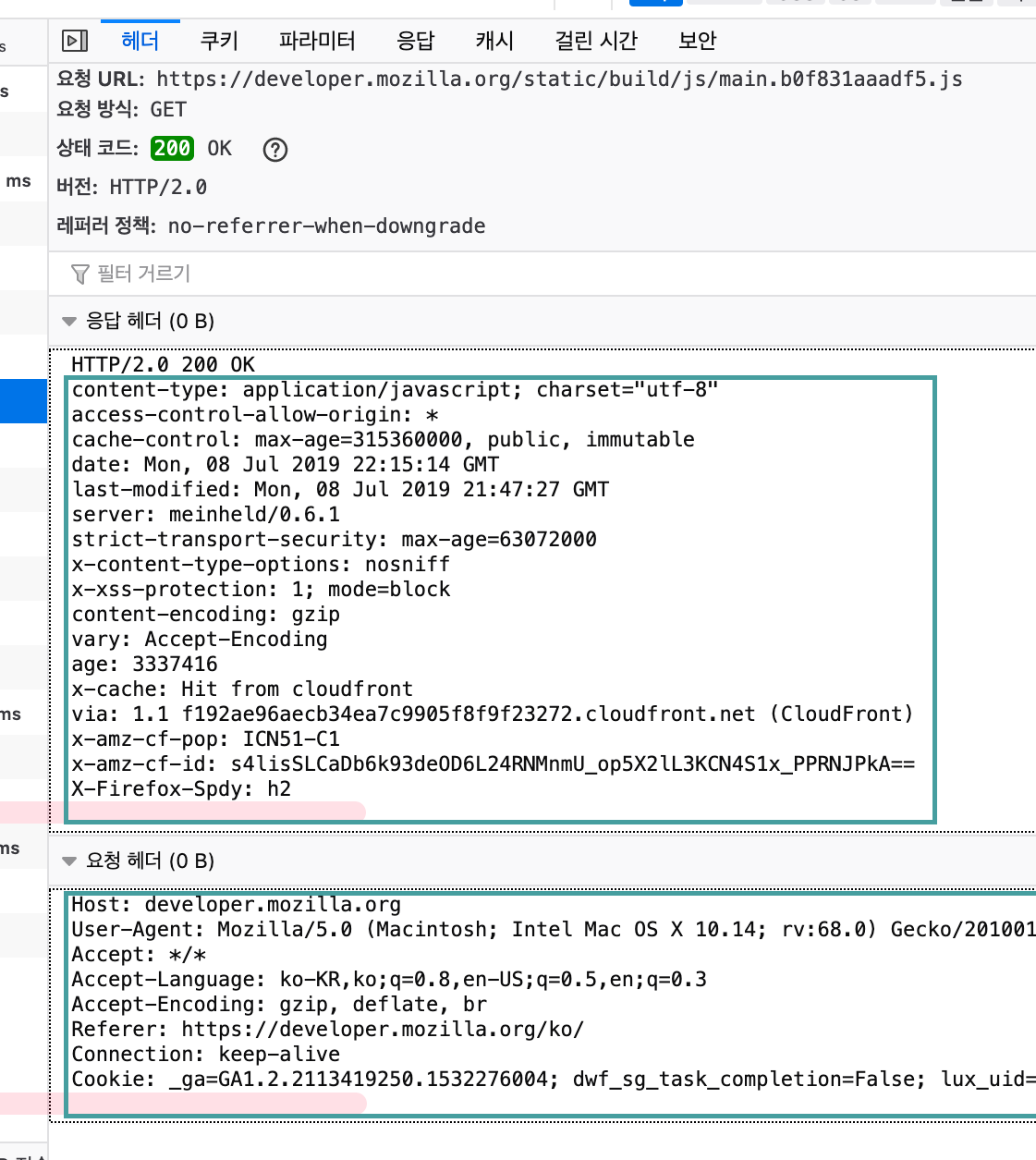
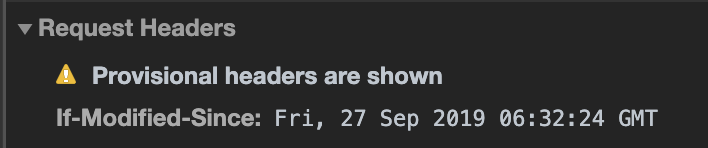 > 오늘은 9월 30일이다. 27일에 캐시되어있던 파일이며, 해당 시간 이후의 사본의 신선도를 확인한다.
> 오늘은 9월 30일이다. 27일에 캐시되어있던 파일이며, 해당 시간 이후의 사본의 신선도를 확인한다.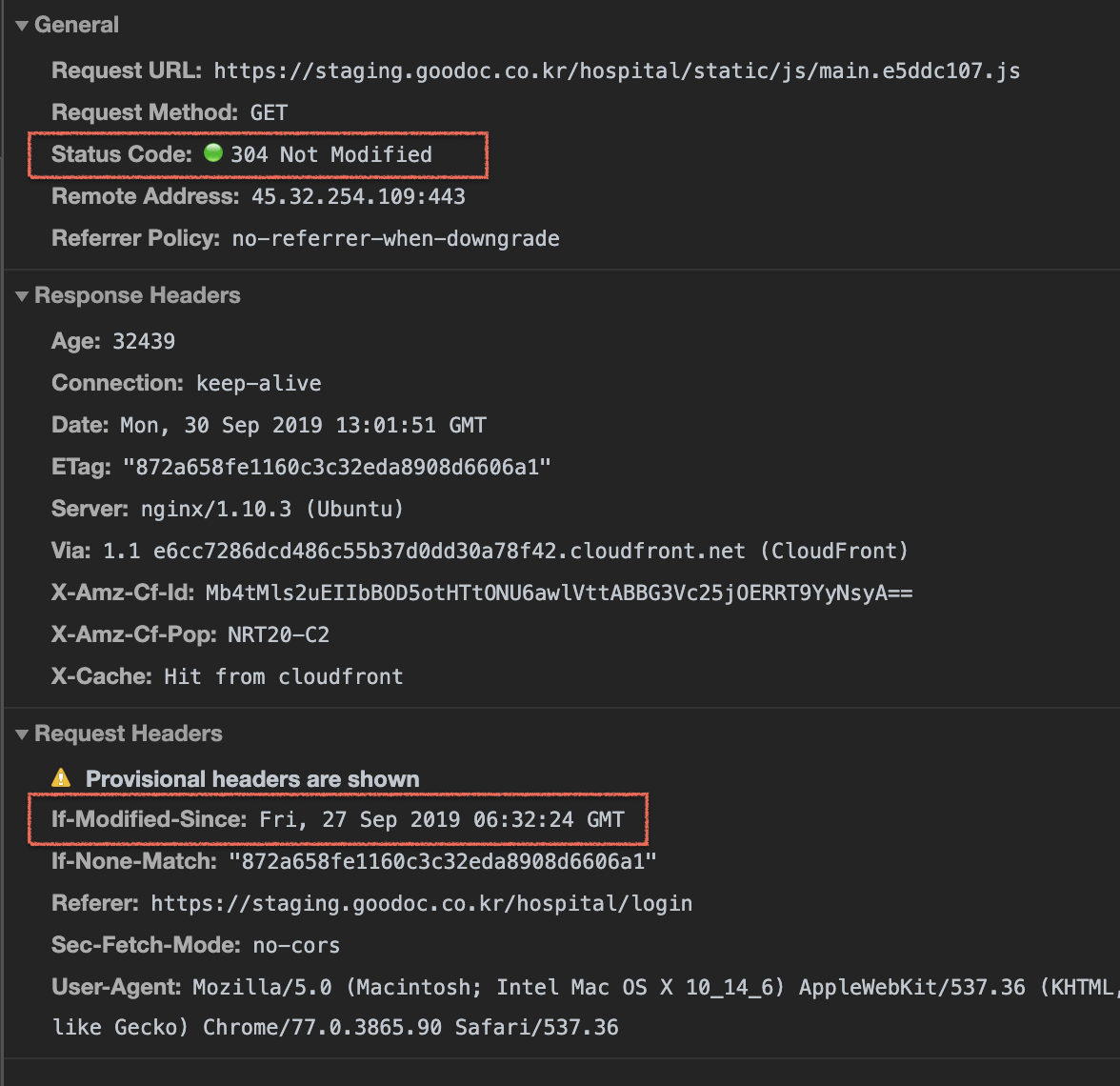
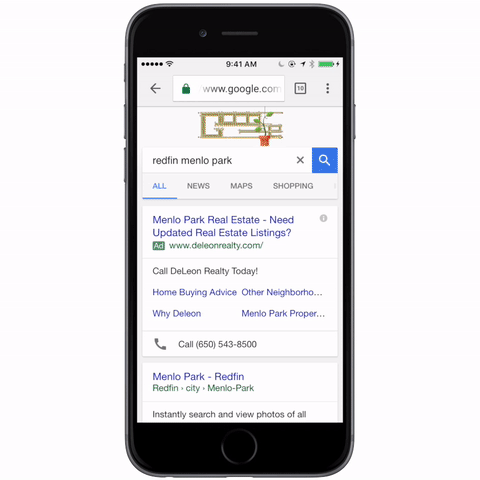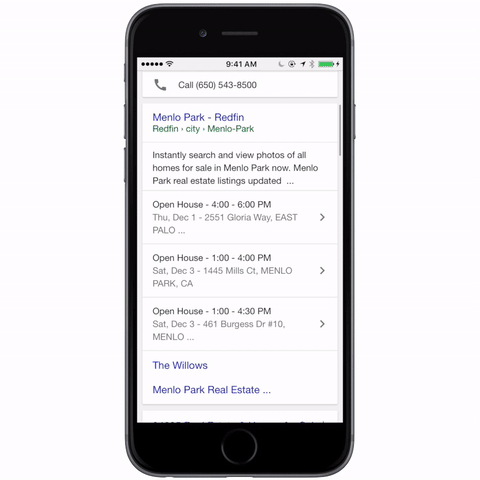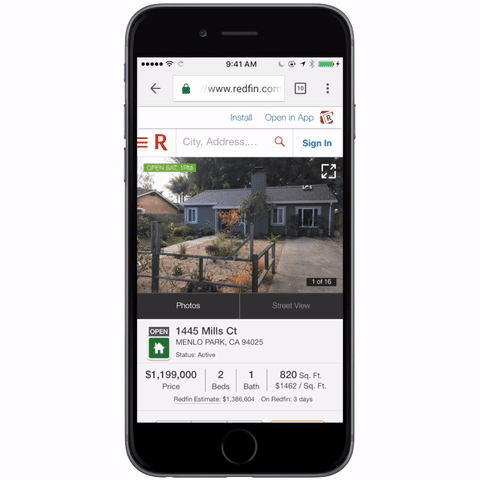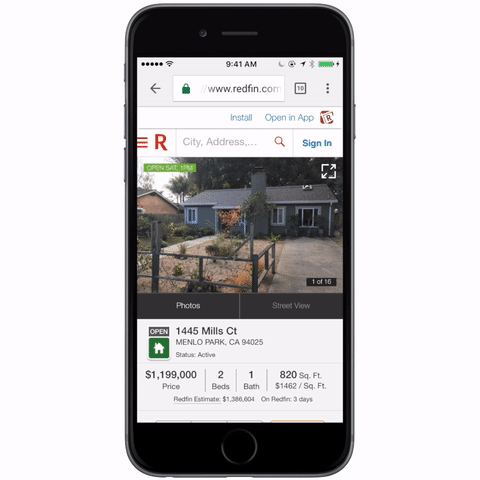





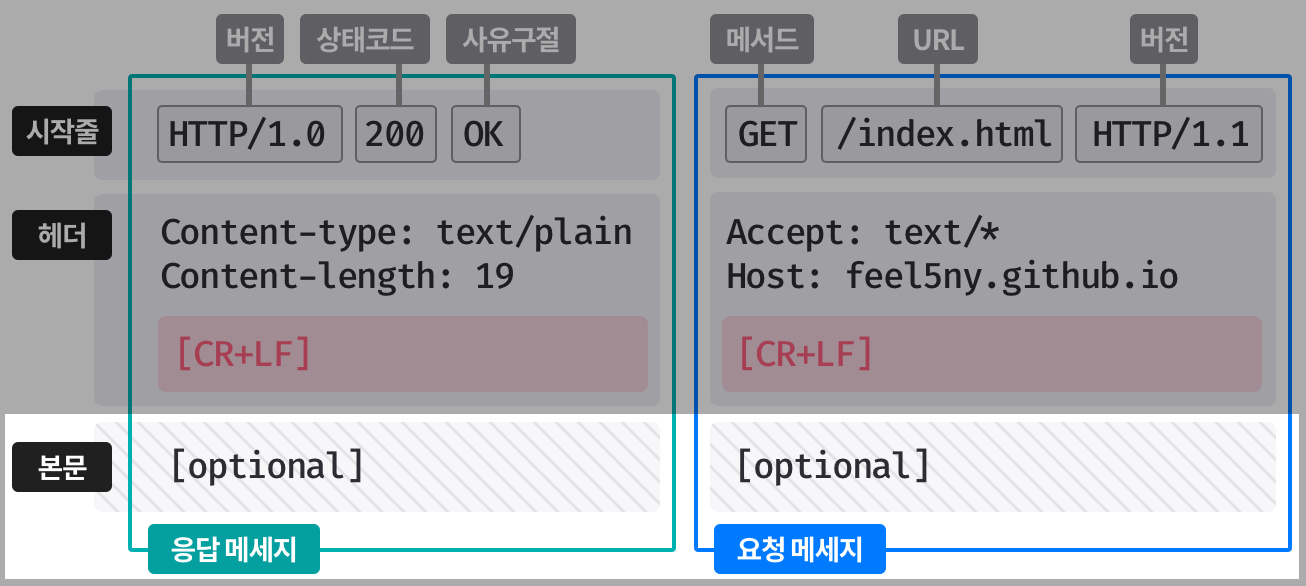
 -
-
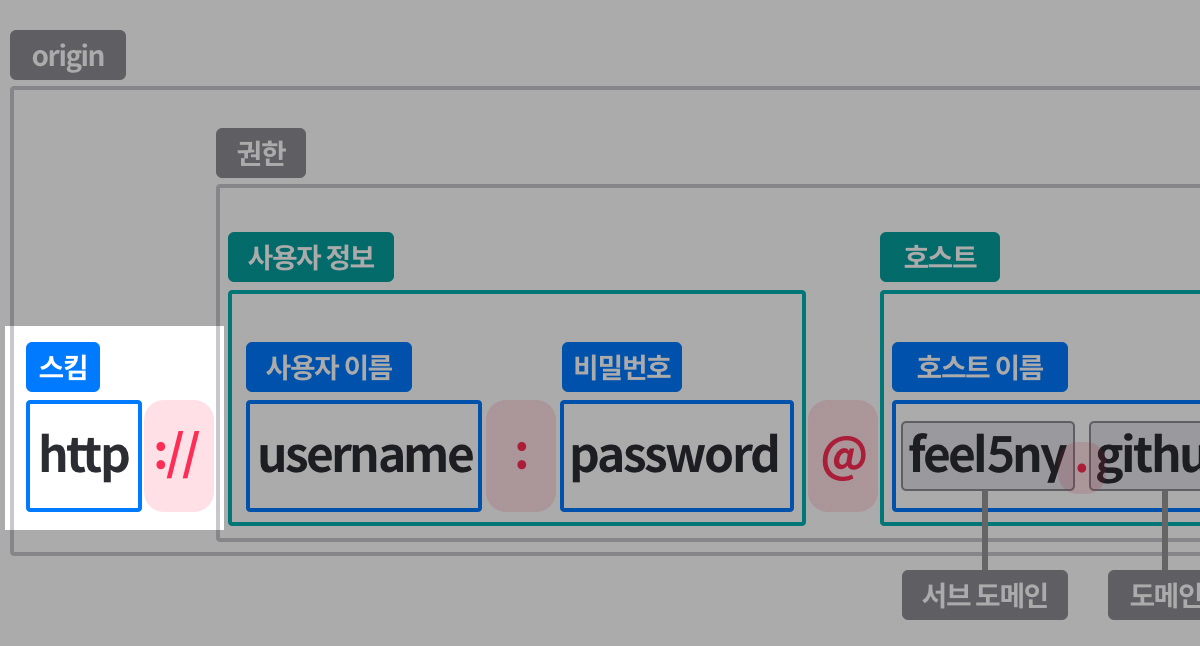
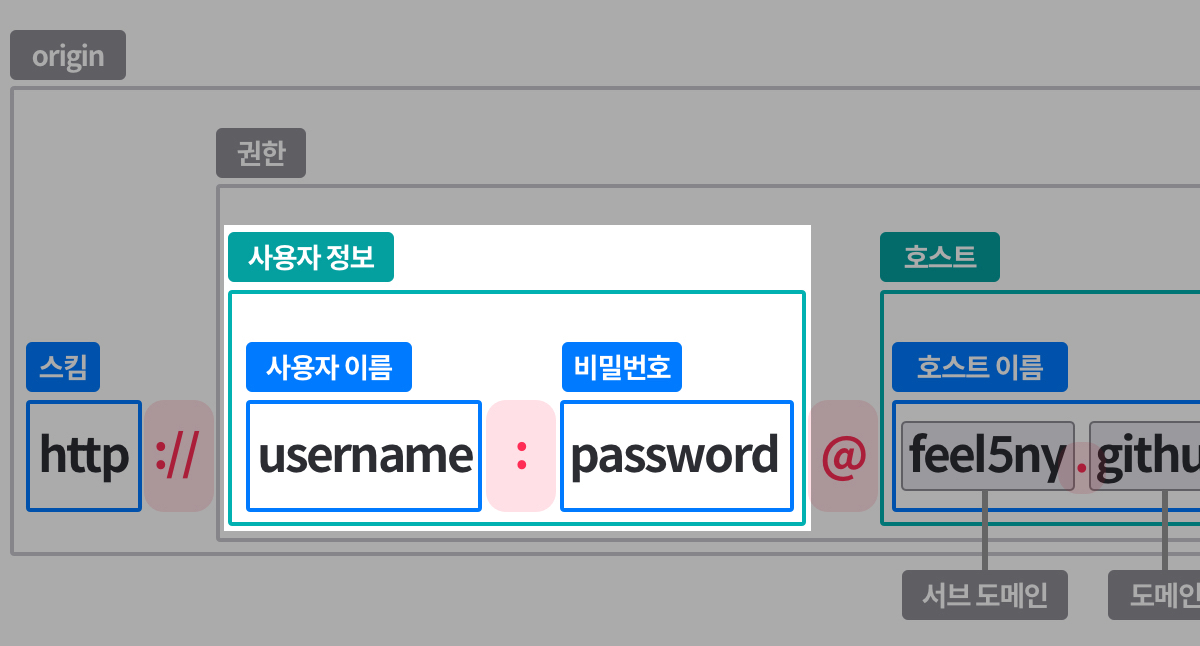







 +
+
 +
+
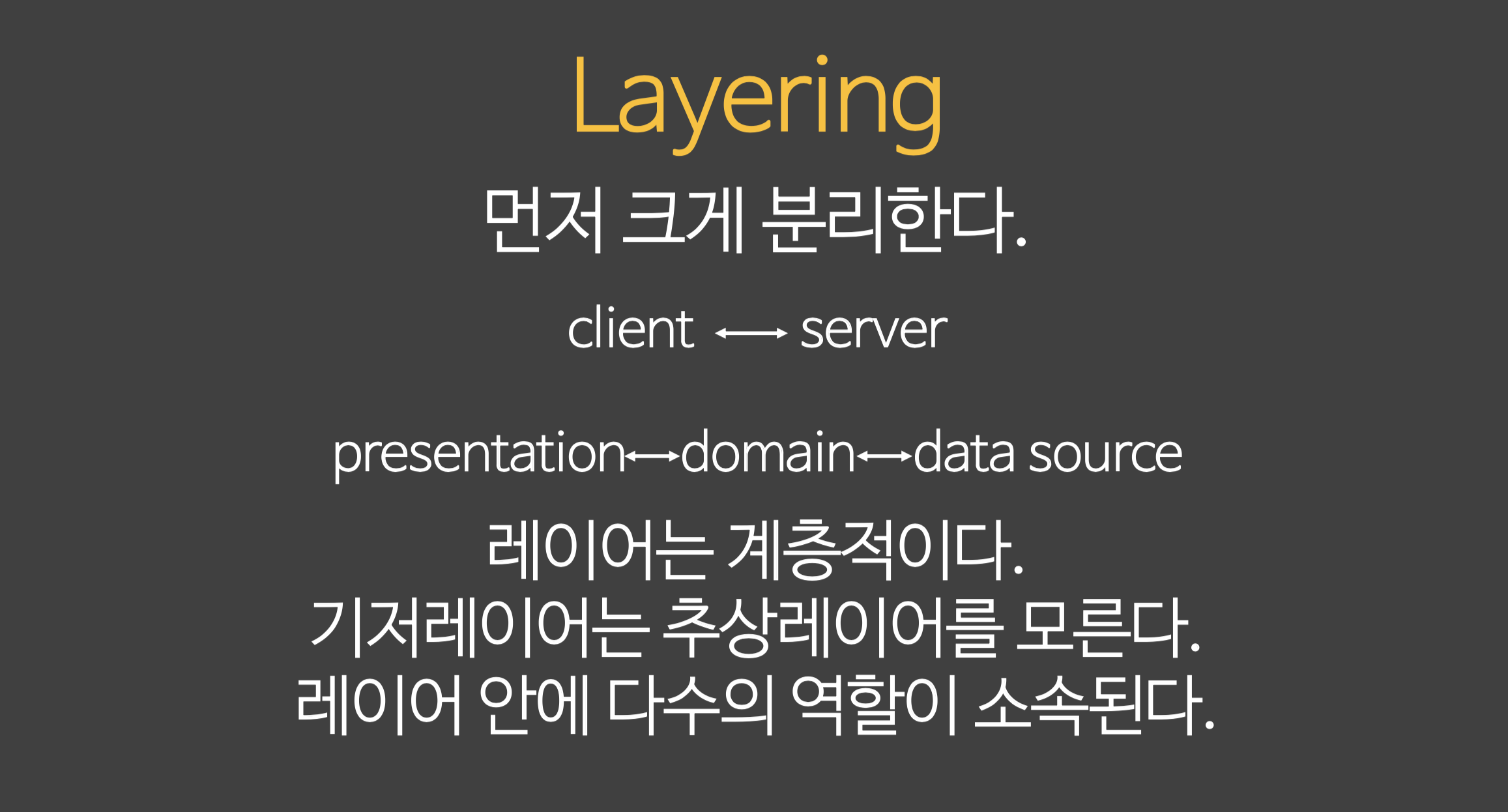
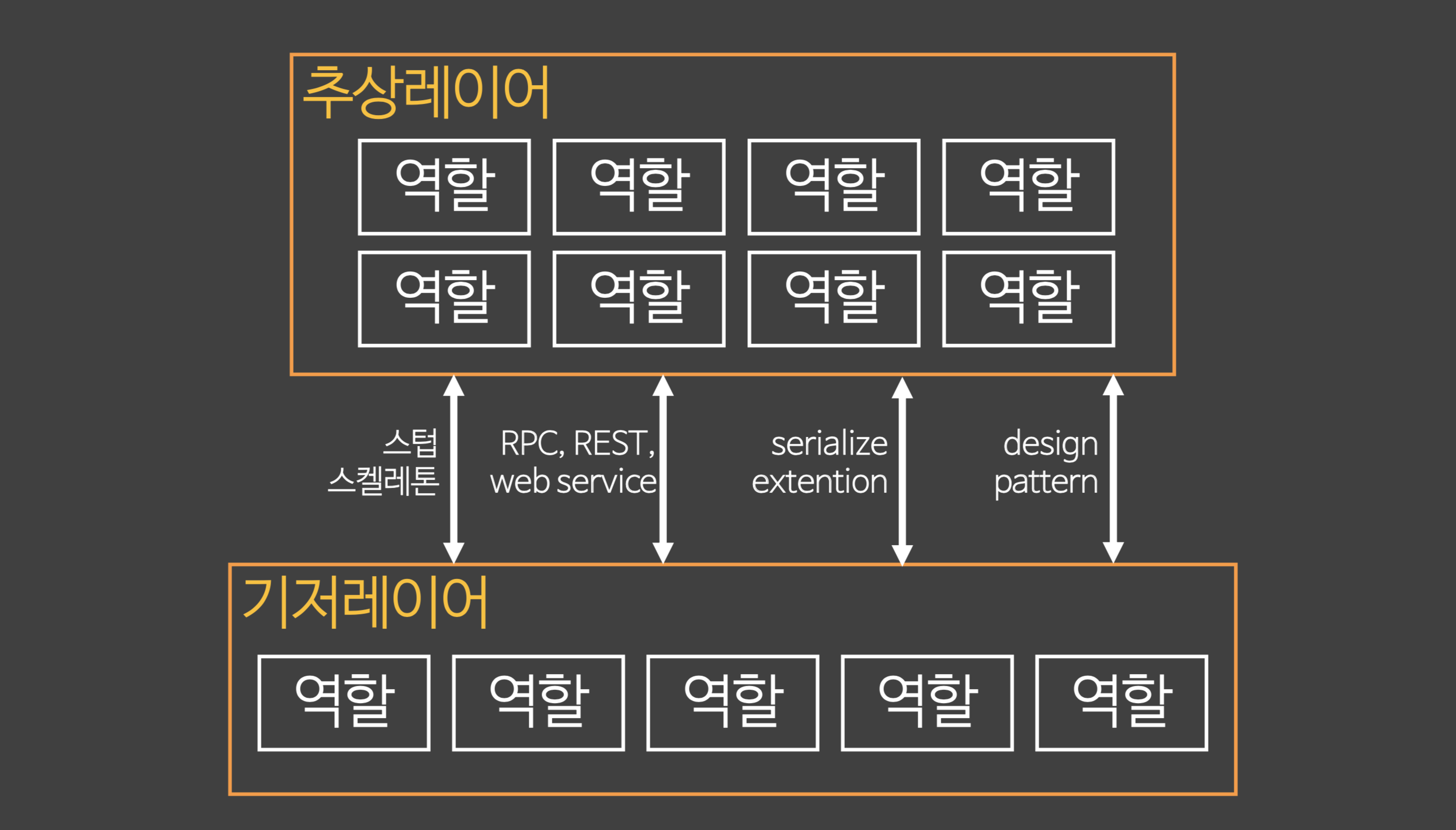 1. 레이어는 계층적이다. 레이어들간에는 호환되지 않는다! 층을 정확하게 나눠야한다.2. 기저레이어는 추상레이어를 모른다. **추상레이어** - 기저레이어를 사용하는 레이어 - 기저레이어에 대한 지식을 알고 있는 레이어 - OOP에 대입하면 **기저레이어: 부모클래스 추상레이어: 자식클래스** - 자식이 부모를 알고 있다. 부모는 자식을 모른다.3. 레이어안에 다수의 역할이 소속된다. 레이어안에는 다수의 역할이나 다수의 역할을 수행하는 인스턴스들이 소속된다.
1. 레이어는 계층적이다. 레이어들간에는 호환되지 않는다! 층을 정확하게 나눠야한다.2. 기저레이어는 추상레이어를 모른다. **추상레이어** - 기저레이어를 사용하는 레이어 - 기저레이어에 대한 지식을 알고 있는 레이어 - OOP에 대입하면 **기저레이어: 부모클래스 추상레이어: 자식클래스** - 자식이 부모를 알고 있다. 부모는 자식을 모른다.3. 레이어안에 다수의 역할이 소속된다. 레이어안에는 다수의 역할이나 다수의 역할을 수행하는 인스턴스들이 소속된다.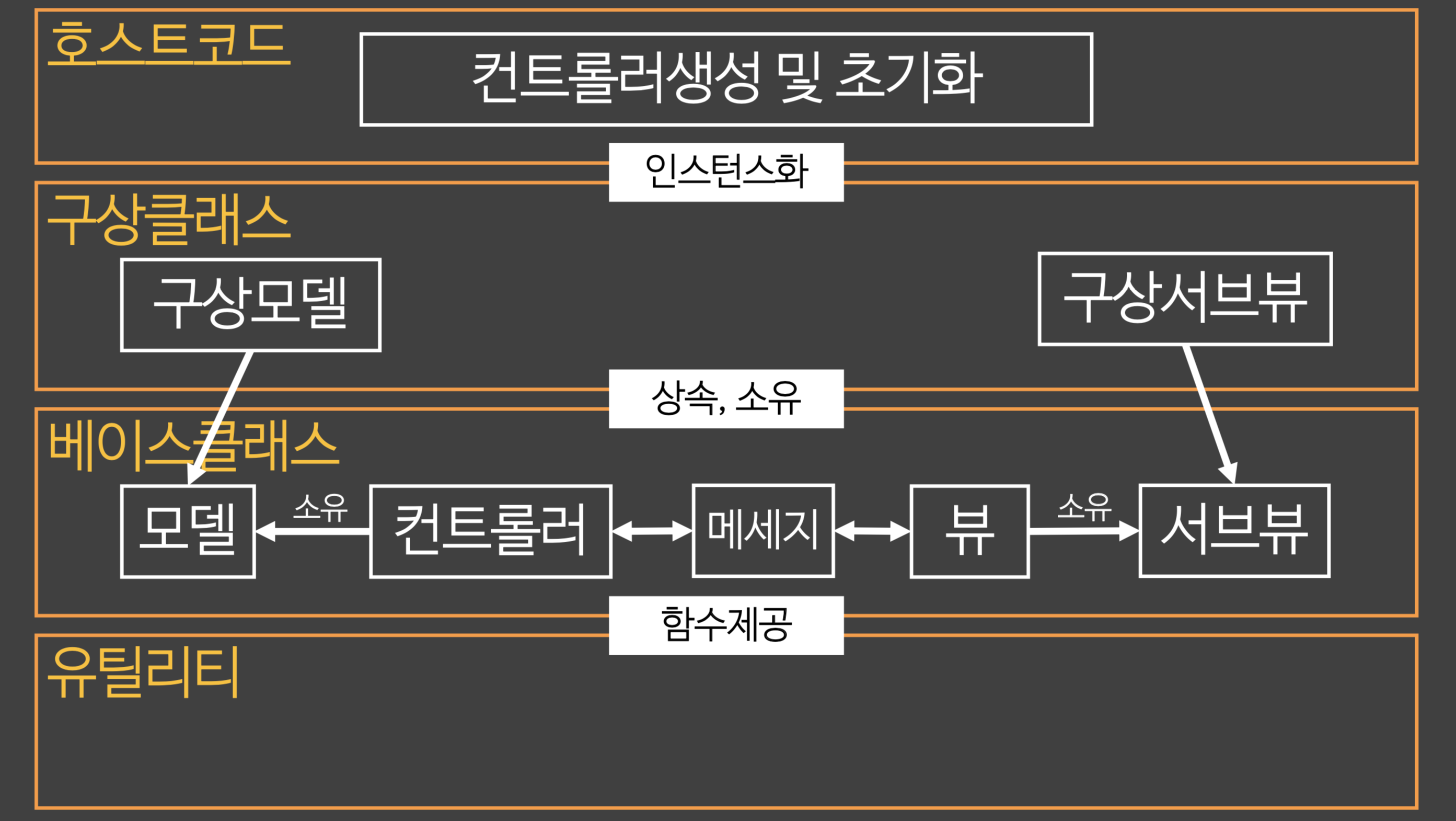

 ]]>
]]>




 2018년 1월 개발자로서 처음 실무에서 일하기 시작하였다. **업무 적응, 비즈니스 로직을 이해, 부족한 실력을 올리기 위해** 정신없는 하루하루를 보냈다. 얼마나 달렸냐면 전환일 기준으로 사용할 수 있는 연차가 9개였는데, 12월에 확인해보니 8개나 남아있었다..(좀 쉬엄쉬엄할걸!) 그래도 이런 전쟁 같은 상황에서 달릴 수 있었던 이유는, 전쟁 속에서도 **배움**이 있었기 때문이다.
2018년 1월 개발자로서 처음 실무에서 일하기 시작하였다. **업무 적응, 비즈니스 로직을 이해, 부족한 실력을 올리기 위해** 정신없는 하루하루를 보냈다. 얼마나 달렸냐면 전환일 기준으로 사용할 수 있는 연차가 9개였는데, 12월에 확인해보니 8개나 남아있었다..(좀 쉬엄쉬엄할걸!) 그래도 이런 전쟁 같은 상황에서 달릴 수 있었던 이유는, 전쟁 속에서도 **배움**이 있었기 때문이다.
 취미활동 취미활동.. 예전에는 기타치는걸 좋아했다! 예전이라 함은 디자인으로 수입이 있을때의 시기. 지금은 개발자가 되었기에 오히려 디자인작업이 리프레쉬할 수 있는 활동이 되었다. 아무래도 꾸준히 해왔던 커리어 중 하나였기 때문에 작업할 때 편안하고, 쉽게 놓지 못하는 부분도 있다.
취미활동 취미활동.. 예전에는 기타치는걸 좋아했다! 예전이라 함은 디자인으로 수입이 있을때의 시기. 지금은 개발자가 되었기에 오히려 디자인작업이 리프레쉬할 수 있는 활동이 되었다. 아무래도 꾸준히 해왔던 커리어 중 하나였기 때문에 작업할 때 편안하고, 쉽게 놓지 못하는 부분도 있다.  올해는 캐릭터 작업 외주, 간단한 인포그래픽 영상, 웹 디자인 작업이 들어왔다. 웹디자인 작업건이 제일 덩어리가 컸었는데, 시간을 너무 많이 들여야 해서 그 이후에는 정말 간단하게 작업할 수 있는 외주만 받았다. 작업물이 아까워서 드리블에 올렸는데 얼마 지나지 않아 바로 드리블에 초대되기도 했다. (예전엔 드리블 초대장 받으려고 그렇게 노력했건만!)
올해는 캐릭터 작업 외주, 간단한 인포그래픽 영상, 웹 디자인 작업이 들어왔다. 웹디자인 작업건이 제일 덩어리가 컸었는데, 시간을 너무 많이 들여야 해서 그 이후에는 정말 간단하게 작업할 수 있는 외주만 받았다. 작업물이 아까워서 드리블에 올렸는데 얼마 지나지 않아 바로 드리블에 초대되기도 했다. (예전엔 드리블 초대장 받으려고 그렇게 노력했건만!) 갑자기 ux이야기가 나왔다. 프론트엔드 개발자, 그리고 디자인에 관심 있는 사람으로서, 서비스의 첫인상과 신뢰성은 기능도 기능이지만, 사용성도 매우 중요하다고 생각한다. 지금까지 화려하고, 미적으로 아름다운 디자인들, ux가 잘 녹여있는 디자인들을 보았지만, 구현에서 실패하거나, 프론트엔드 개발자가 생각하는 디자인에 대한 중요성 정도 때문에 톤앤매너가 지켜지지 못한 구현물을 보곤 했다. 이런 상황의 해결을 위해서는 디자이너가 개발 친화적으로 디자인을 하거나, 개발자가 디자인시스템을 이해하여 디자이너에게 부족한 시안을 제안해야 한다는 점이다. 전자에 대한 관심도는 요즘 올라가고 있지만 후자는 아직 잘 모르겠다. ux관련 지식을 쌓아 유연하게 적용할 수 있도록 하여 서비스의 품질을 높이는 개발자가 되고 싶다!
갑자기 ux이야기가 나왔다. 프론트엔드 개발자, 그리고 디자인에 관심 있는 사람으로서, 서비스의 첫인상과 신뢰성은 기능도 기능이지만, 사용성도 매우 중요하다고 생각한다. 지금까지 화려하고, 미적으로 아름다운 디자인들, ux가 잘 녹여있는 디자인들을 보았지만, 구현에서 실패하거나, 프론트엔드 개발자가 생각하는 디자인에 대한 중요성 정도 때문에 톤앤매너가 지켜지지 못한 구현물을 보곤 했다. 이런 상황의 해결을 위해서는 디자이너가 개발 친화적으로 디자인을 하거나, 개발자가 디자인시스템을 이해하여 디자이너에게 부족한 시안을 제안해야 한다는 점이다. 전자에 대한 관심도는 요즘 올라가고 있지만 후자는 아직 잘 모르겠다. ux관련 지식을 쌓아 유연하게 적용할 수 있도록 하여 서비스의 품질을 높이는 개발자가 되고 싶다! 서비스는 작업자가 한 명이 혼자서 절대 작업할 수 없다. 협업이 필수인데, 바로 전후 단계에 밀접하게 붙어있는 작업자부터, 타 부서의 협력자들까지, 그들에게 믿음을 주는 동료가 되어야 한다고 생각한다. **이는 간단하게 보이면서도 디테일한 부분이라고 생각한다.** 배려심이라는 단어는 추상적이지만, 간단하게 말하자면 개발자는 비개발자들과 협업 시 최대한 그들이 이해하는 언어로 설명해주고, 문서화하는 것. 개발자들과는 나의 작업이 영향이 있을 협업자들과의 커뮤니케이션을 유연하게 하는 것. 진짜 진짜 기본적인 것인데 의외로 간과하는 사람들이 있는 것 같다. 서로 배려하는 문화는 좋은 서비스를 만드는 중요한 부분이라고 생각한다.
서비스는 작업자가 한 명이 혼자서 절대 작업할 수 없다. 협업이 필수인데, 바로 전후 단계에 밀접하게 붙어있는 작업자부터, 타 부서의 협력자들까지, 그들에게 믿음을 주는 동료가 되어야 한다고 생각한다. **이는 간단하게 보이면서도 디테일한 부분이라고 생각한다.** 배려심이라는 단어는 추상적이지만, 간단하게 말하자면 개발자는 비개발자들과 협업 시 최대한 그들이 이해하는 언어로 설명해주고, 문서화하는 것. 개발자들과는 나의 작업이 영향이 있을 협업자들과의 커뮤니케이션을 유연하게 하는 것. 진짜 진짜 기본적인 것인데 의외로 간과하는 사람들이 있는 것 같다. 서로 배려하는 문화는 좋은 서비스를 만드는 중요한 부분이라고 생각한다.
 > [포터모어](https://www.pottermore.com/)]]>
> [포터모어](https://www.pottermore.com/)]]>
 > 아니야..!!
> 아니야..!!  > 2018년 2월 ~ 2018년 8월 26일까지
> 2018년 2월 ~ 2018년 8월 26일까지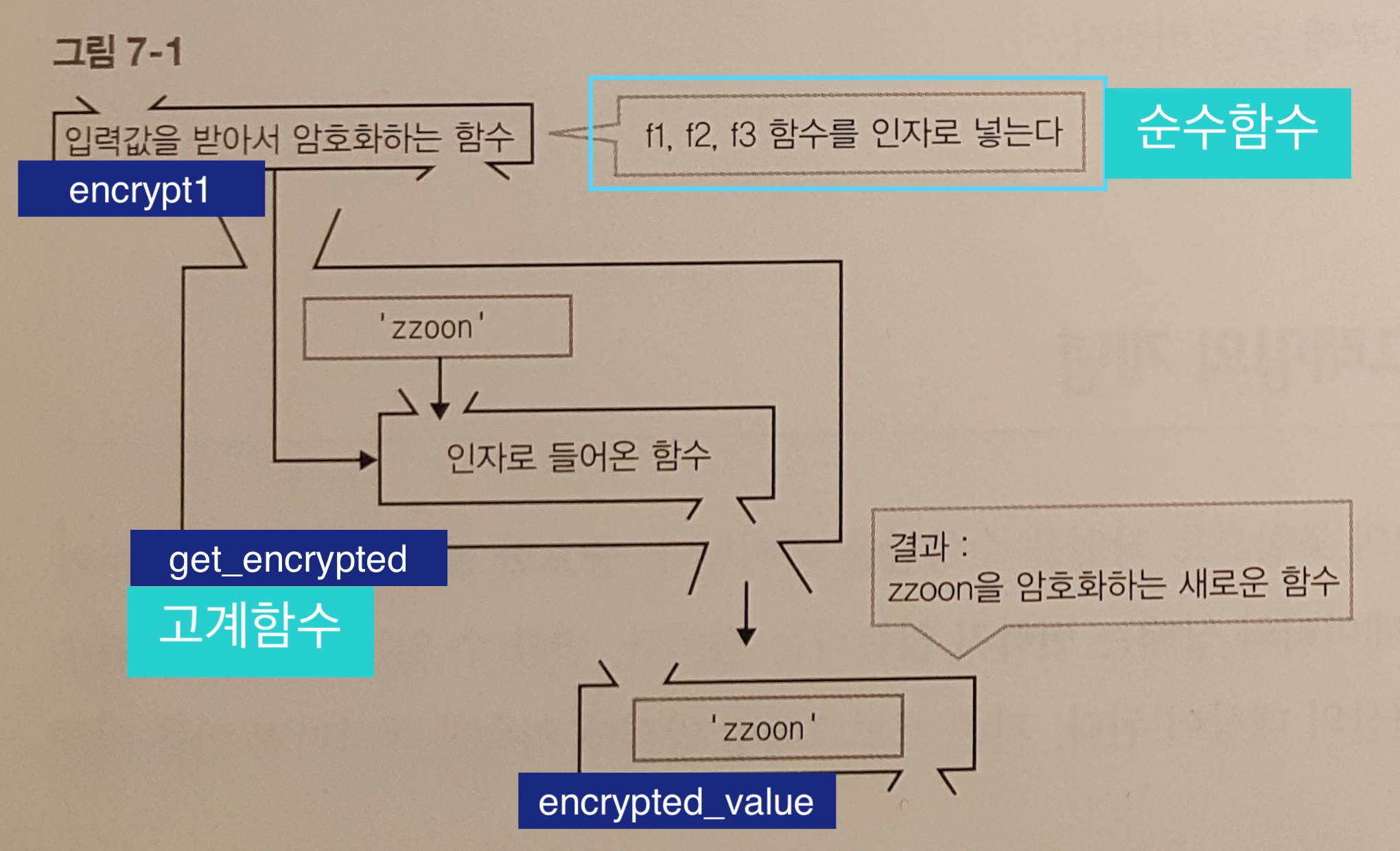

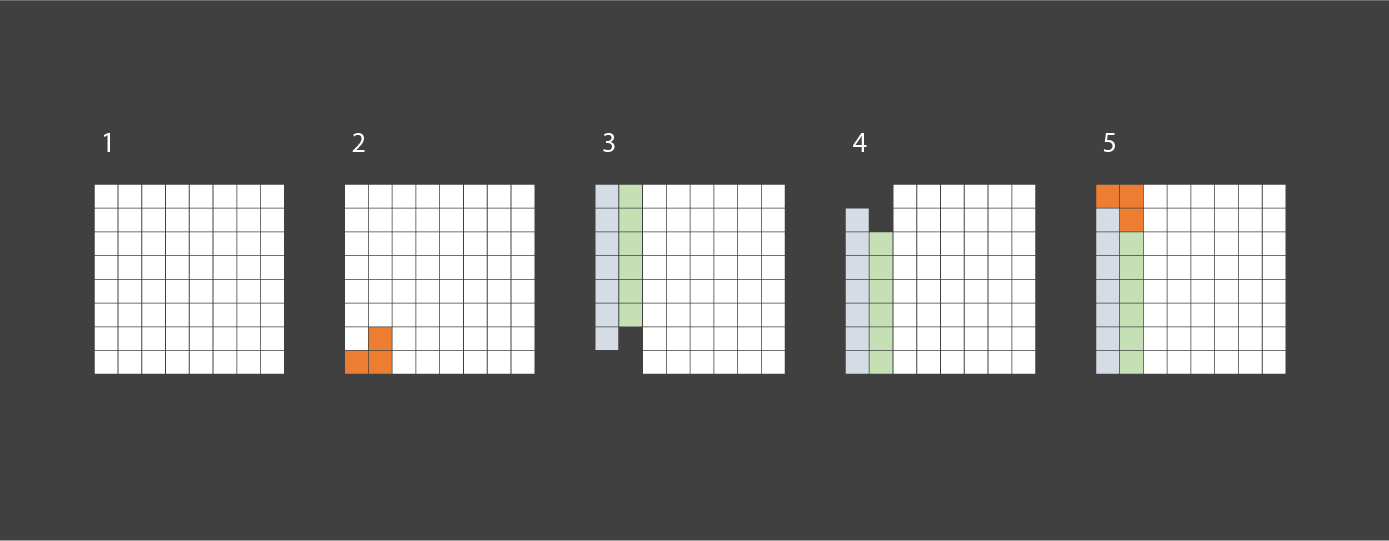
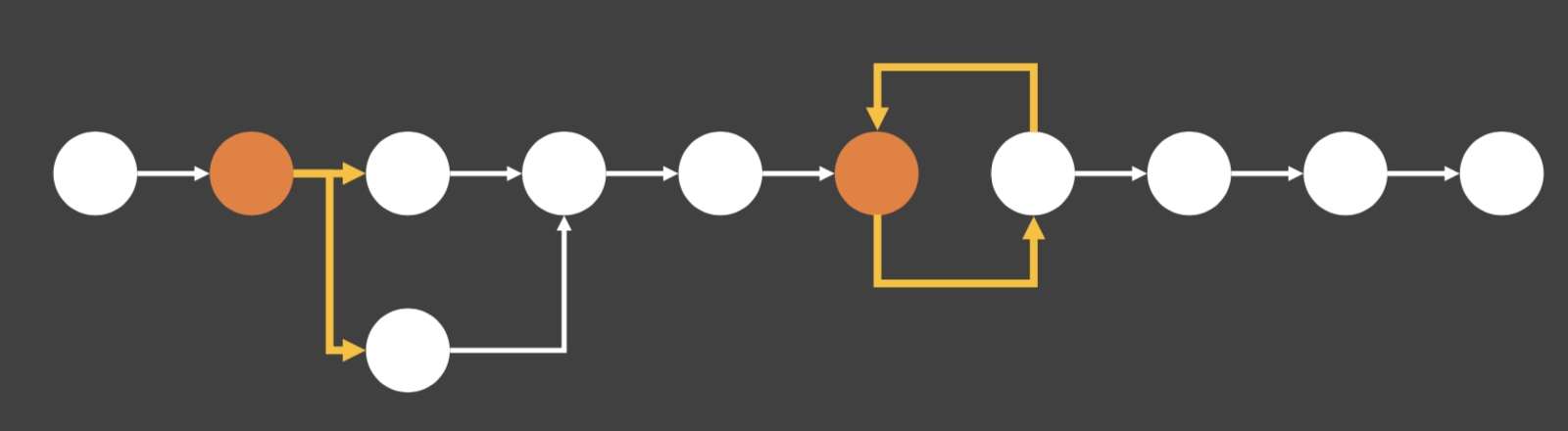
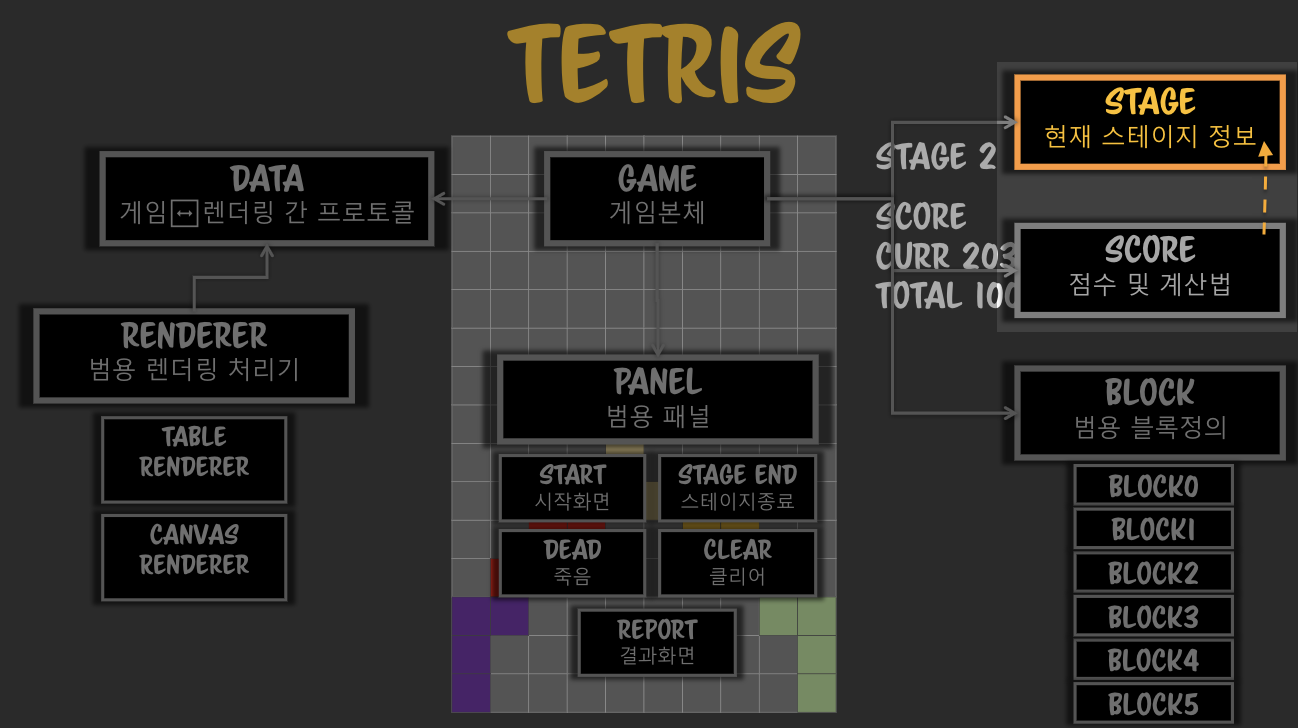 score와 stage간의 의존성이 생김
score와 stage간의 의존성이 생김 세로와 가로의 모습을 보면 **2차원 배열**로 구현할 수 있다는 것이 보인다. (행과 열)
세로와 가로의 모습을 보면 **2차원 배열**로 구현할 수 있다는 것이 보인다. (행과 열)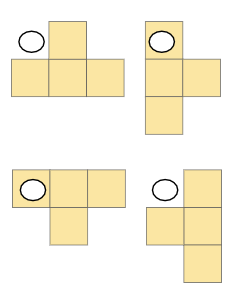
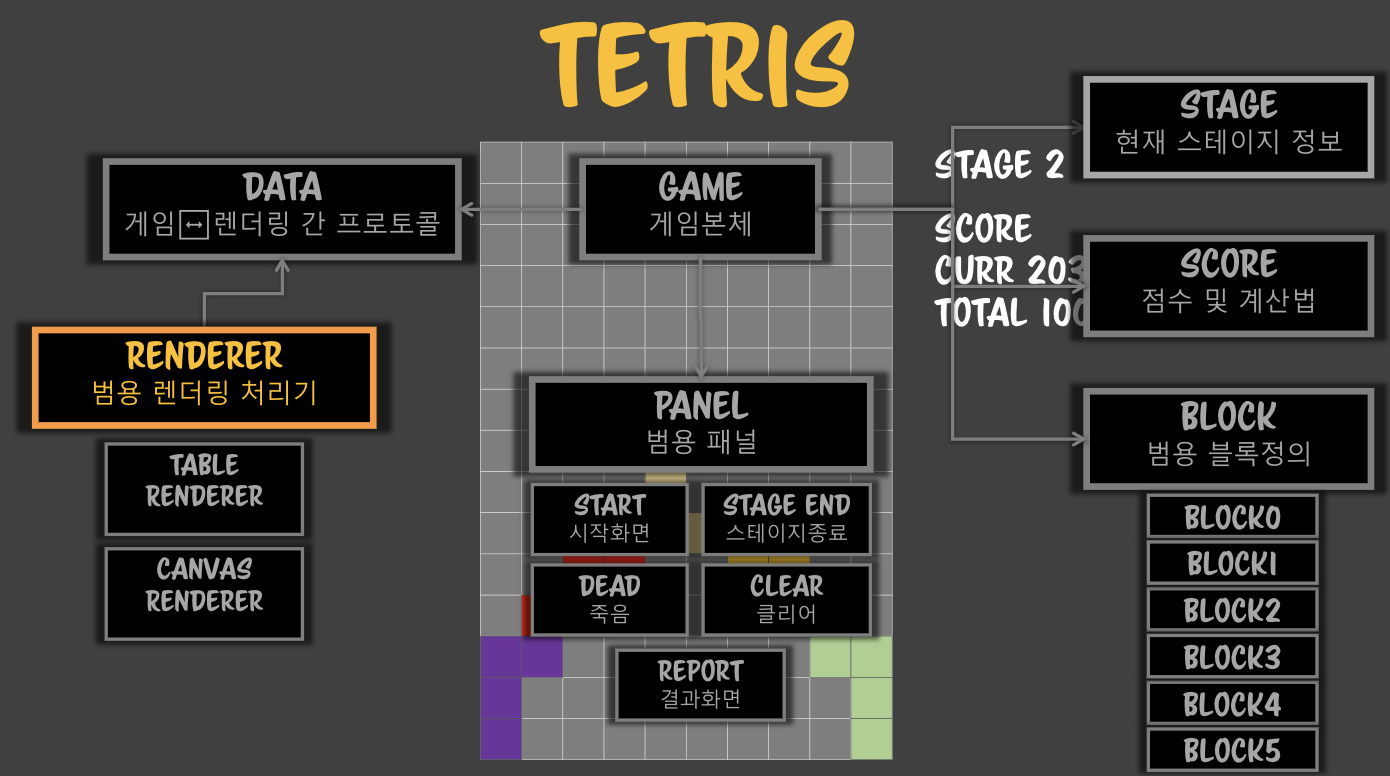
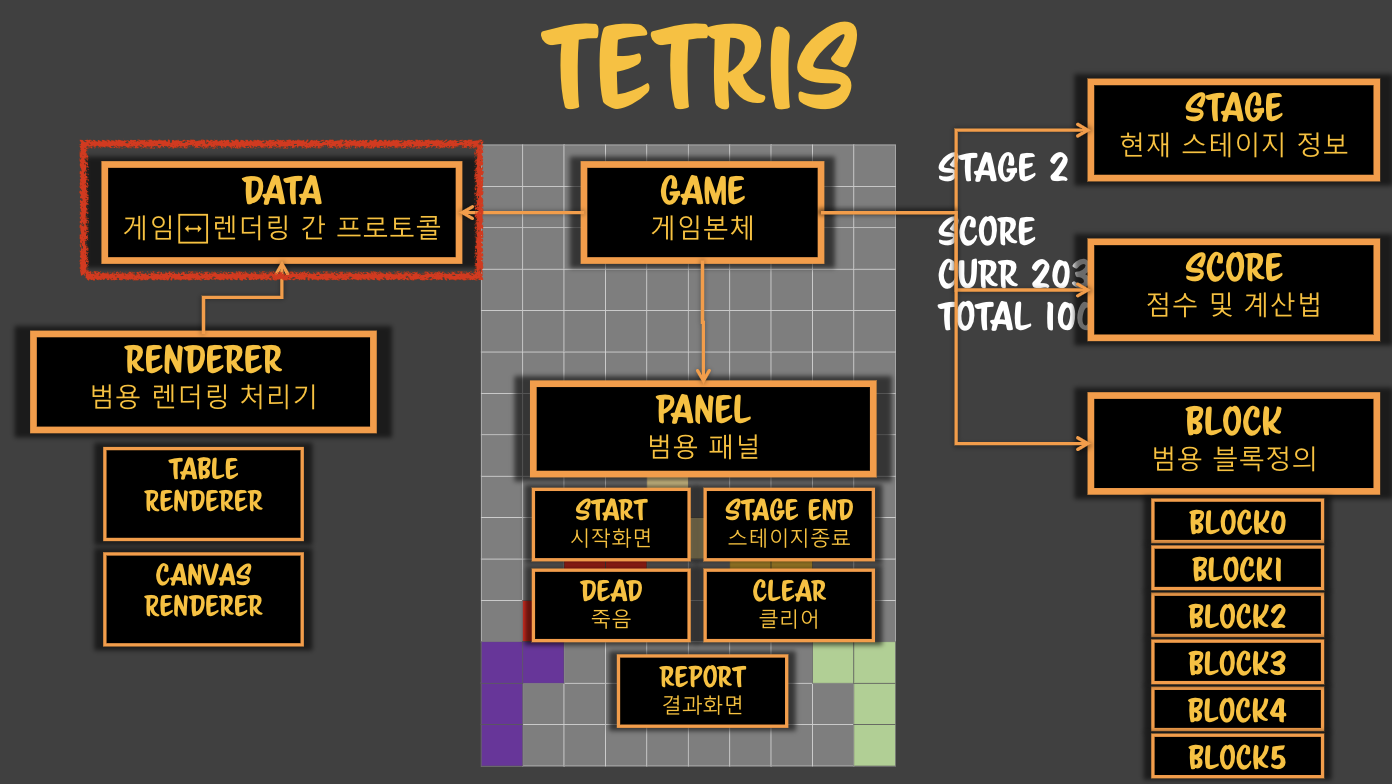 - 혹시나 하는 의존성을 찾기 위해서 전체 그림을 그려본다.- UML- 설계시에는 simplex를 유지하자.
- 혹시나 하는 의존성을 찾기 위해서 전체 그림을 그려본다.- UML- 설계시에는 simplex를 유지하자.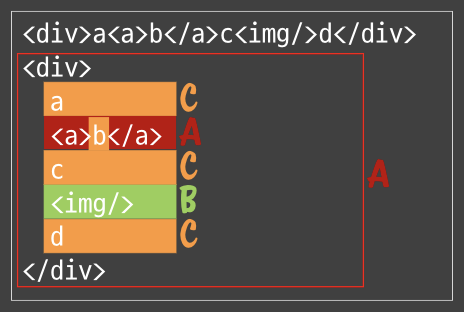 > 위의 그림을 파싱할 수 있는 파서를 만들고 싶다!> 케이스가 재귀면서 복합적인 상황을 짤 수 있다면 **중급개발자**
> 위의 그림을 파싱할 수 있는 파서를 만들고 싶다!> 케이스가 재귀면서 복합적인 상황을 짤 수 있다면 **중급개발자**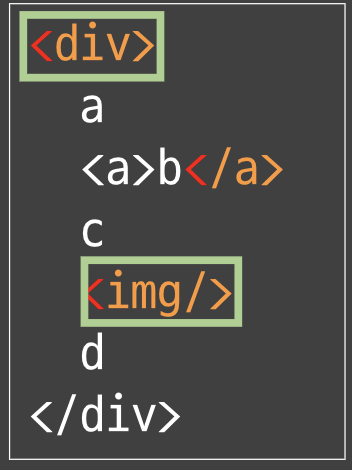
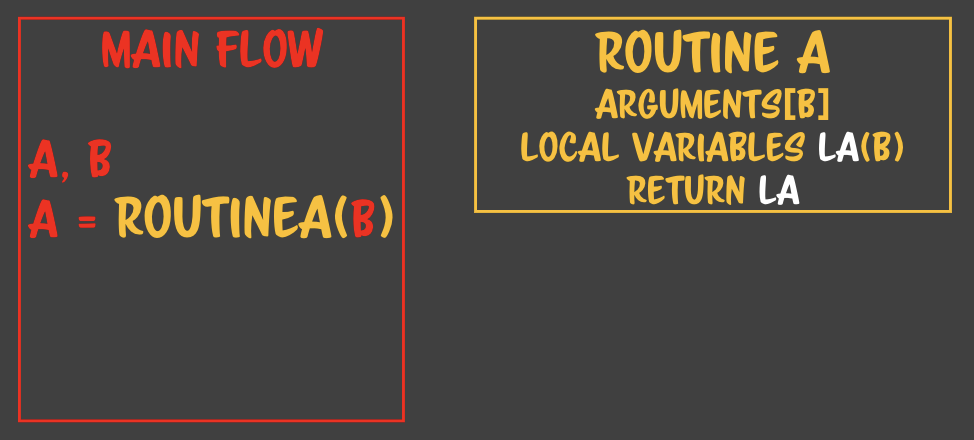
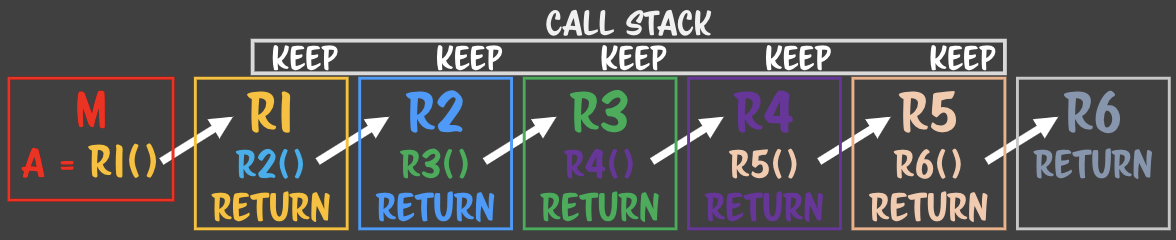
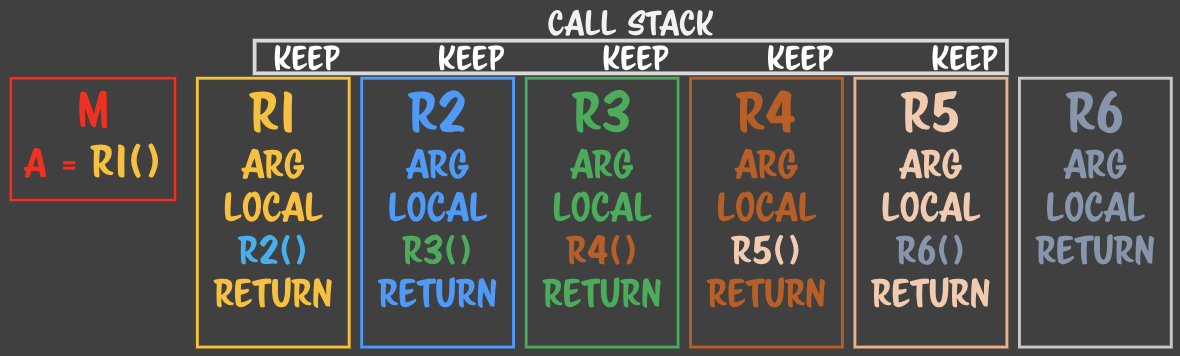
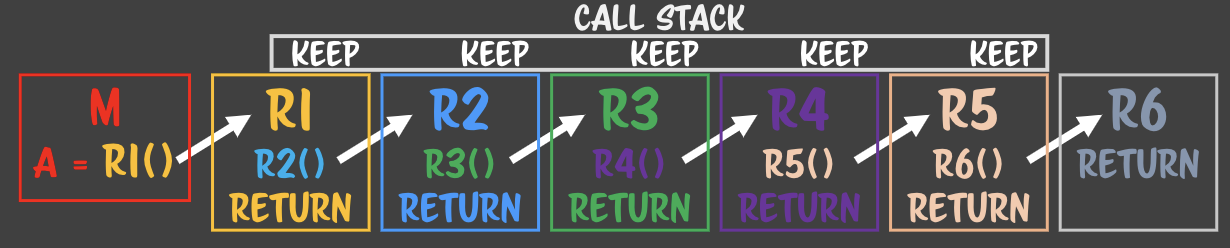
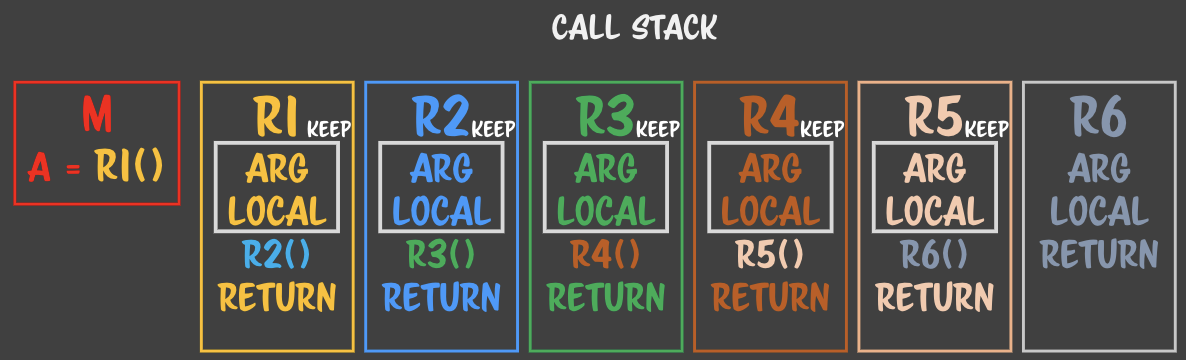 > keep의 정확한 대상
> keep의 정확한 대상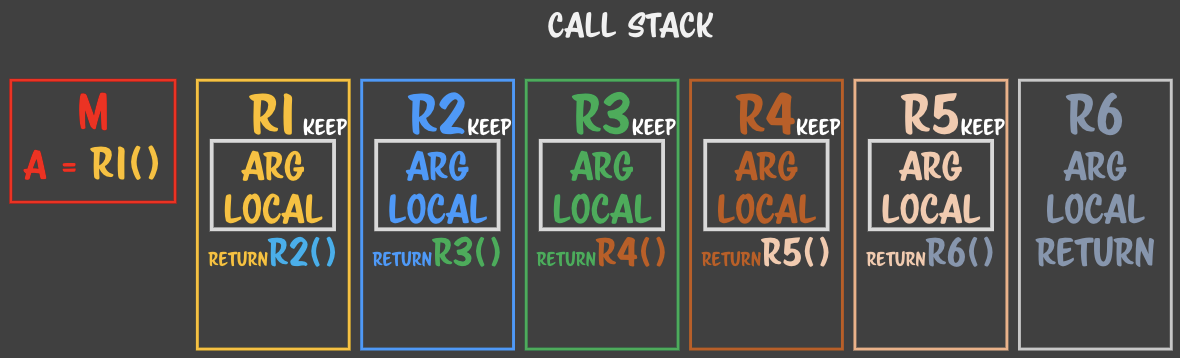 - 함수 콜을 return 이후로 옮겼다.
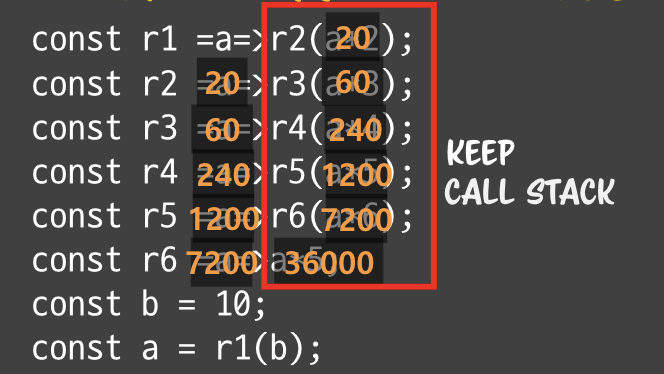
- 함수 콜을 return 이후로 옮겼다.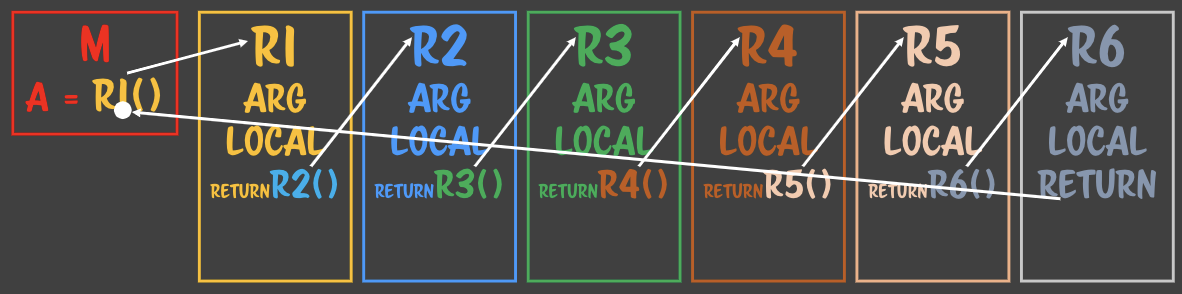 - 메모리를 유지할 필요가 없으니, 리턴포인트를 다른 곳으로 지정해주면 어떨까?- 리턴포인트는 언어 수준에서 정해져있다.- 리턴포인트를 처음 호출한 함수로 옮긴다 => tail recursion - 언어수준에서 리턴포인트를 지정하기 때문에 언어마다 재귀꼬리 최적화를 지원하는 언어도 있고, 없기도 하다.- 제어문의 loop 처럼 옮긴다. - 처리하고 => 해제하고 - 제어문은 for문을 돌때마다 메모리를 유지하지 않는다. - index 변수만 남아 있다. - 제어문의 **`stack clear`** 구문. - for문은 처음 loop돌리는 블럭에 대해서 스택영역에 대해서 실행한 다음에 점프시, 앞의 stack 메모리를 전부 해제한다.
- 메모리를 유지할 필요가 없으니, 리턴포인트를 다른 곳으로 지정해주면 어떨까?- 리턴포인트는 언어 수준에서 정해져있다.- 리턴포인트를 처음 호출한 함수로 옮긴다 => tail recursion - 언어수준에서 리턴포인트를 지정하기 때문에 언어마다 재귀꼬리 최적화를 지원하는 언어도 있고, 없기도 하다.- 제어문의 loop 처럼 옮긴다. - 처리하고 => 해제하고 - 제어문은 for문을 돌때마다 메모리를 유지하지 않는다. - index 변수만 남아 있다. - 제어문의 **`stack clear`** 구문. - for문은 처음 loop돌리는 블럭에 대해서 스택영역에 대해서 실행한 다음에 점프시, 앞의 stack 메모리를 전부 해제한다.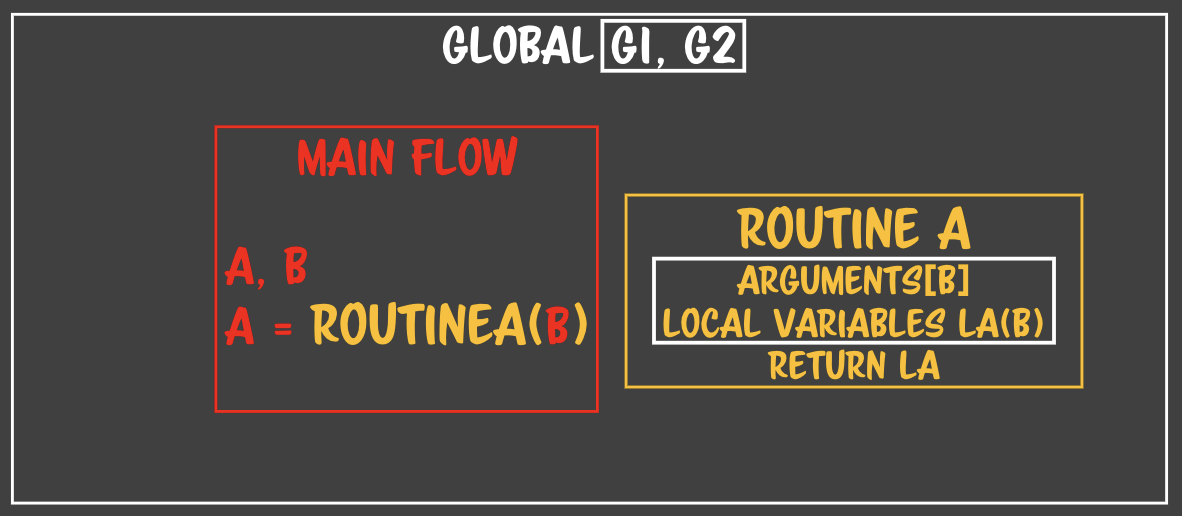 **클로저는 오직 런타임 중에 루틴을 만들 수 있는 언어에서 생겨난다.**- c에서는 static 메모리- 그렇다고 이런상황에서 모든 언어가 클로저를 생산하진 않는다.. - 언어 디자이너가 어떻게 결정했냐에 따라 다르다.- 함수를 문으로 만드는 언어의 특성
**클로저는 오직 런타임 중에 루틴을 만들 수 있는 언어에서 생겨난다.**- c에서는 static 메모리- 그렇다고 이런상황에서 모든 언어가 클로저를 생산하진 않는다.. - 언어 디자이너가 어떻게 결정했냐에 따라 다르다.- 함수를 문으로 만드는 언어의 특성 => 우리가 짠 코드를 만나면 =>
=> 우리가 짠 코드를 만나면 =>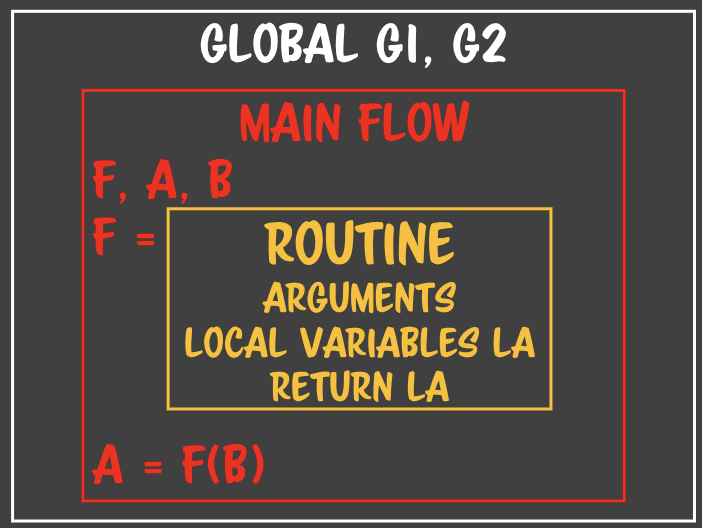 - 실행 중간(런타임)에 루틴의 정의 자체가 태어난다.
- 실행 중간(런타임)에 루틴의 정의 자체가 태어난다.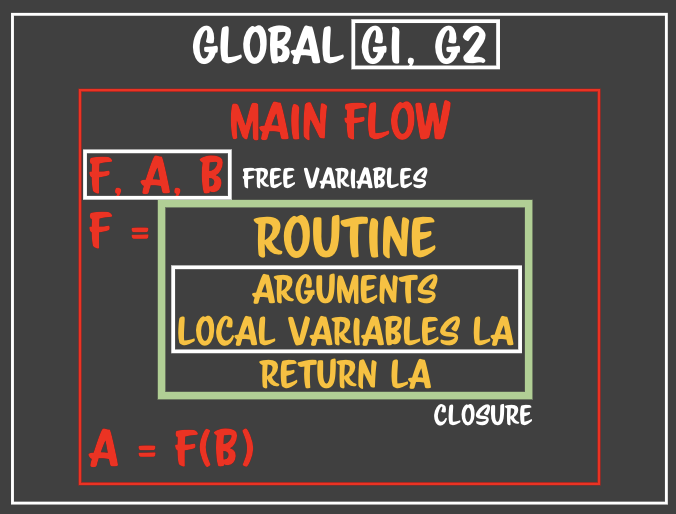 - 자기가 태어났을 때의 **자기가 갇혀있던 박스**를 바라볼 수 있는 여지가 생긴다.- 런타임에 루틴을 만들 수 있는 언어들은 루틴을 만들면 루틴정보 안에 자기가 어디서 태어났는지를 기록한다. => 자바스크립트에서는 **스코프**라고 정의한다.- **메인 루틴의 flow를 기억한다.** main flow가 흘러가는 상황을 알고 있다. - flow상에 있는 아이들을 기억하게 된다. - 노란박스에 등장하지 않는 모든 변수를 **자유변수**라고 한다.- 자유변수들은 routine과 무관하게 존재하지만 routine에서 참조할 수 있다. - routine이 한번이라도 자유변수를 갖고오게 되면 자유변수들은 마음대로 해지되거나 조작되지 못한다. **=> routine이 물고 있기 때문** - routine을 자유변수가 갇히는 공간이라고 할 수 있다. - free variables close => closure- 만약 이 상황에서 F 메소드가 외부로 유출될 경우 main flow의 메모리가 다 해지되지 못한다.- 클로저는 자유변수의 클로저이다.
- 자기가 태어났을 때의 **자기가 갇혀있던 박스**를 바라볼 수 있는 여지가 생긴다.- 런타임에 루틴을 만들 수 있는 언어들은 루틴을 만들면 루틴정보 안에 자기가 어디서 태어났는지를 기록한다. => 자바스크립트에서는 **스코프**라고 정의한다.- **메인 루틴의 flow를 기억한다.** main flow가 흘러가는 상황을 알고 있다. - flow상에 있는 아이들을 기억하게 된다. - 노란박스에 등장하지 않는 모든 변수를 **자유변수**라고 한다.- 자유변수들은 routine과 무관하게 존재하지만 routine에서 참조할 수 있다. - routine이 한번이라도 자유변수를 갖고오게 되면 자유변수들은 마음대로 해지되거나 조작되지 못한다. **=> routine이 물고 있기 때문** - routine을 자유변수가 갇히는 공간이라고 할 수 있다. - free variables close => closure- 만약 이 상황에서 F 메소드가 외부로 유출될 경우 main flow의 메모리가 다 해지되지 못한다.- 클로저는 자유변수의 클로저이다.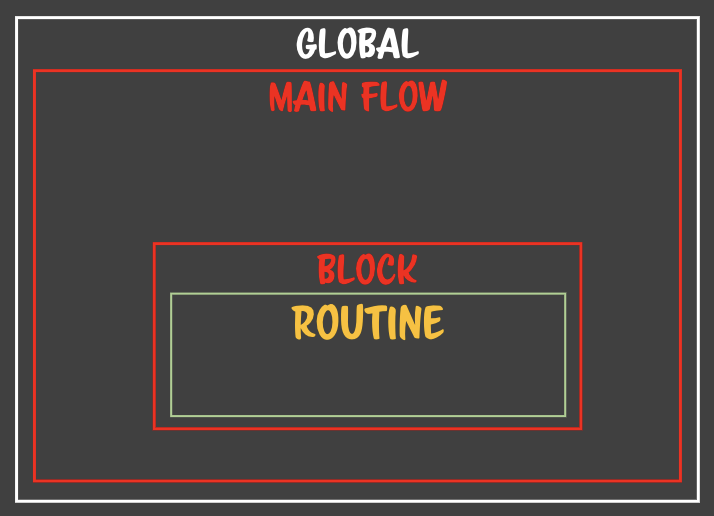
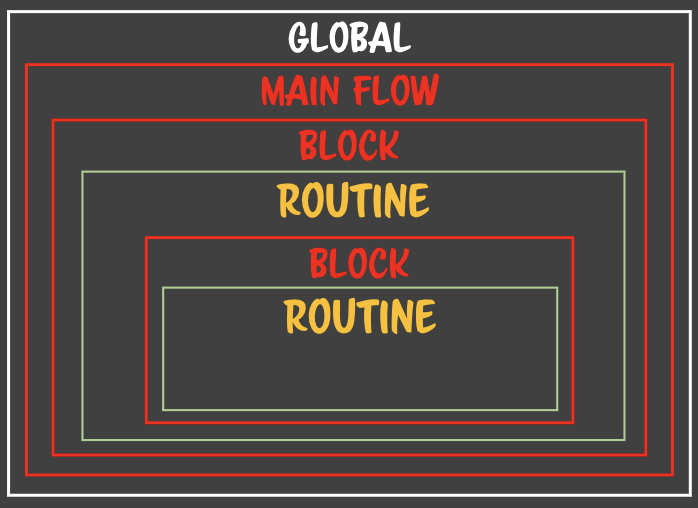 - 연속적인 클로저가 탄생한다.- 중첩되어 있는 클로저를 마구마구 생성된다.
- 연속적인 클로저가 탄생한다.- 중첩되어 있는 클로저를 마구마구 생성된다.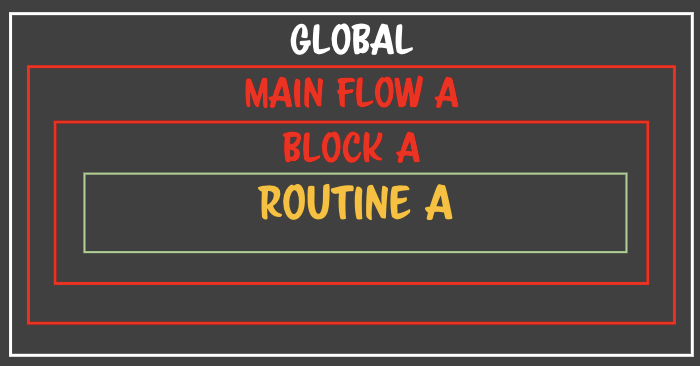 - 층층이 중첩되어있는 클로저가 있는데 각각의 클로저에서 똑같은 이름의 변수를 소유하고 있을때 일어난다.
- 층층이 중첩되어있는 클로저가 있는데 각각의 클로저에서 똑같은 이름의 변수를 소유하고 있을때 일어난다.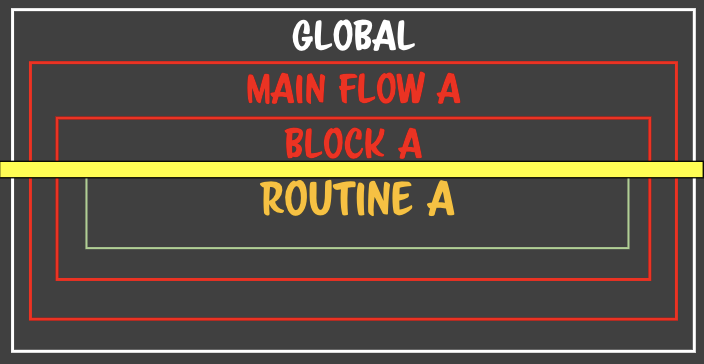
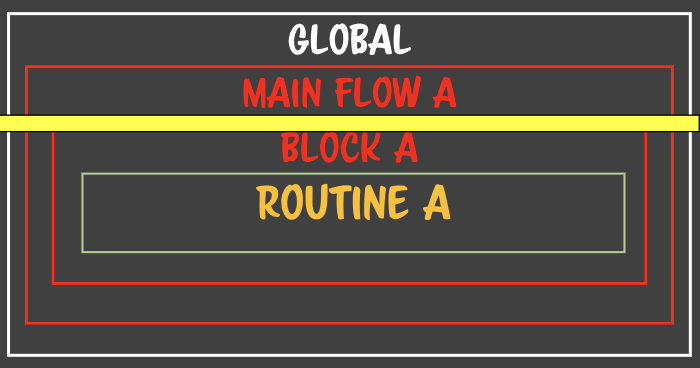
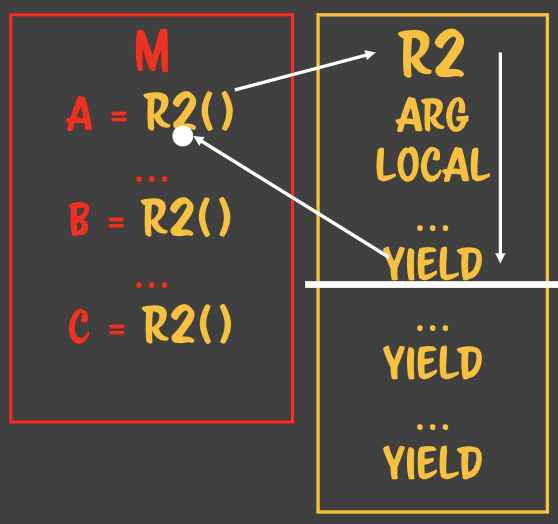
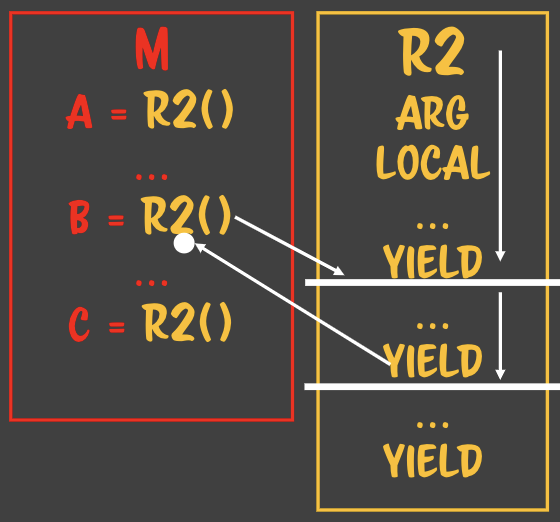
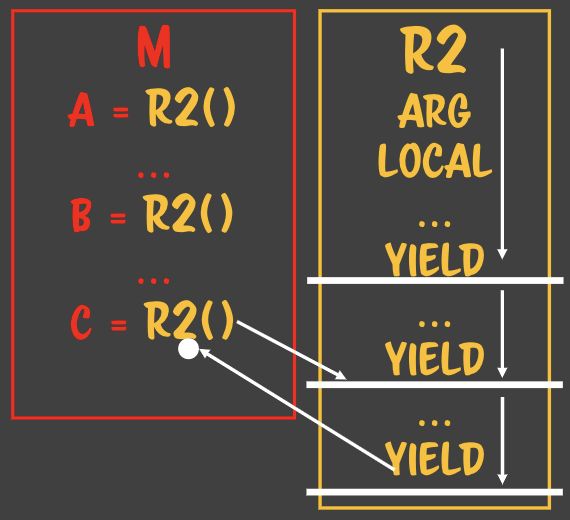
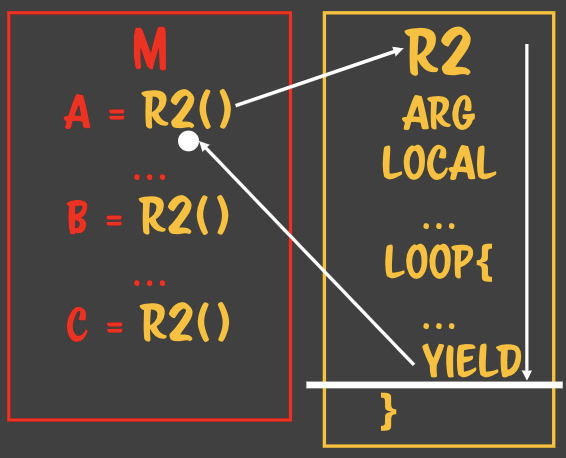
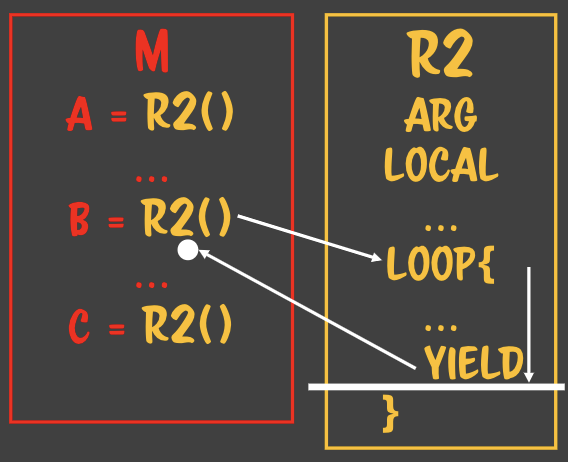
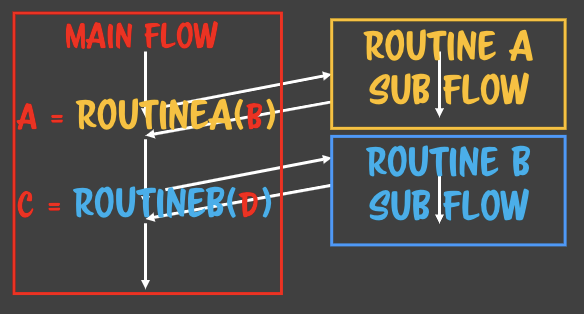
 ### 자바스크립트는 LR 파서를 사용한다.- 자바스크립트로 작성된 파일을 파싱할 때 사용하는 방법- 왼쪽에서 오른쪽, 위에서 아래로 파싱- 할당은 RL 파서이다. - 수학적인 컨텍스트로 정의되어있다.
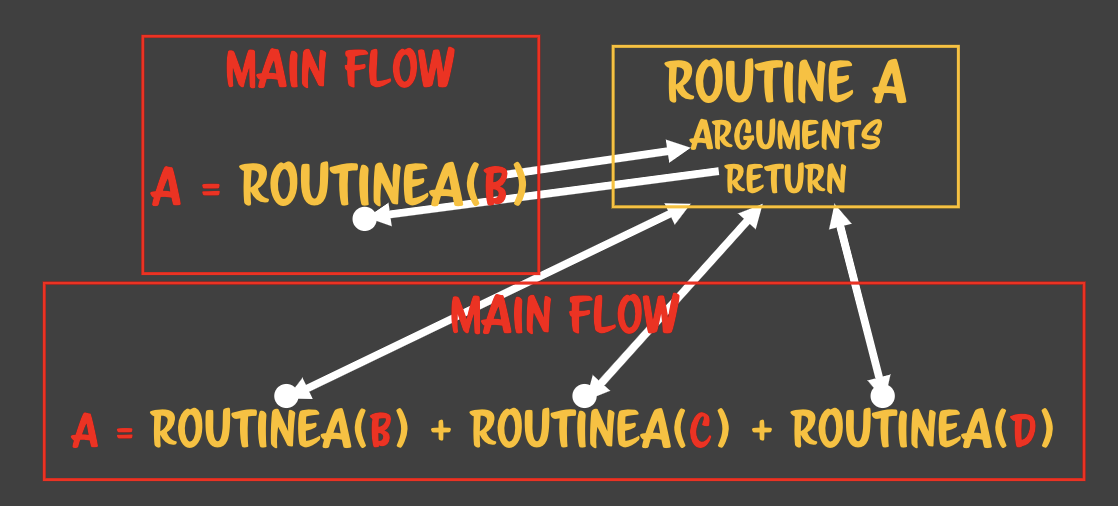
### 자바스크립트는 LR 파서를 사용한다.- 자바스크립트로 작성된 파일을 파싱할 때 사용하는 방법- 왼쪽에서 오른쪽, 위에서 아래로 파싱- 할당은 RL 파서이다. - 수학적인 컨텍스트로 정의되어있다.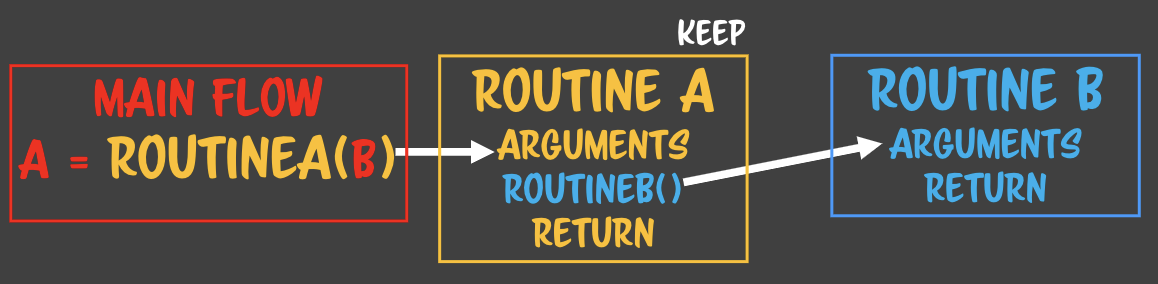 - 루틴A에서 루틴B가 호출될때 루틴A에서는
- 루틴A에서 루틴B가 호출될때 루틴A에서는 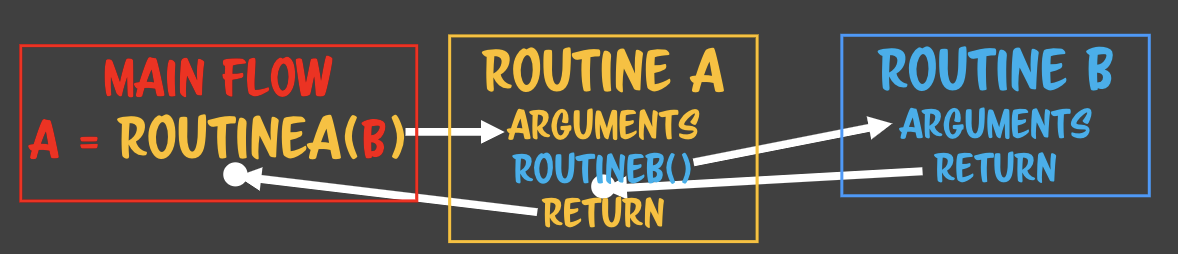

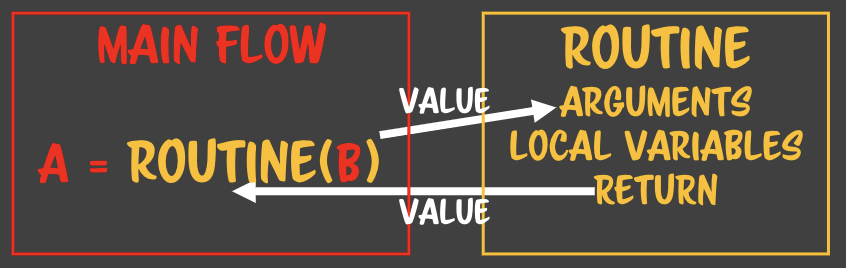
 - 하나의 루틴이 여러 flow를 상대하고 있어도 아무 문제가 생기지 않는다. - 복사본만 주고받기 때문에> 상태안정이라고 부른다. **State safe** - 수학적 프로그래밍의 기반이 된다. - 값을 컨택스트로 해서 함수형 프로그래밍을 하려고 한다. - 어디에서 누가 몇번을 부르던 상관없다. - 완전 수학적 함수라고 한다. - 때문에 처음 함수를 작성할 때 인자를 값으로 넘기는지부터 확인해보면 안전한 함수를 짤 수 있다.
- 하나의 루틴이 여러 flow를 상대하고 있어도 아무 문제가 생기지 않는다. - 복사본만 주고받기 때문에> 상태안정이라고 부른다. **State safe** - 수학적 프로그래밍의 기반이 된다. - 값을 컨택스트로 해서 함수형 프로그래밍을 하려고 한다. - 어디에서 누가 몇번을 부르던 상관없다. - 완전 수학적 함수라고 한다. - 때문에 처음 함수를 작성할 때 인자를 값으로 넘기는지부터 확인해보면 안전한 함수를 짤 수 있다. 
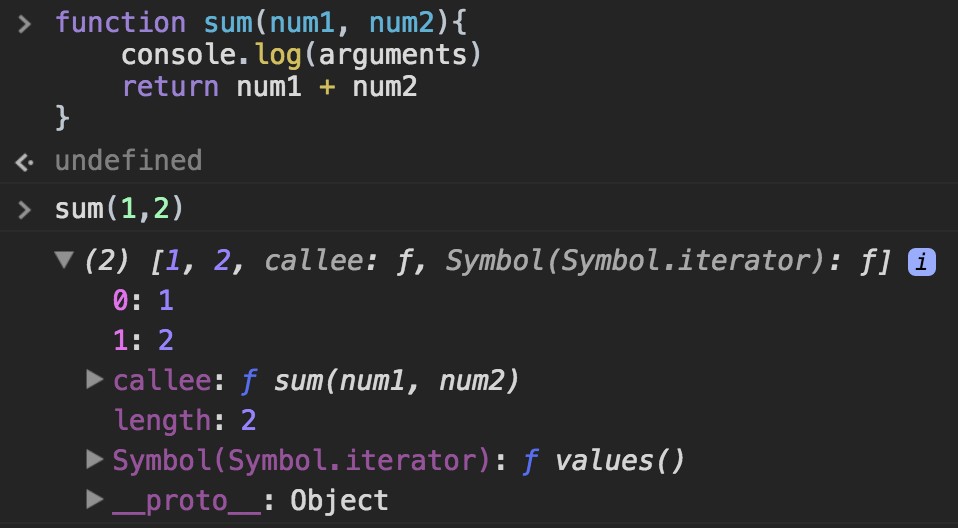
 - 함수 호출할 때 넘겨진 인자 (배열형태)- length : 인자갯수- callee : 현재 실행 중인 함수의 참조값
- 함수 호출할 때 넘겨진 인자 (배열형태)- length : 인자갯수- callee : 현재 실행 중인 함수의 참조값
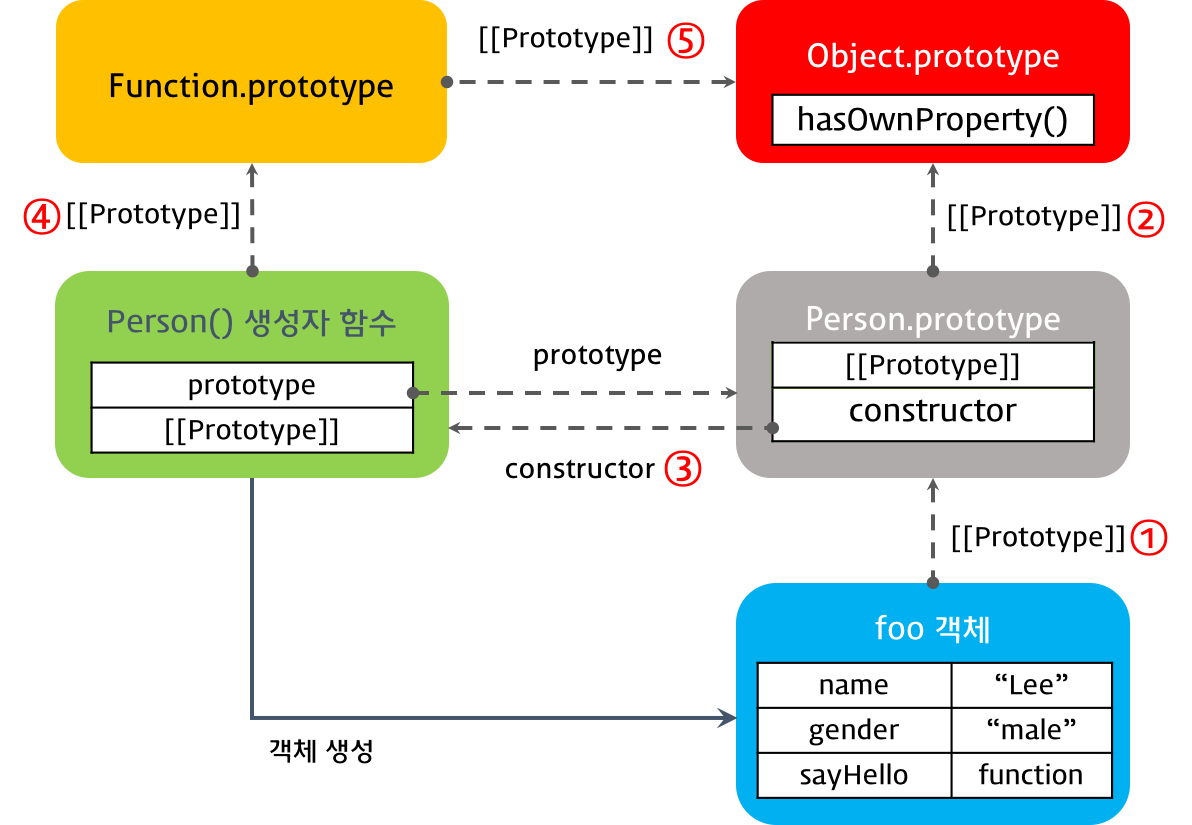


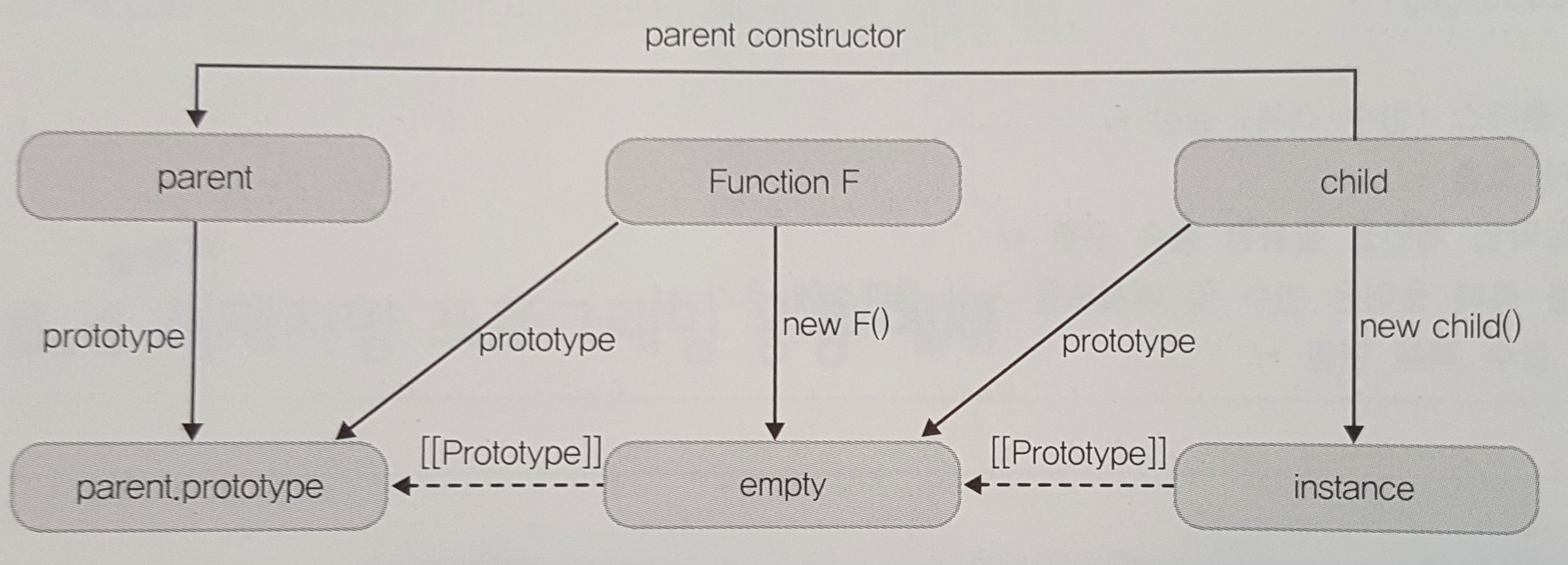
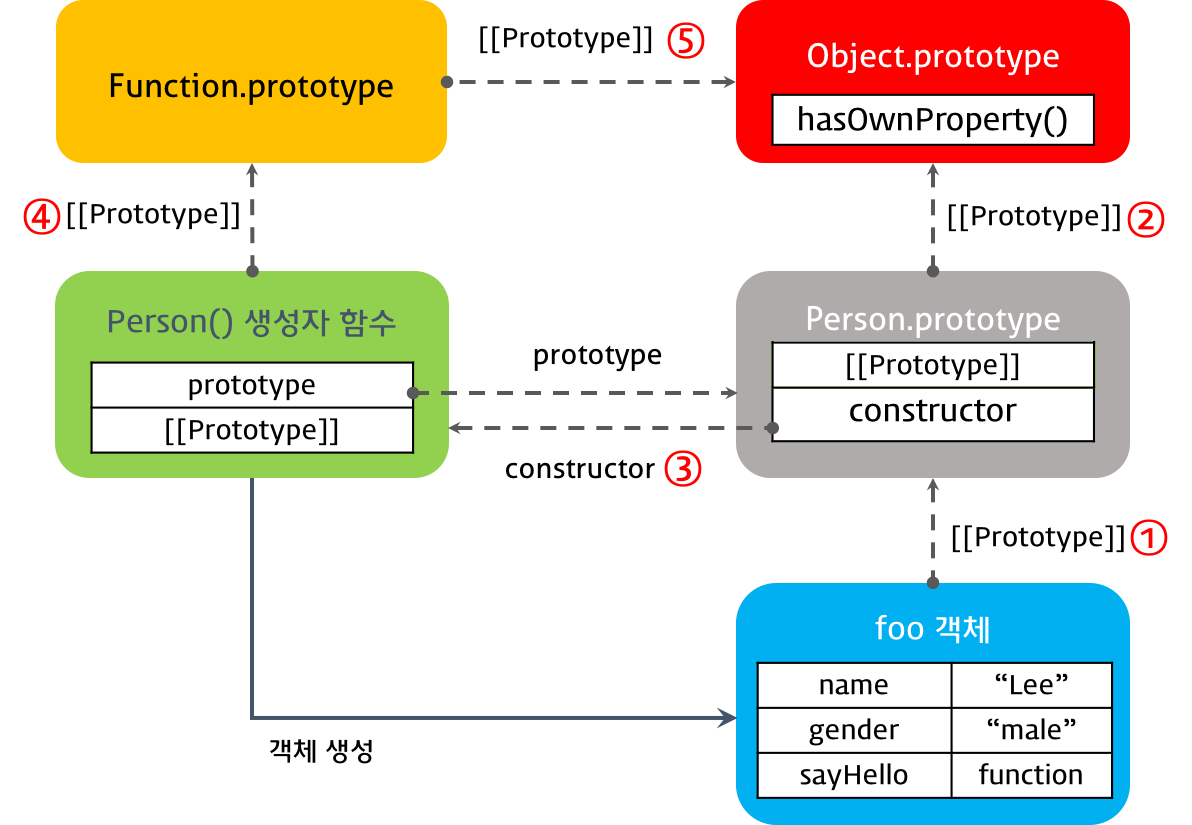 > (이미지출처 : https://poiemaweb.com/js-prototype)
> (이미지출처 : https://poiemaweb.com/js-prototype)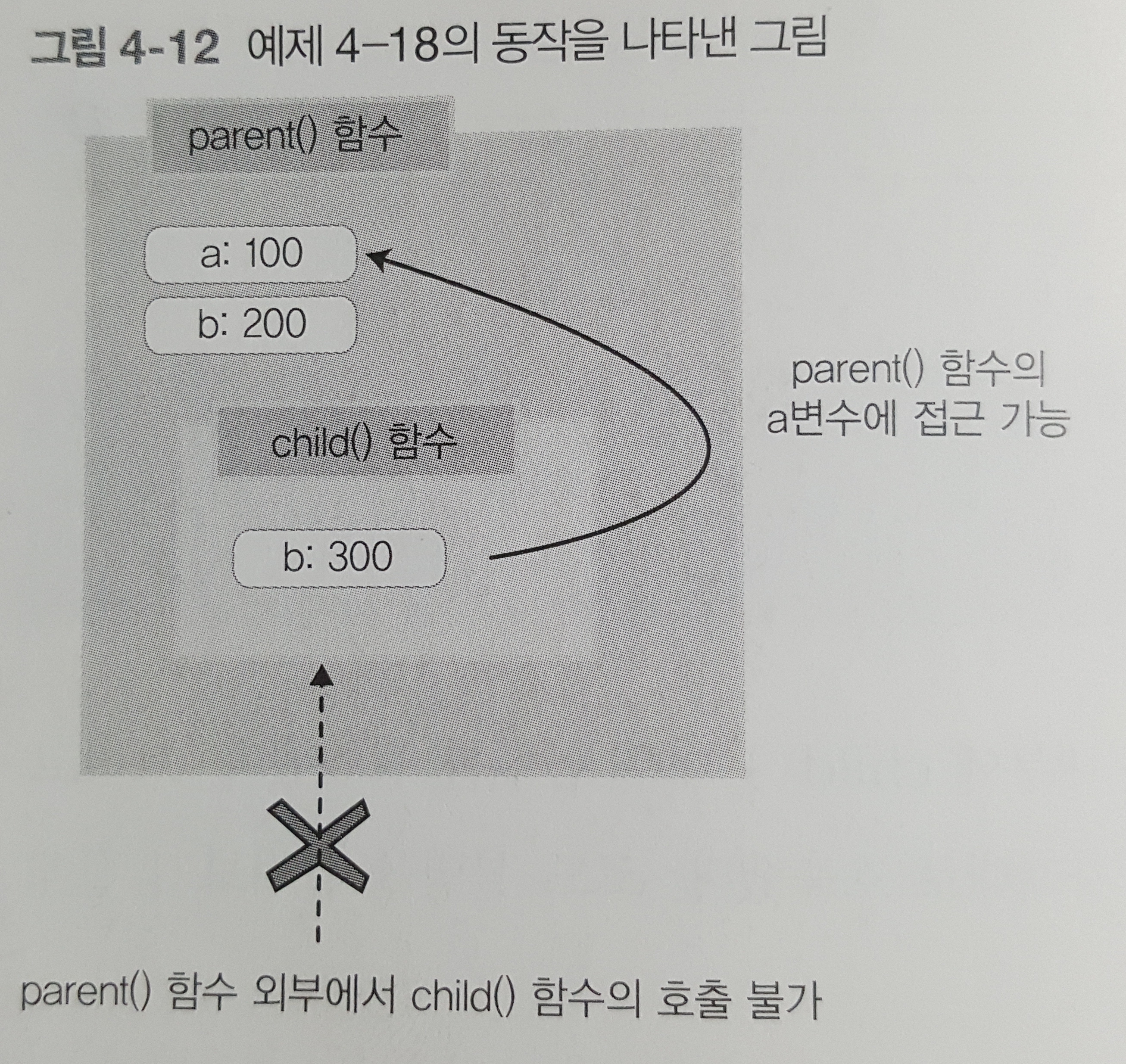
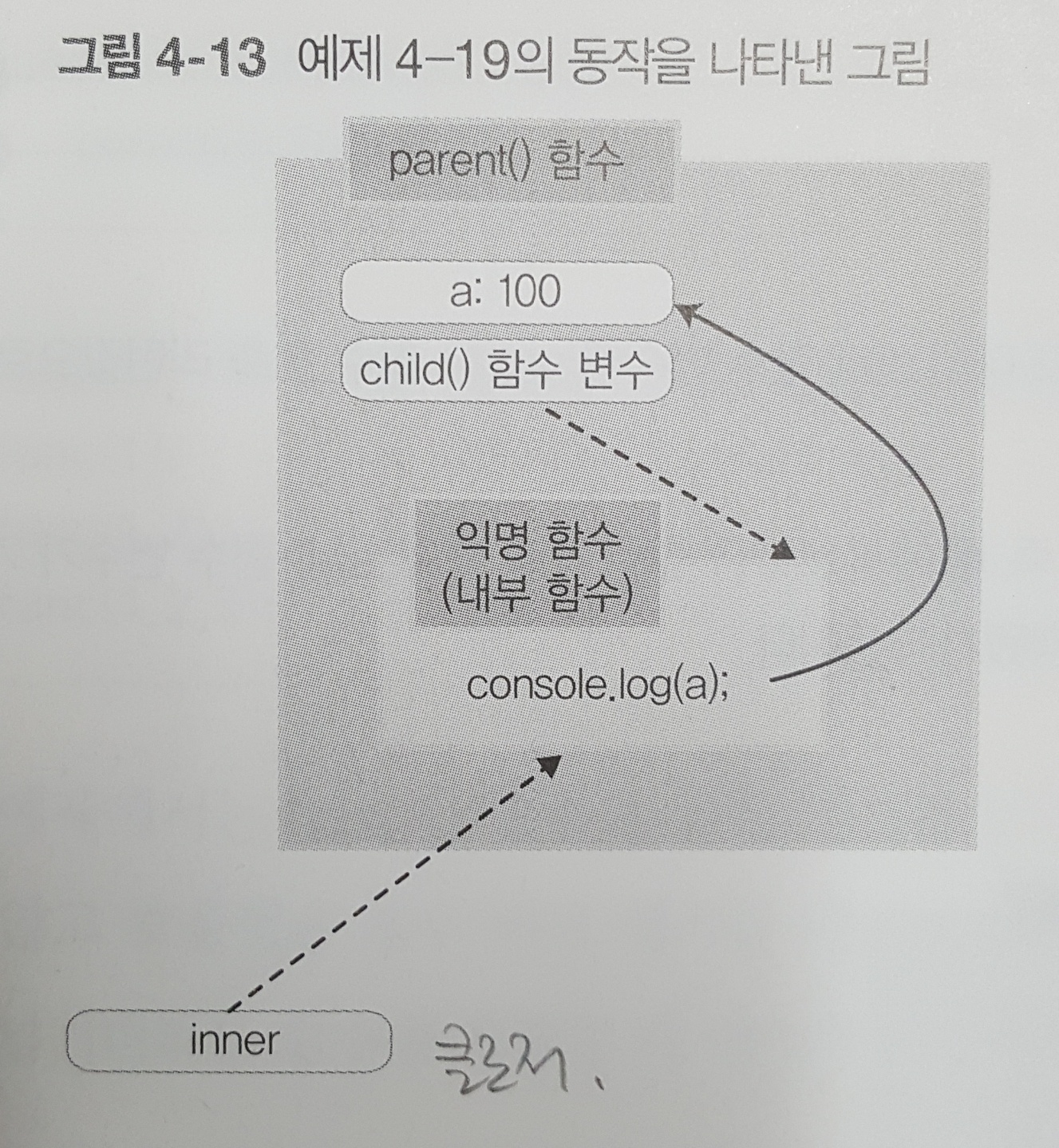

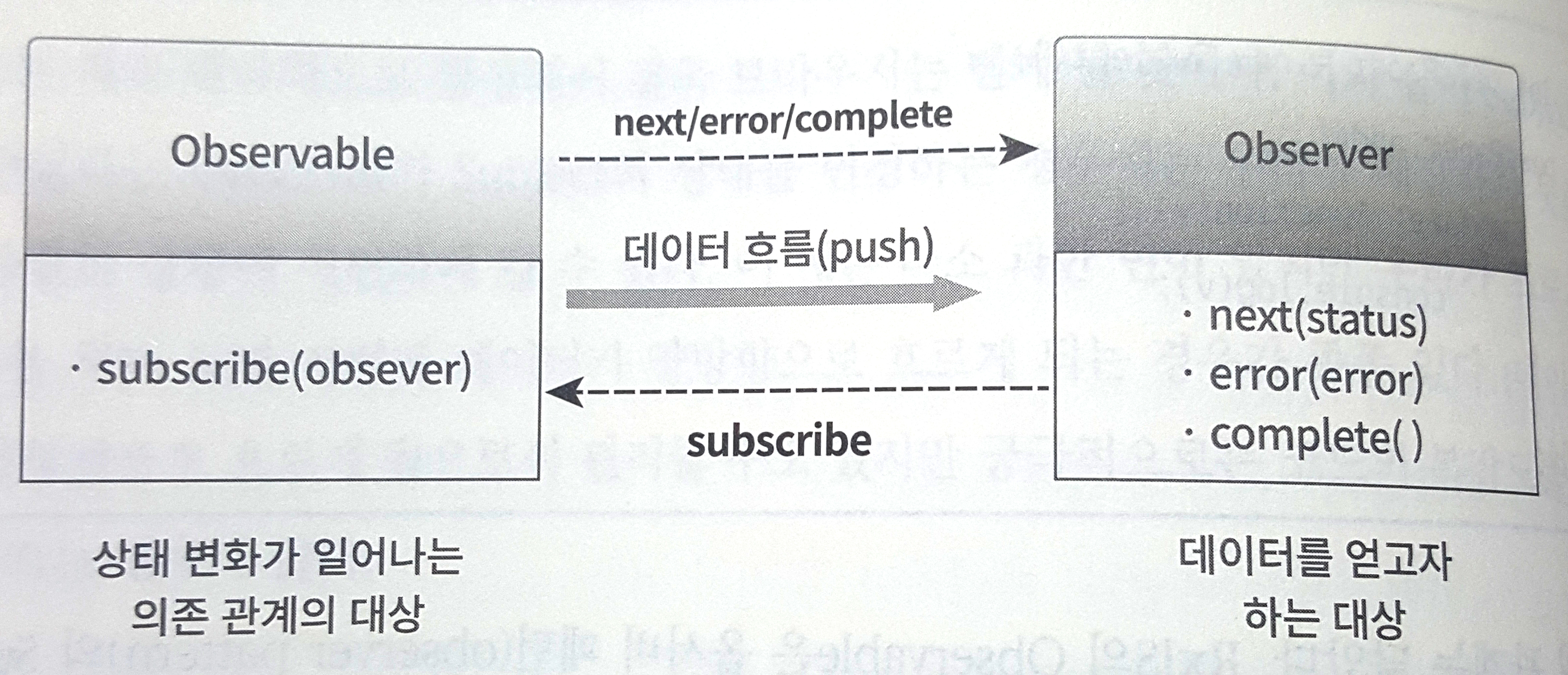 > rxjs
> rxjs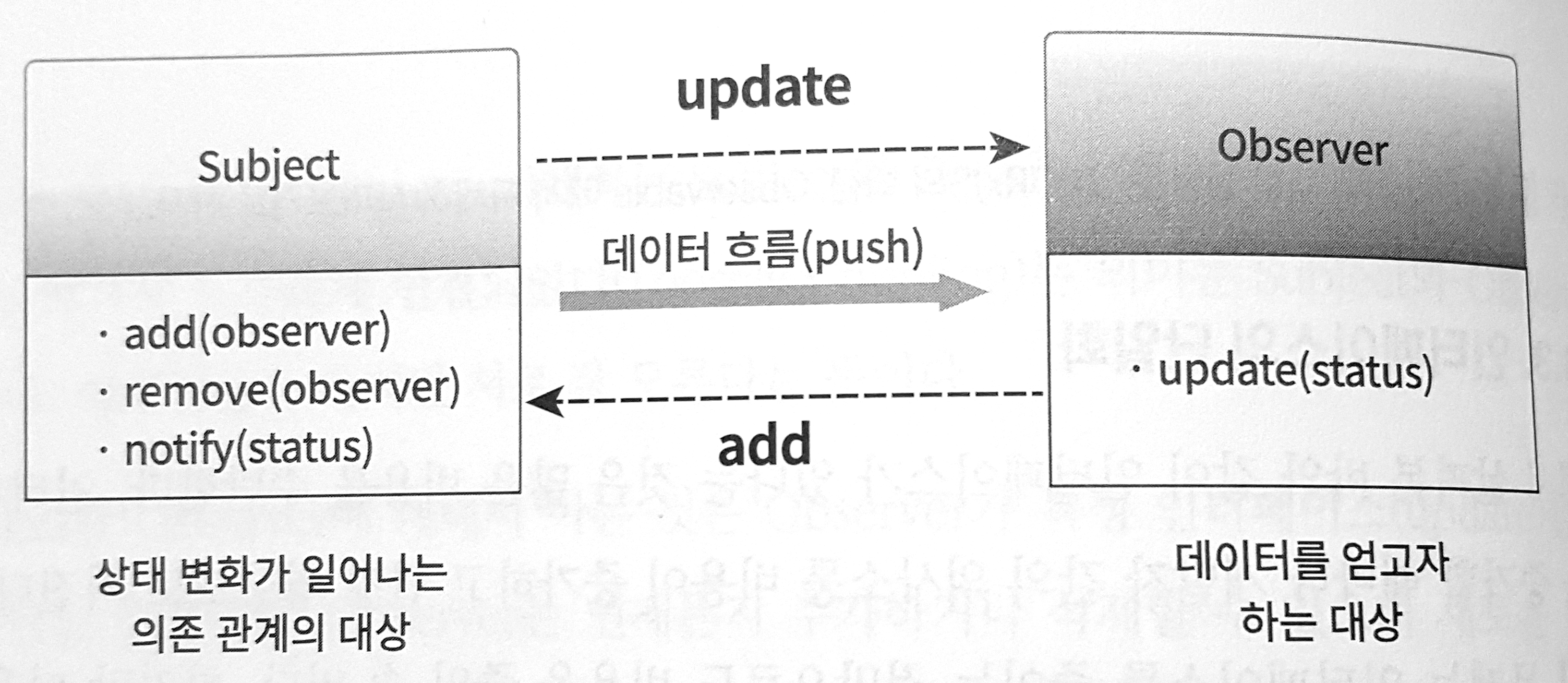 > 옵저버패턴
> 옵저버패턴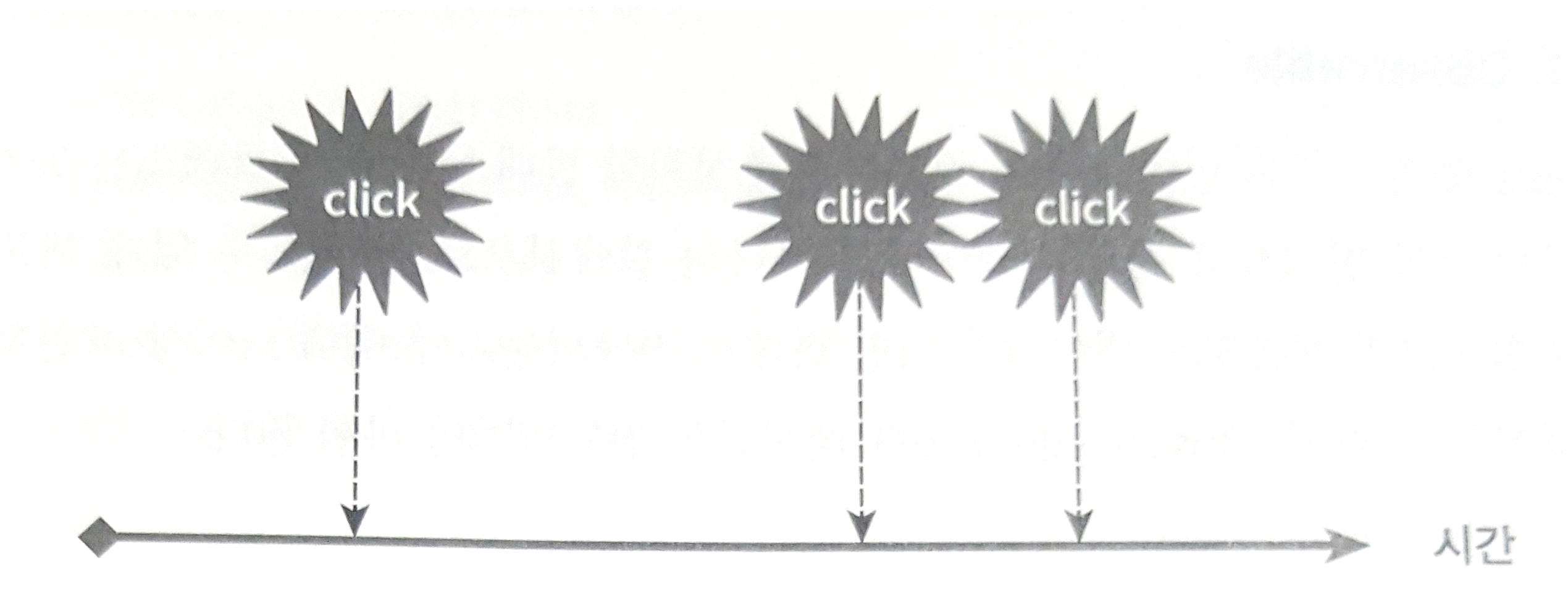 > 비동기
> 비동기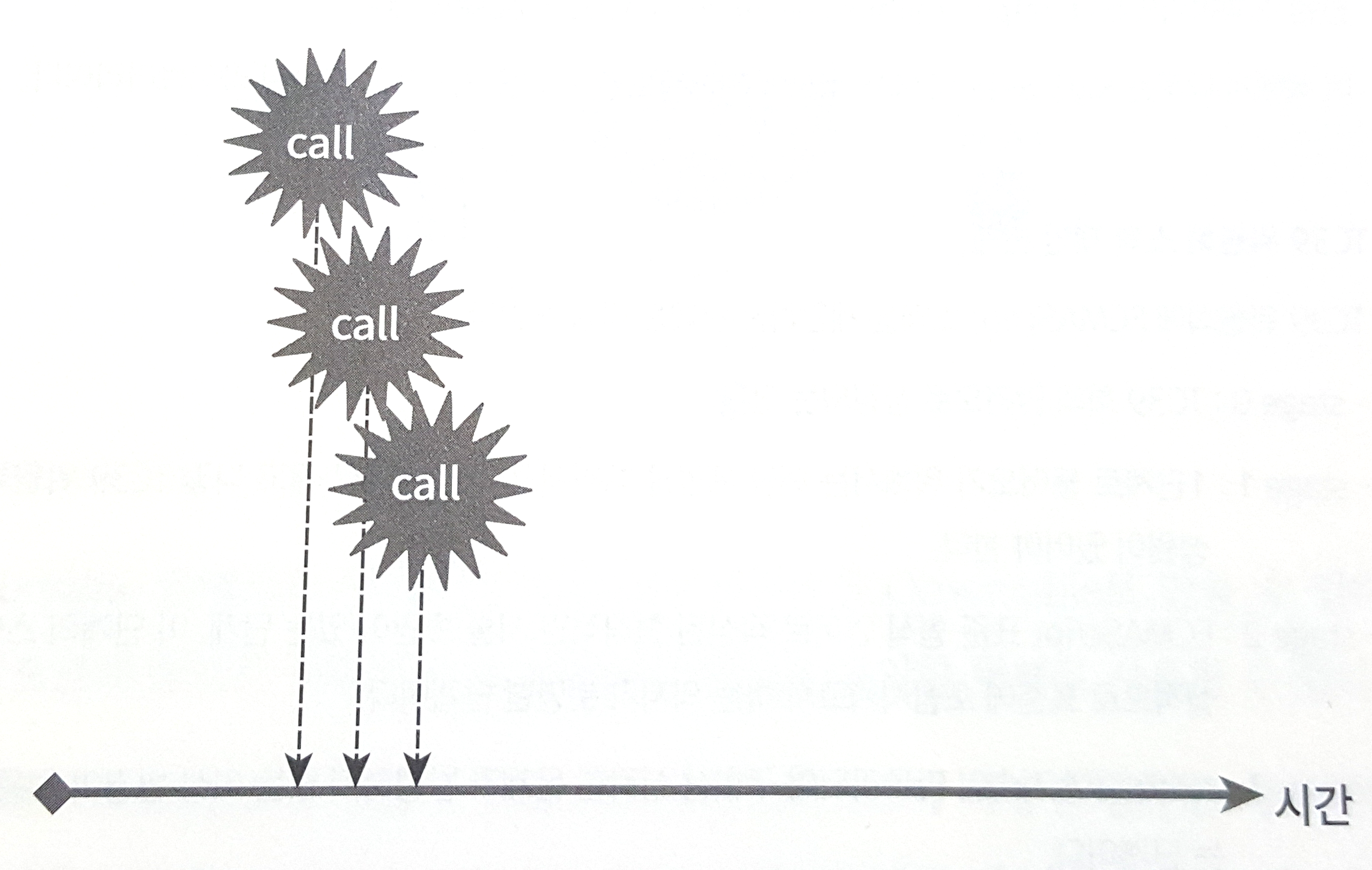 > 동기
> 동기
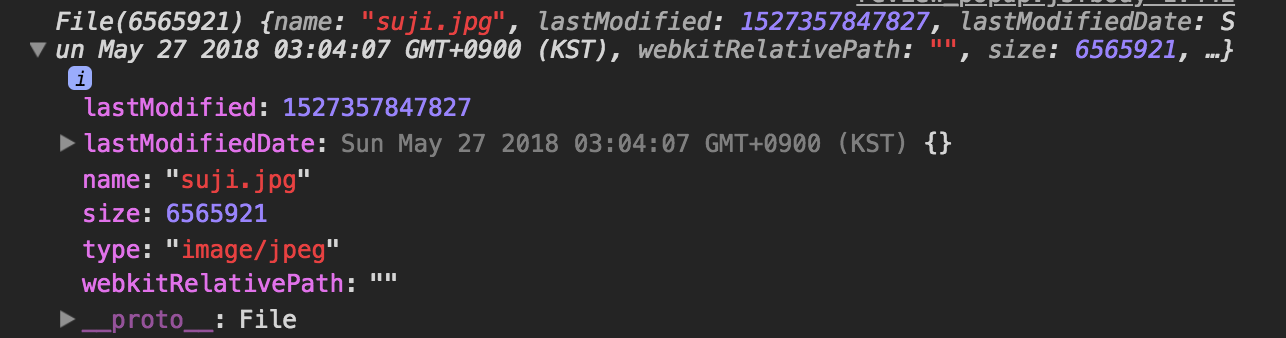
 fileList => file => binary Data => exif의 주소값을 찾아서 사진 정보를 get해오기(exif라는 라이브러리를 들춰보면 재밌는 것이!!많습니다.)
fileList => file => binary Data => exif의 주소값을 찾아서 사진 정보를 get해오기(exif라는 라이브러리를 들춰보면 재밌는 것이!!많습니다.)
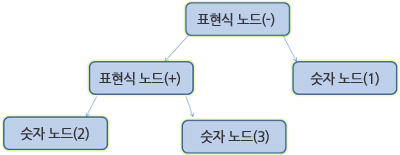 2 + 3 - 1
2 + 3 - 1
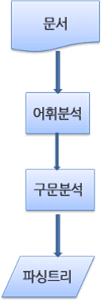

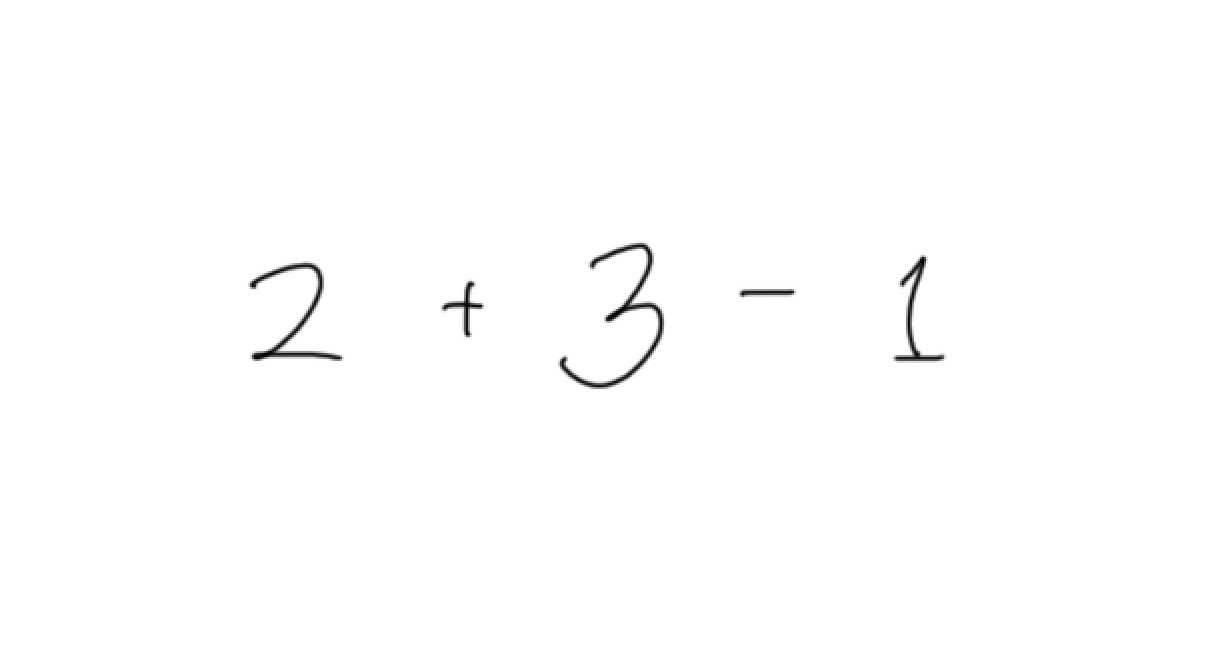

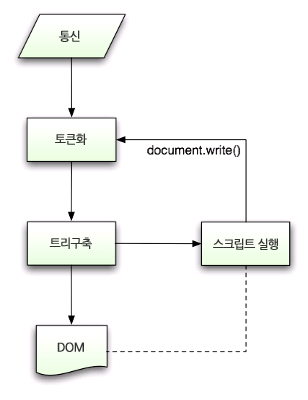

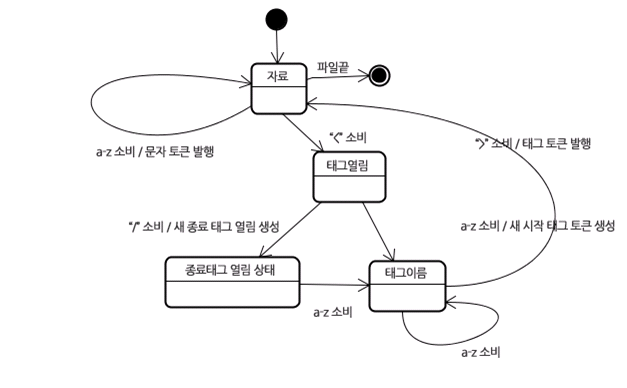
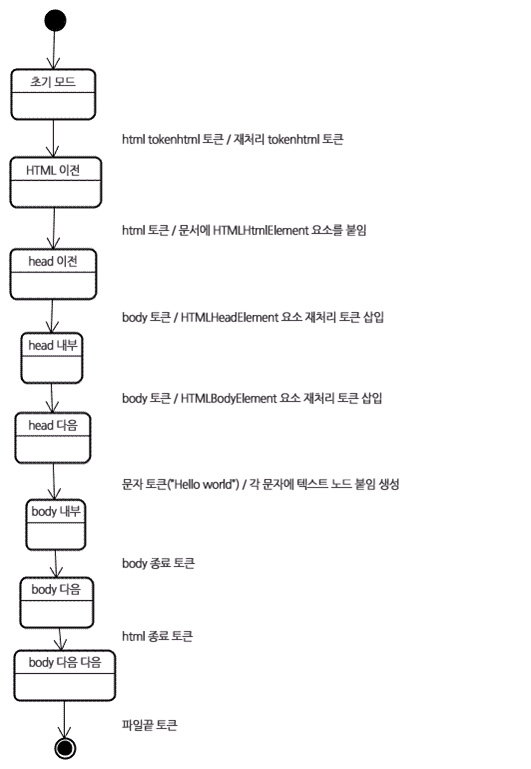
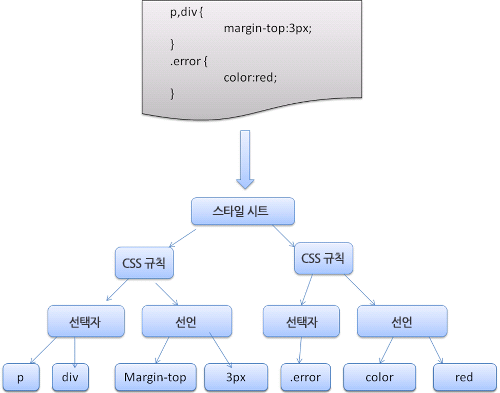
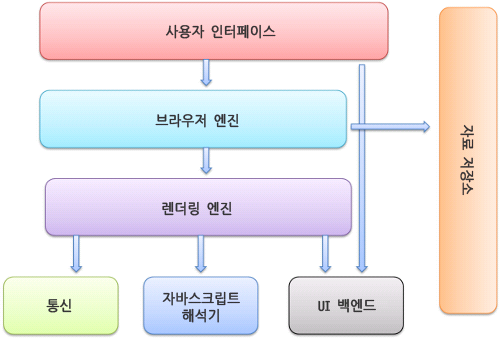
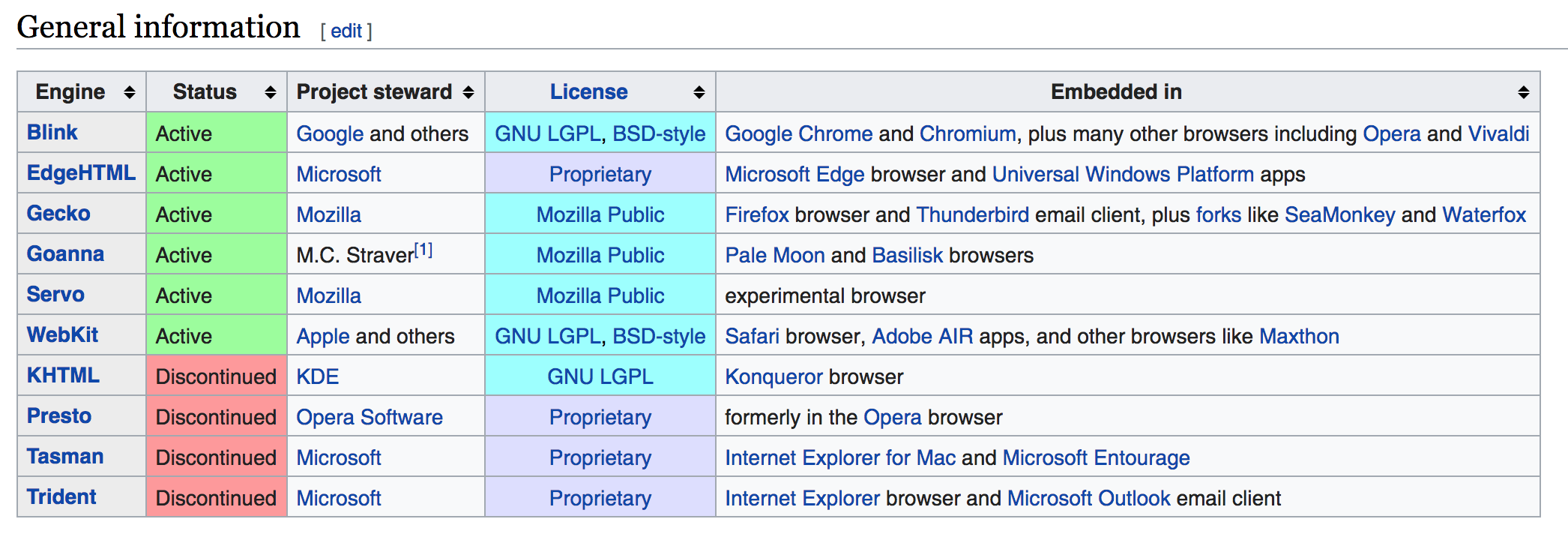
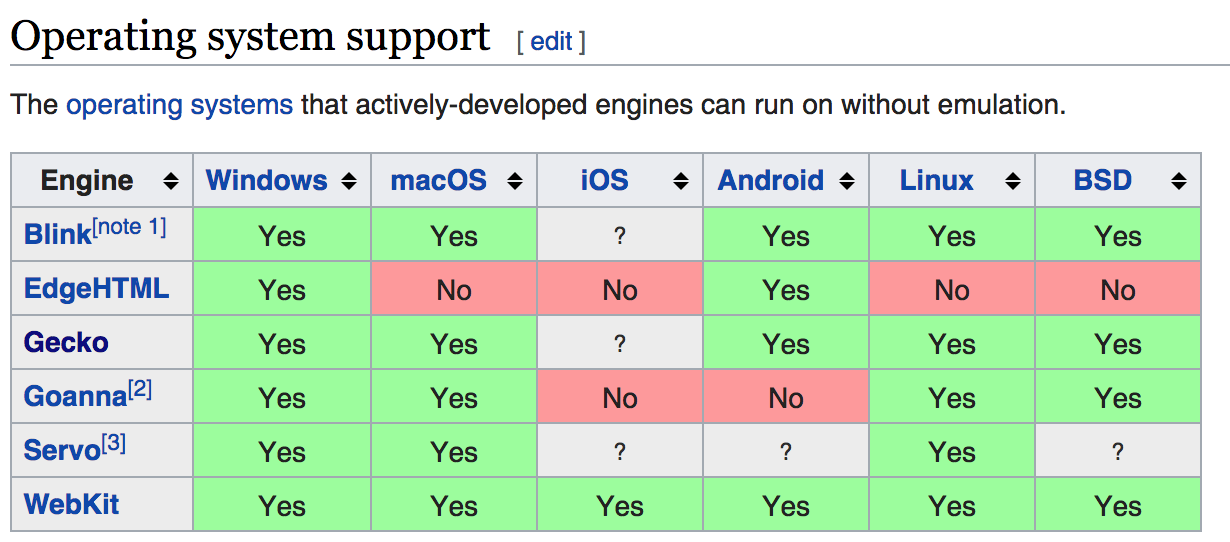
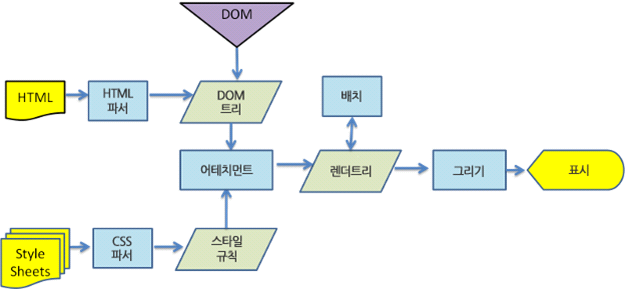
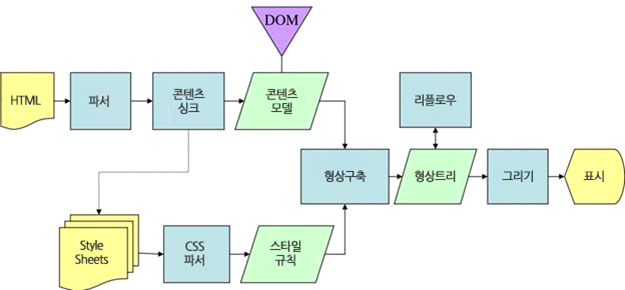 - 형상트리(frame tree) : 시각적으로 처리되는 렌더 트리- 형상(frame) : 형상- 배치라는 뜻으로 리플로(`reflow`)라는 용어를 사용- 콘텐츠 싱크 (content sink) : DOM 요소를 생성하는 공정
- 형상트리(frame tree) : 시각적으로 처리되는 렌더 트리- 형상(frame) : 형상- 배치라는 뜻으로 리플로(`reflow`)라는 용어를 사용- 콘텐츠 싱크 (content sink) : DOM 요소를 생성하는 공정



.png)


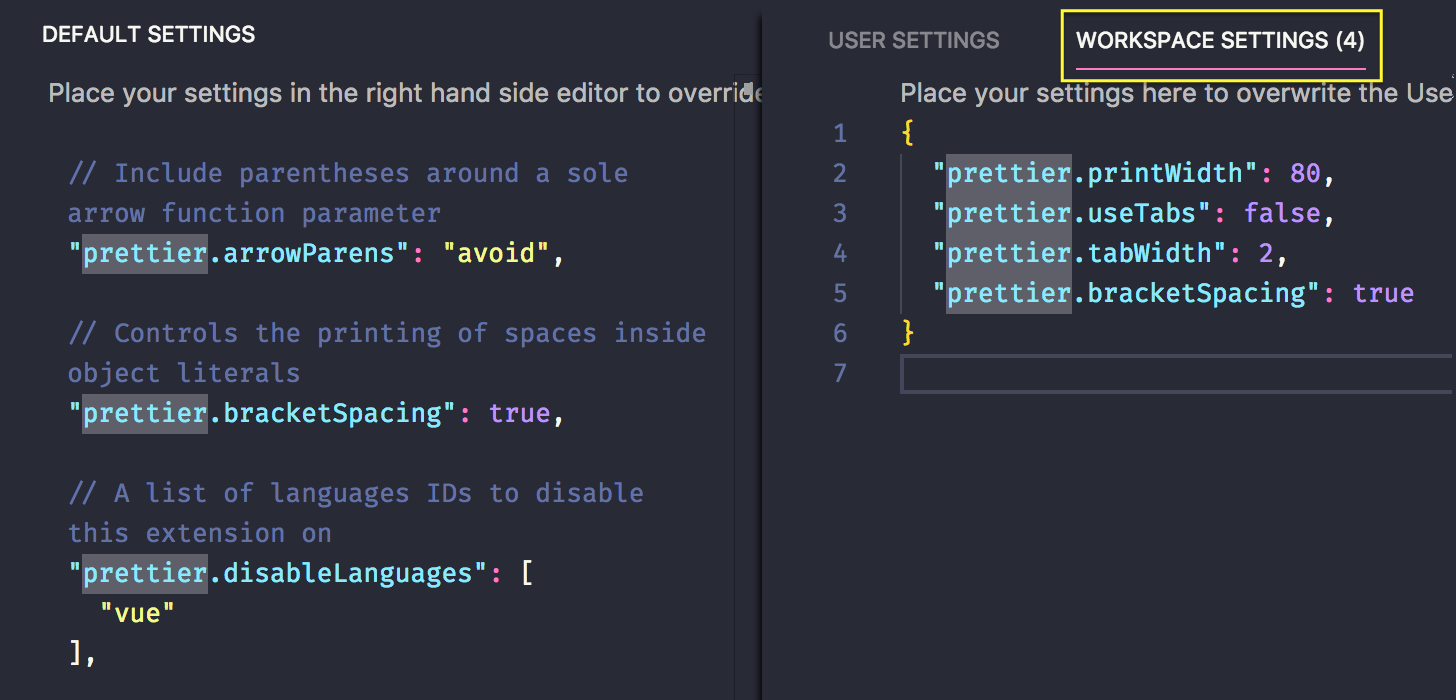 위처럼 폴더가 생성된다. 폴더를 팀원들과 공유해도 괜찮고, 혹은 아래 옵션 객체만 팀 내의 docs에 공유해도 괜찮다. (나중에 들어올 팀원이 vscode를 쓴다는 전제가 있어야..ㅎ)
위처럼 폴더가 생성된다. 폴더를 팀원들과 공유해도 괜찮고, 혹은 아래 옵션 객체만 팀 내의 docs에 공유해도 괜찮다. (나중에 들어올 팀원이 vscode를 쓴다는 전제가 있어야..ㅎ)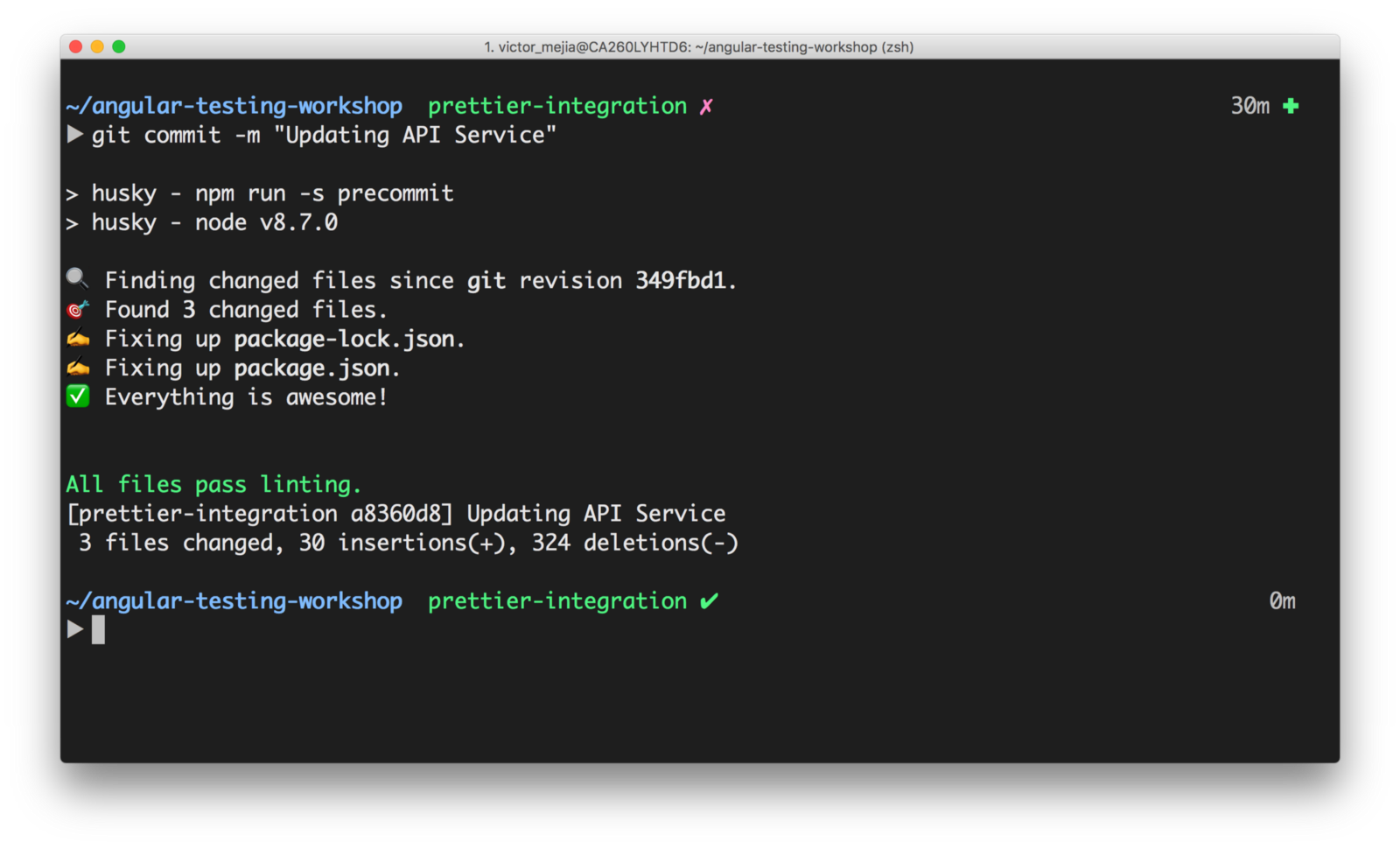
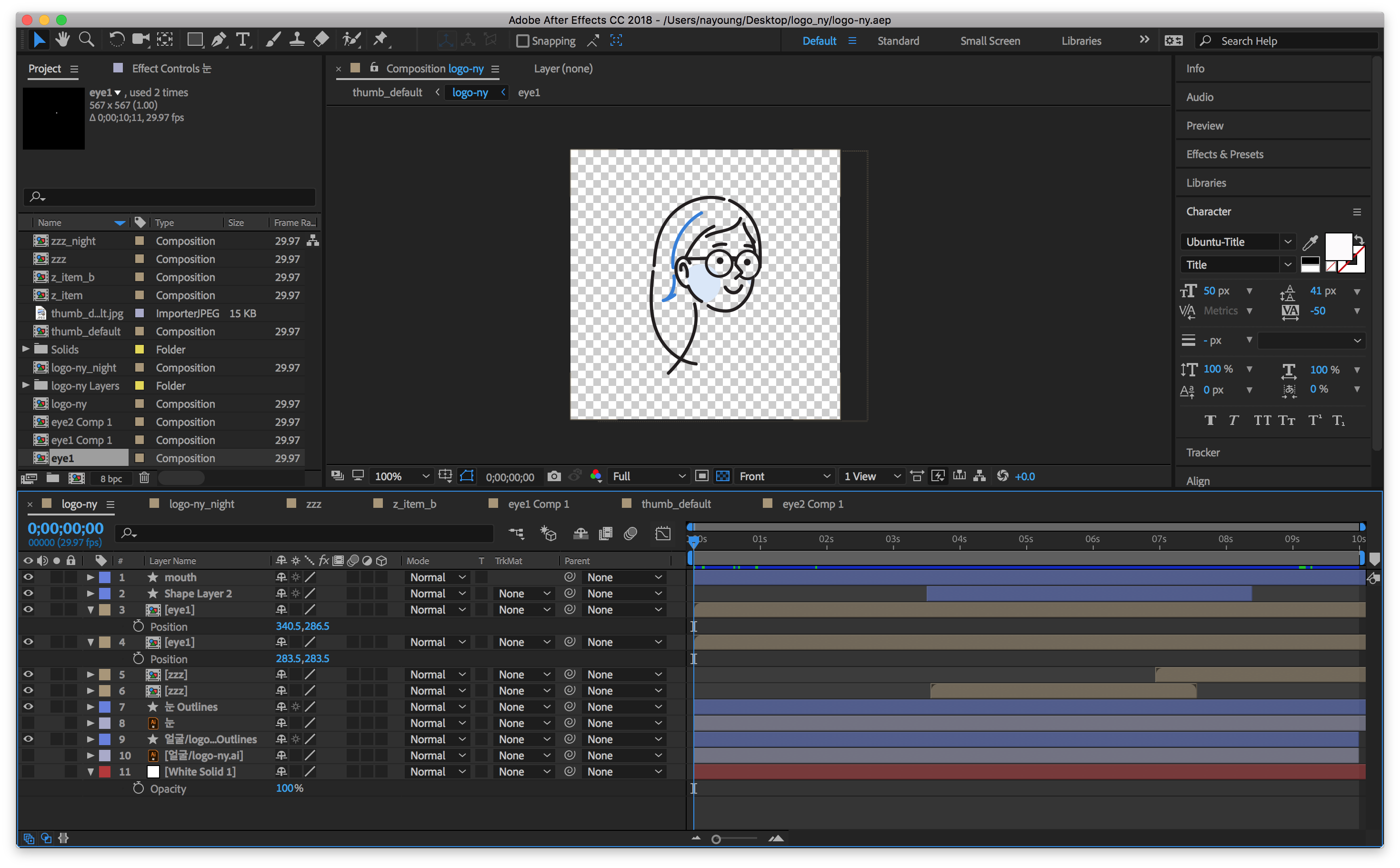
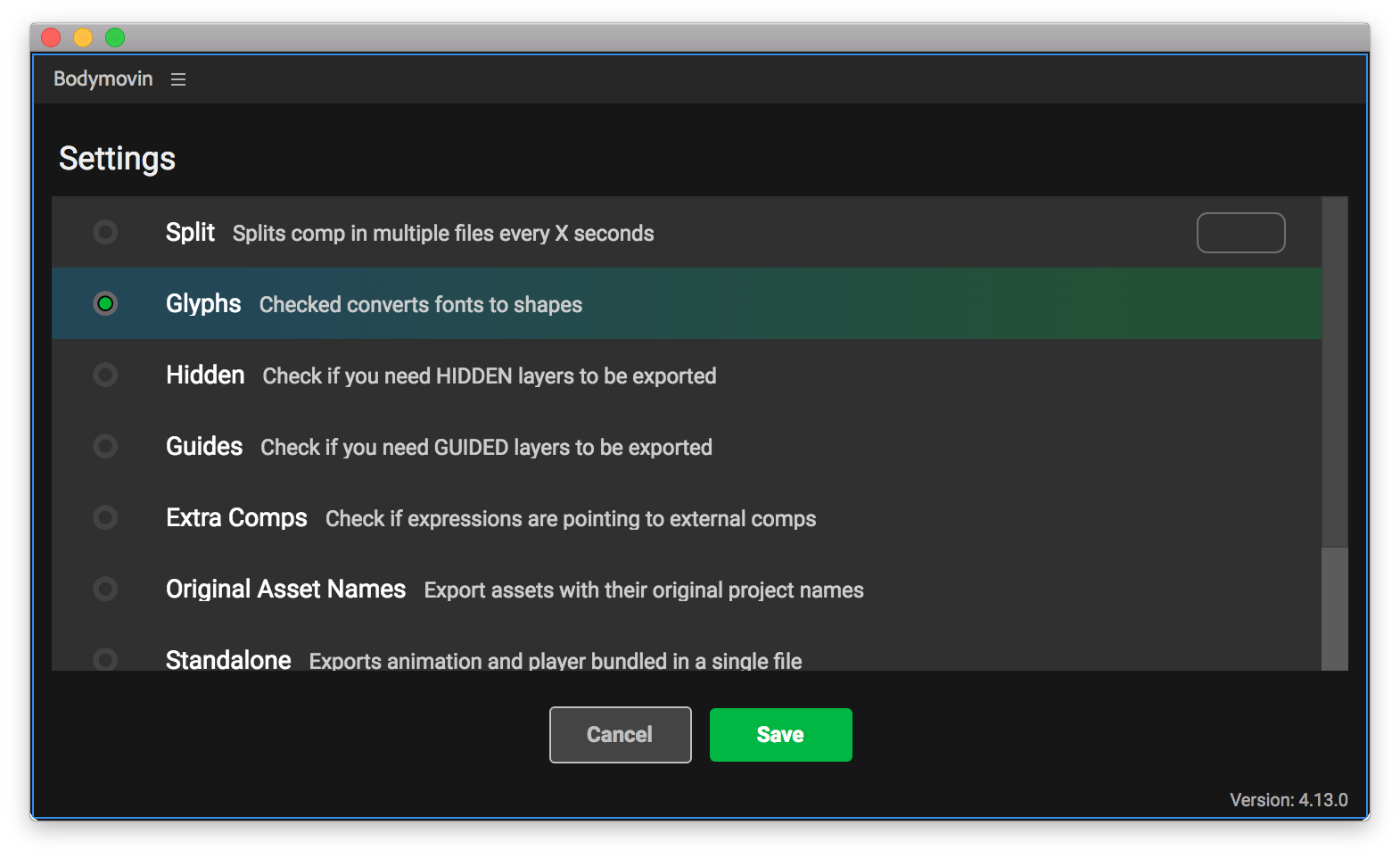
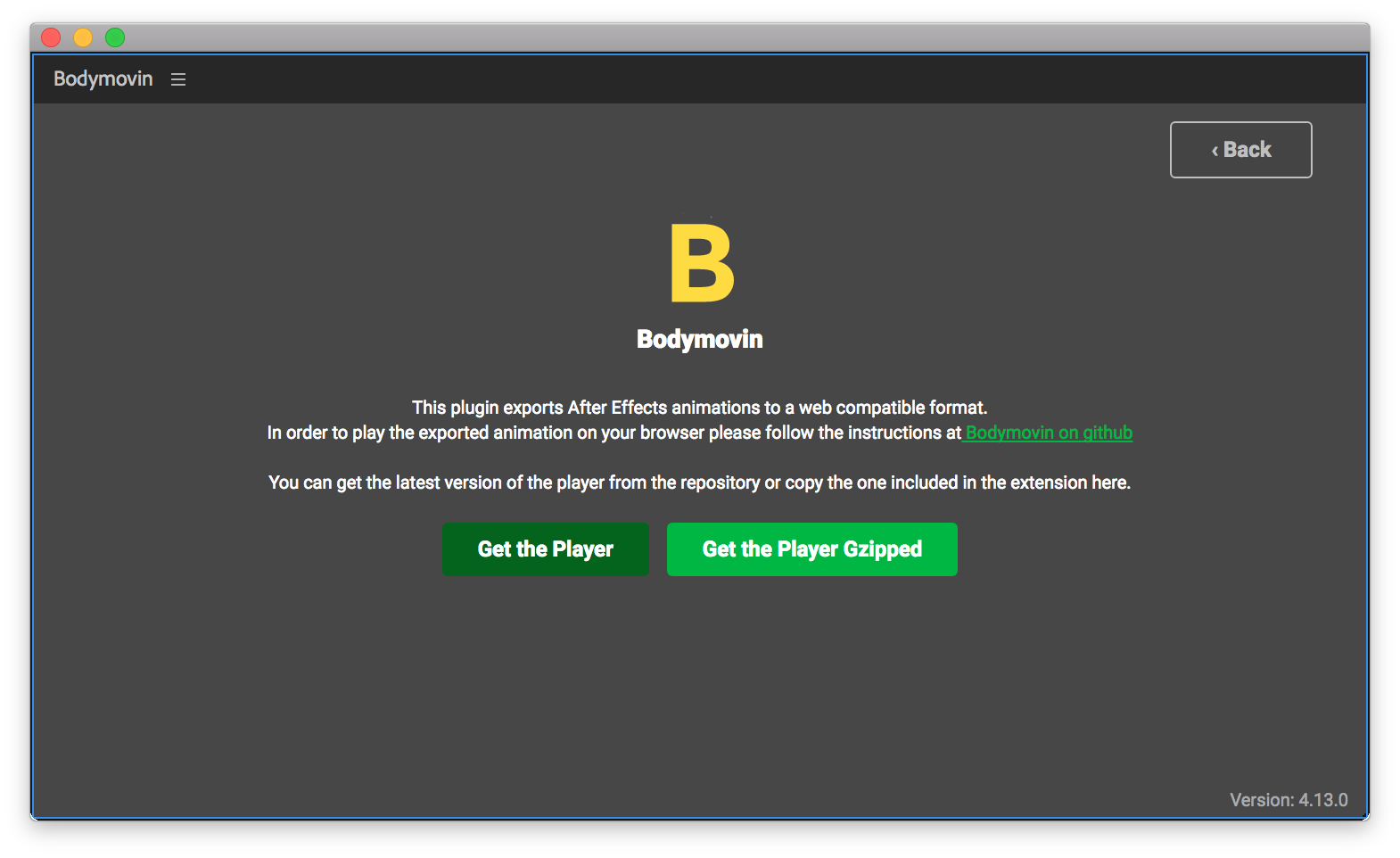
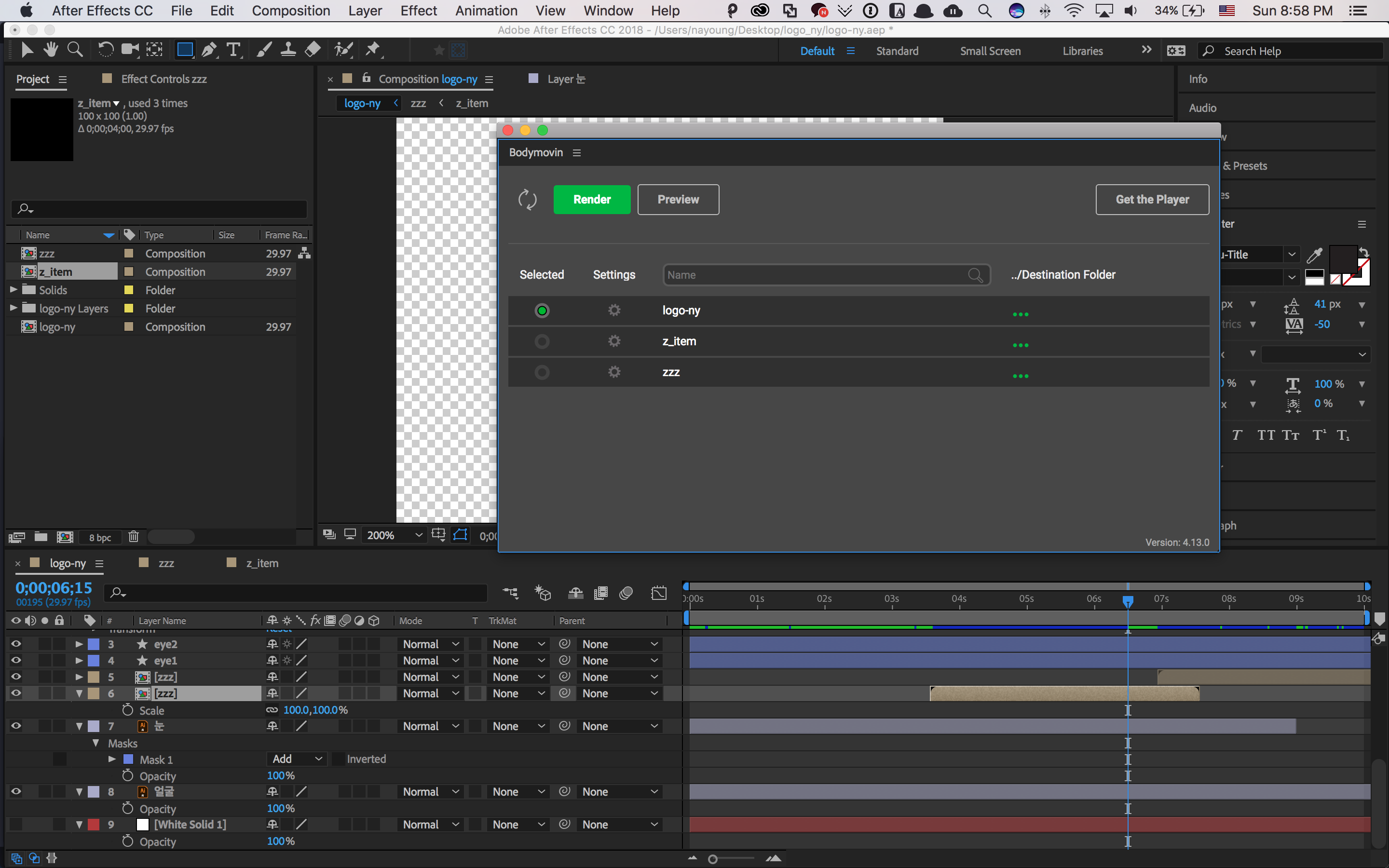 에펙에서 "Window > Extensions"의 "Bodymovin"를 오픈하면 위의 그림처럼 창이 하나 오픈됩니다. 우리가 필요한 파일은 `json`파일과 `js`파일입니다.
에펙에서 "Window > Extensions"의 "Bodymovin"를 오픈하면 위의 그림처럼 창이 하나 오픈됩니다. 우리가 필요한 파일은 `json`파일과 `js`파일입니다.
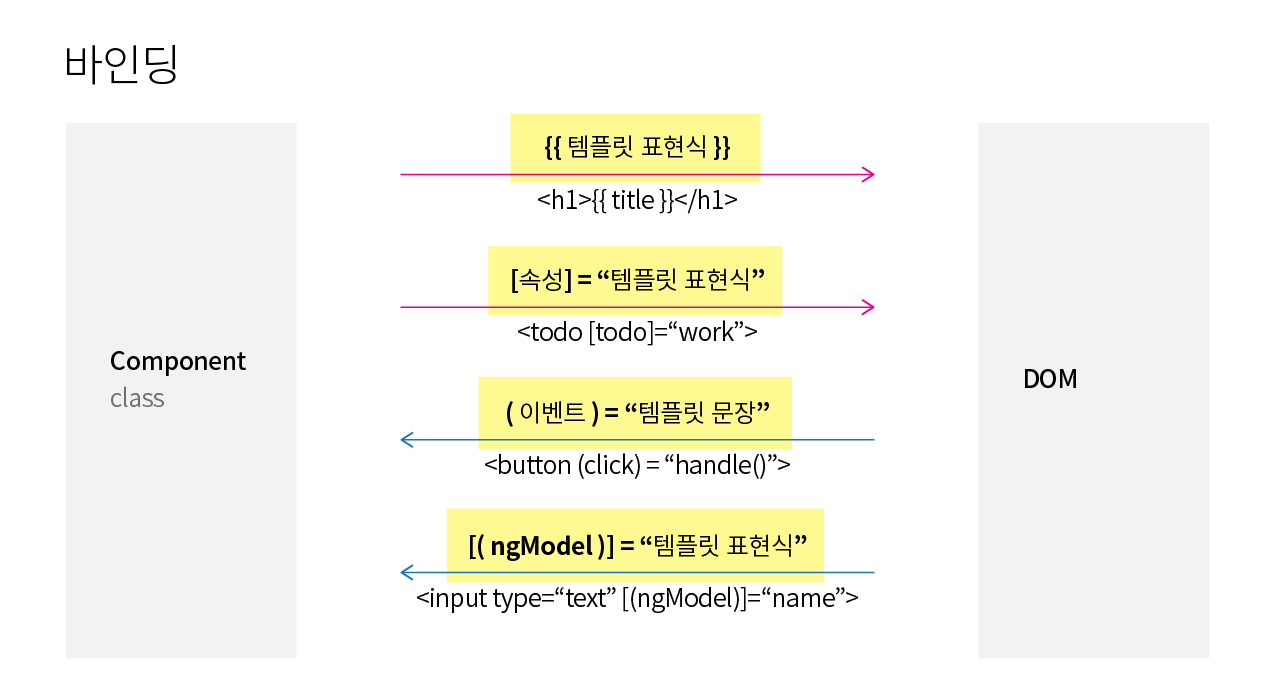
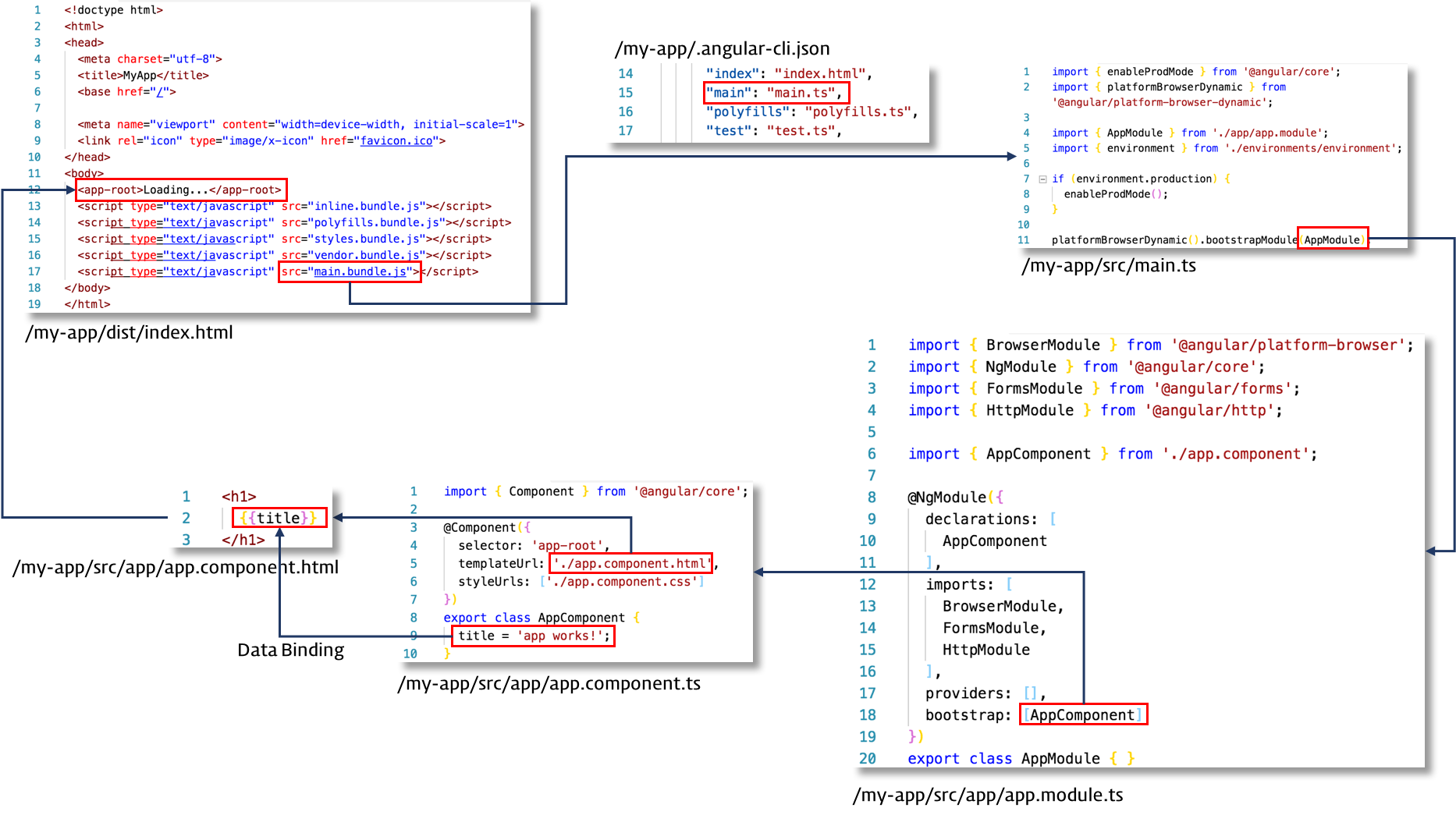 > Anuglar 어플리케이션의 흐름 [+](http://poiemaweb.com/angular-architecture)
> Anuglar 어플리케이션의 흐름 [+](http://poiemaweb.com/angular-architecture)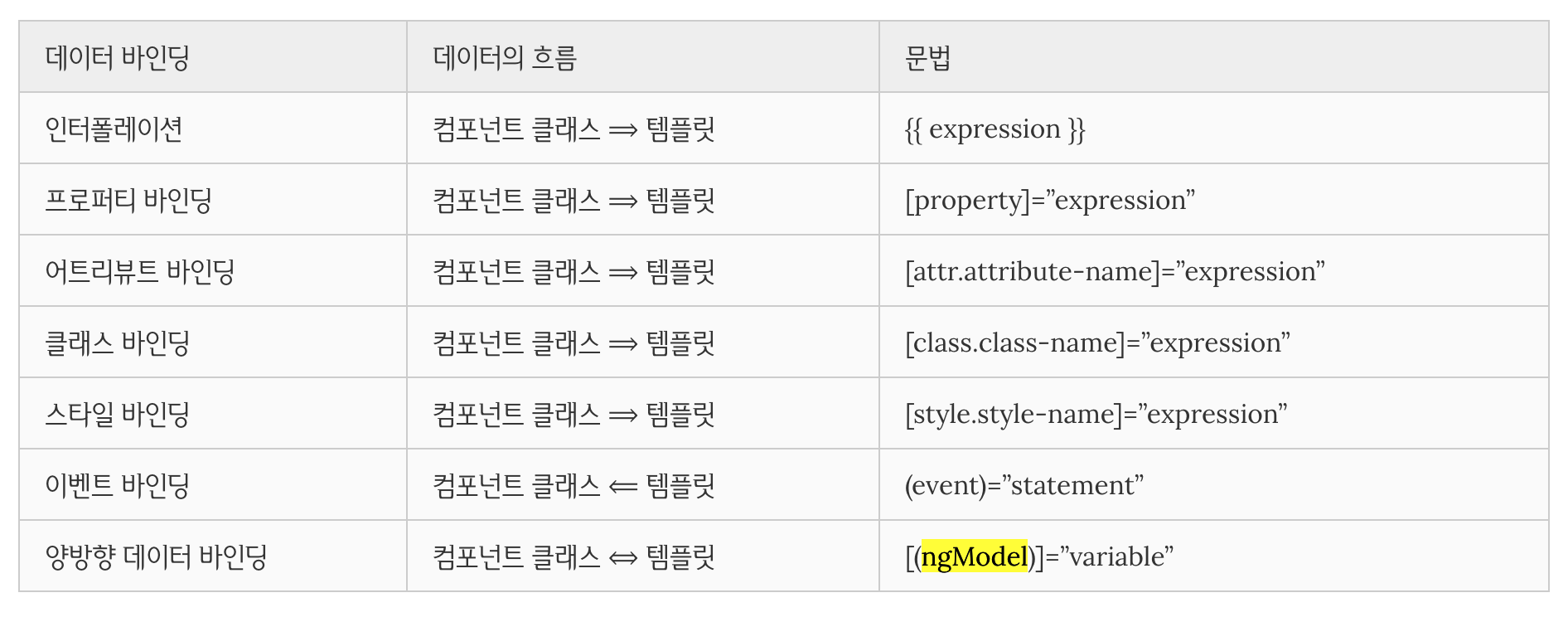
 `RegExp.prototype.exec(text)` : `RegExp.prototype.test(text)` : boolean값이 반환된다.`String.prototype.match(rxgexr)` : 매치되는 문자열들을 반환한다. `String.prototype.replace(rxgexr, '')` : 첫번째 인자로 찾아진 문자열을 두번째 인자로 교체한다.`String.prototype.search(rxgexr)` : 배열의 길이`String.prototype.split(rxgexr)` : 인자값을 제외하고, 인자값을 기준으로 split된 배열이 반환됨.
`RegExp.prototype.exec(text)` : `RegExp.prototype.test(text)` : boolean값이 반환된다.`String.prototype.match(rxgexr)` : 매치되는 문자열들을 반환한다. `String.prototype.replace(rxgexr, '')` : 첫번째 인자로 찾아진 문자열을 두번째 인자로 교체한다.`String.prototype.search(rxgexr)` : 배열의 길이`String.prototype.split(rxgexr)` : 인자값을 제외하고, 인자값을 기준으로 split된 배열이 반환됨.
 > 하 넘나 넘어가고싶었던 빨간색이었따..
> 하 넘나 넘어가고싶었던 빨간색이었따..

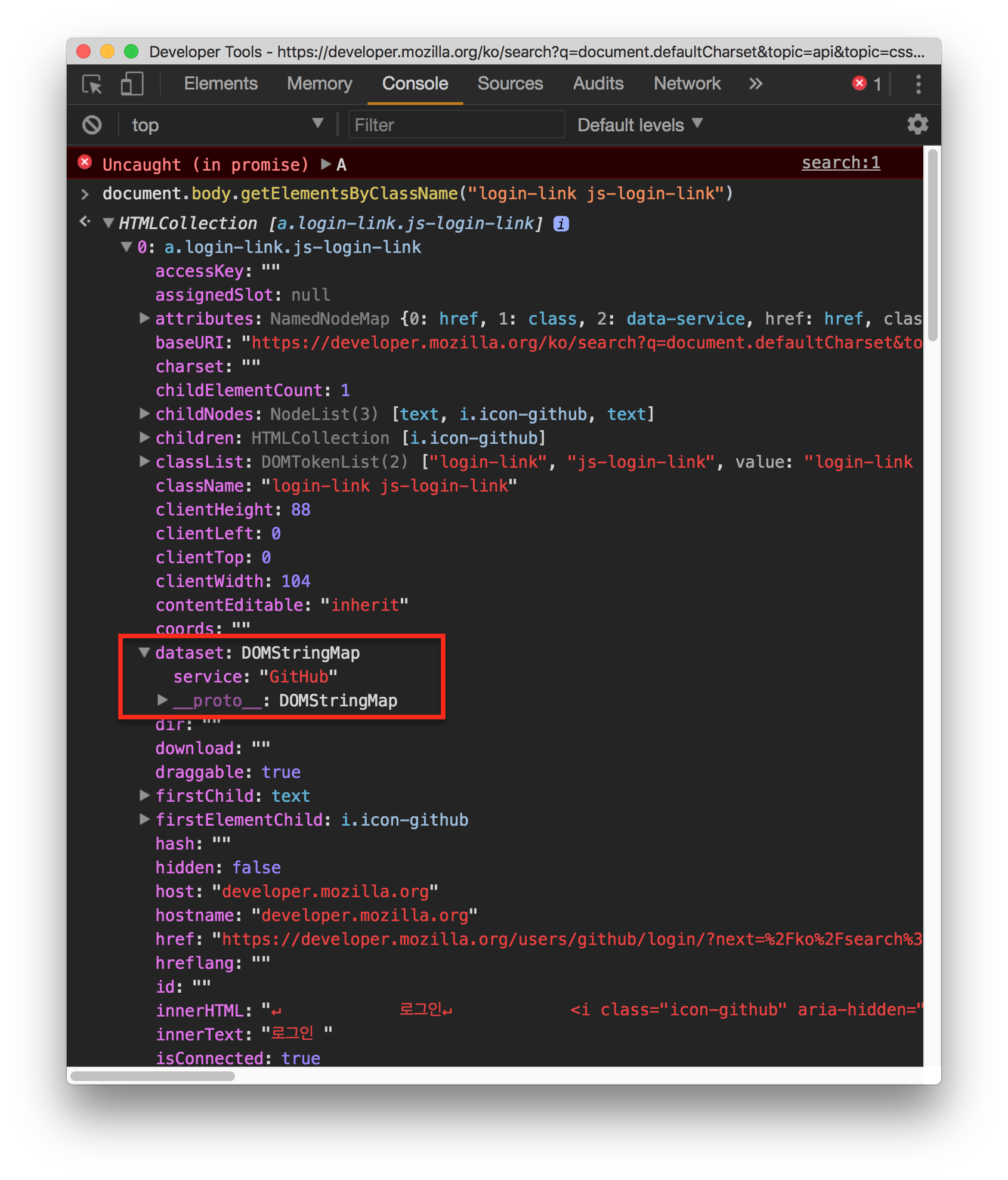

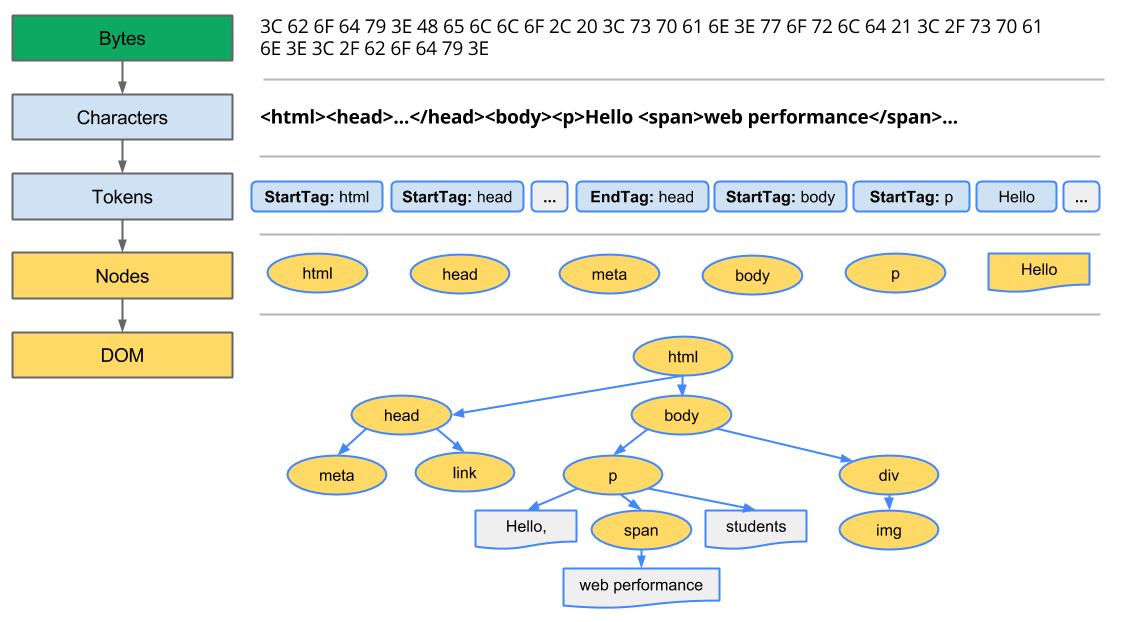
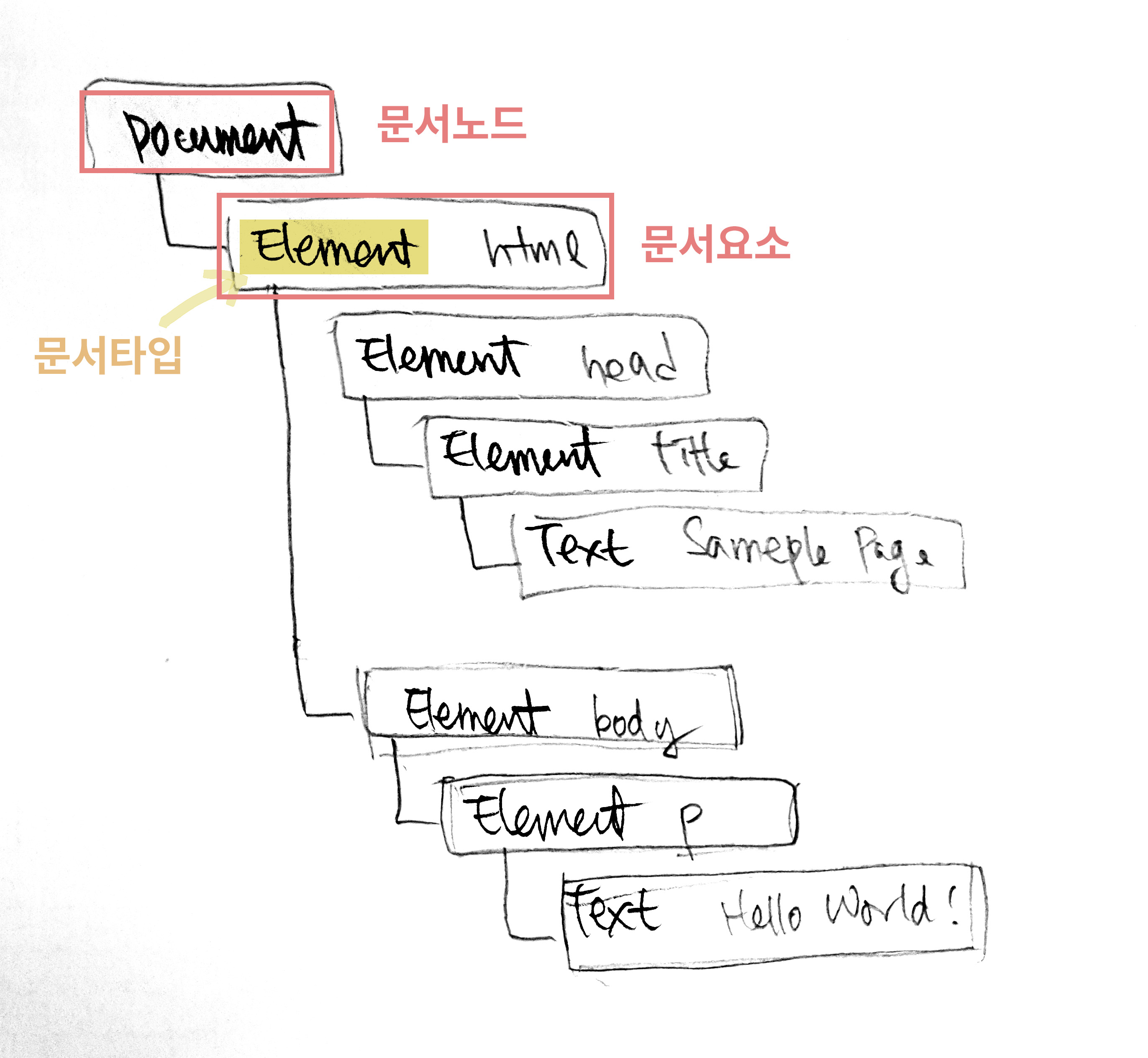 - 여기서 문서(Document) 노드가 루트이다.- 문서 요소 : 문서 노드의 자식. 여기서는 `` - 문서 하나에 문서 요소 하나만 있을 수 있다. - HTML페이지에서 문서요소는 항상 `` 요소이다.- 각 마크업은 트리에서 노드로 표현된다.- 총 12가지 노드 타입이 있으며 모든 노드틑 `기반 타입`(base type)을 상속한다.
- 여기서 문서(Document) 노드가 루트이다.- 문서 요소 : 문서 노드의 자식. 여기서는 `` - 문서 하나에 문서 요소 하나만 있을 수 있다. - HTML페이지에서 문서요소는 항상 `` 요소이다.- 각 마크업은 트리에서 노드로 표현된다.- 총 12가지 노드 타입이 있으며 모든 노드틑 `기반 타입`(base type)을 상속한다.
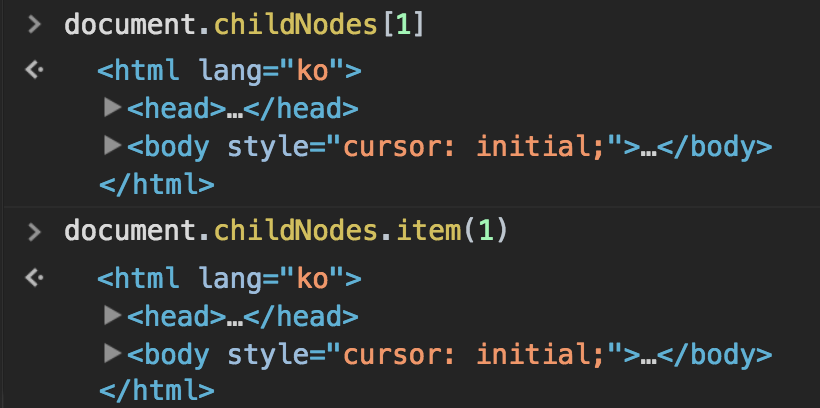

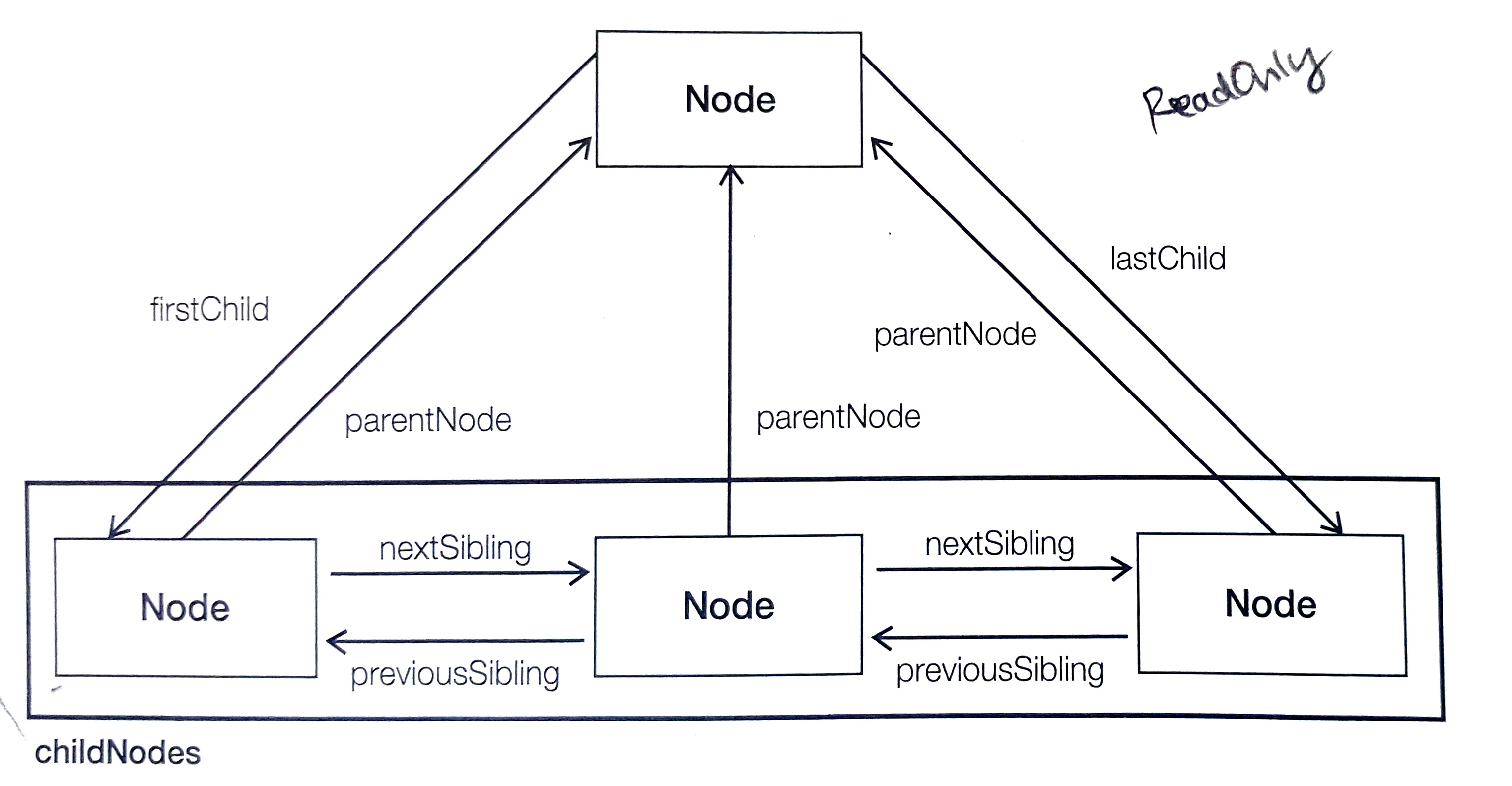
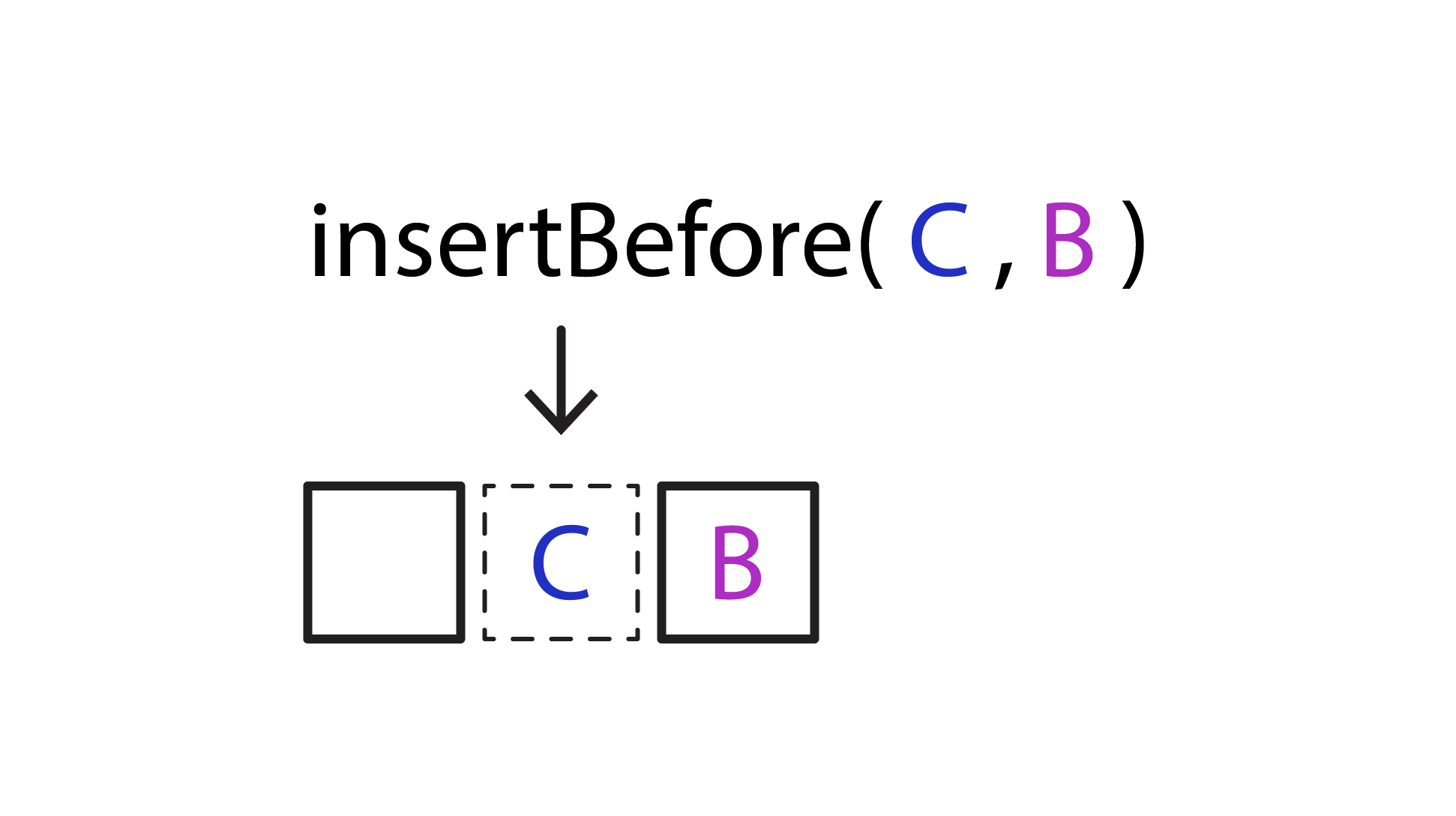
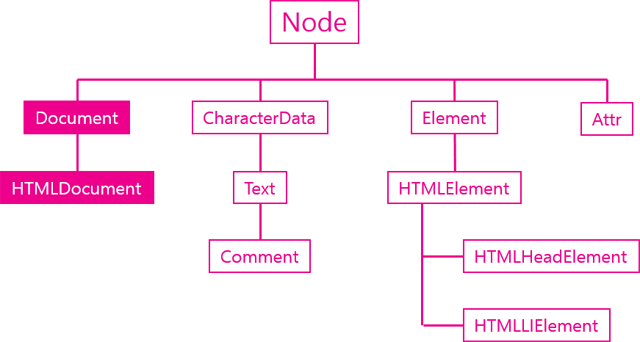
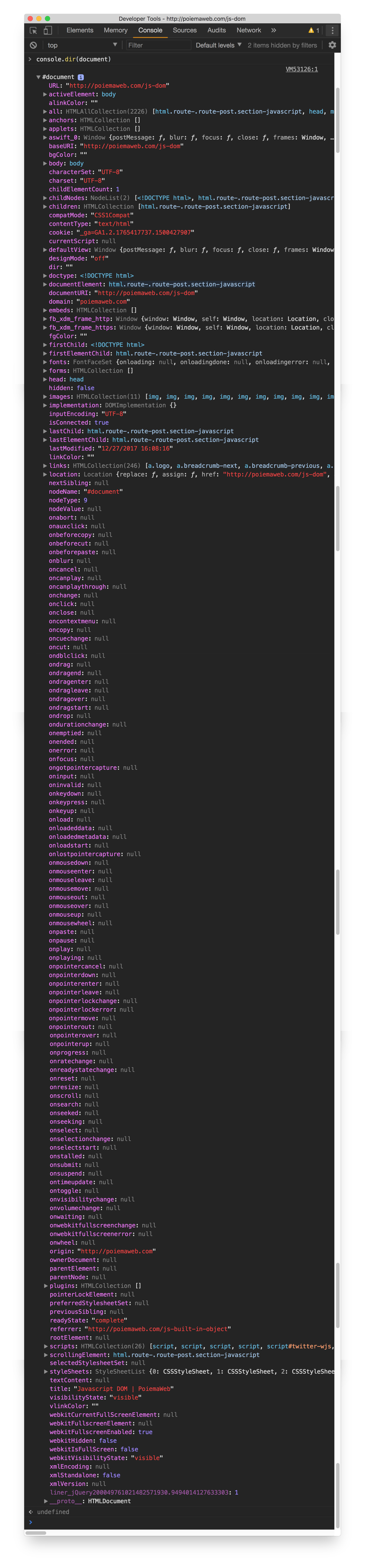
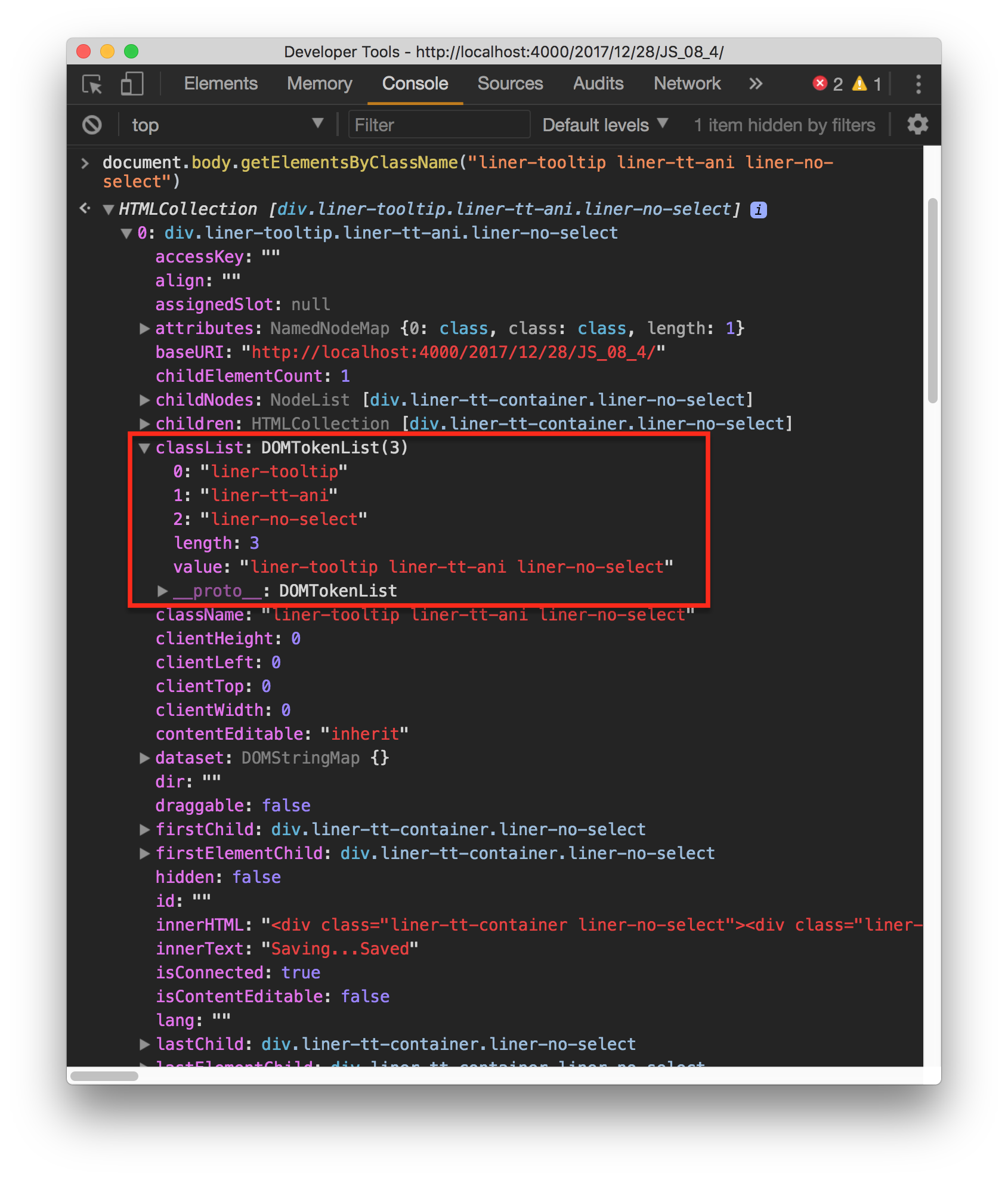
 - NodeList 객체와 마찬가지로 HTMLCollection 객체의 데이터 역시 대괄호기법과 item() 메서드로 접근 가능하다. - HTMLCollection의 `namedItem()` 메서드 - name 속성을 통해 컬렉션 데이터에 대한 참조를 얻는다.
- NodeList 객체와 마찬가지로 HTMLCollection 객체의 데이터 역시 대괄호기법과 item() 메서드로 접근 가능하다. - HTMLCollection의 `namedItem()` 메서드 - name 속성을 통해 컬렉션 데이터에 대한 참조를 얻는다. 
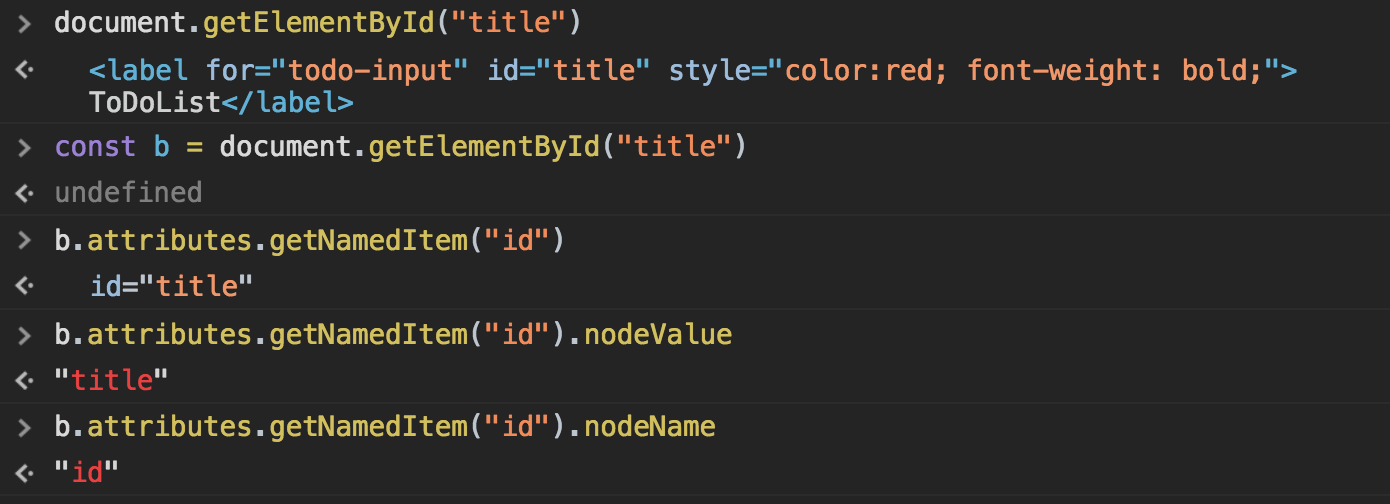
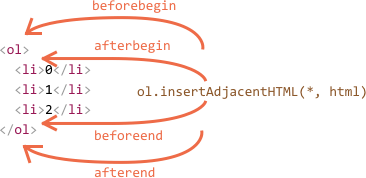
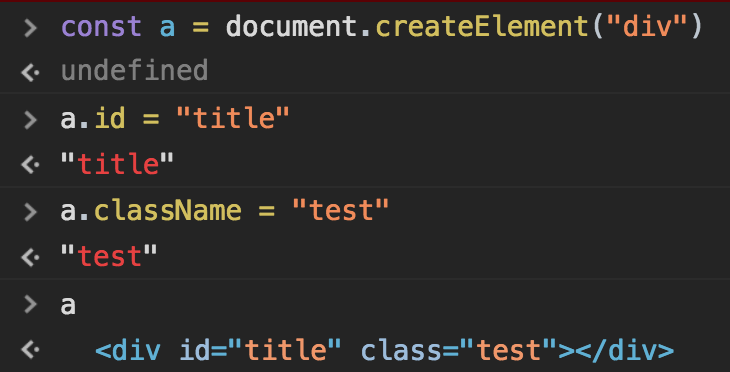 - createElement() 메서드는 새 요소를 생성하고 ownerDocument 프로퍼티를 설정한다.- 생성 이후에는 문서 트리의 일부가 아니므로 appendChild(), insertBefore(), replaceChild() 메서드를 통해 요소를 문서 트리에 추가해야한다.- IE7이전 버전에는 HTML을 통으로 인자로 넘길 수 있다.
- createElement() 메서드는 새 요소를 생성하고 ownerDocument 프로퍼티를 설정한다.- 생성 이후에는 문서 트리의 일부가 아니므로 appendChild(), insertBefore(), replaceChild() 메서드를 통해 요소를 문서 트리에 추가해야한다.- IE7이전 버전에는 HTML을 통으로 인자로 넘길 수 있다. > 알 수 없는 url
> 알 수 없는 url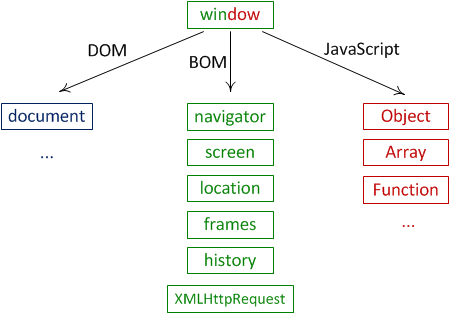
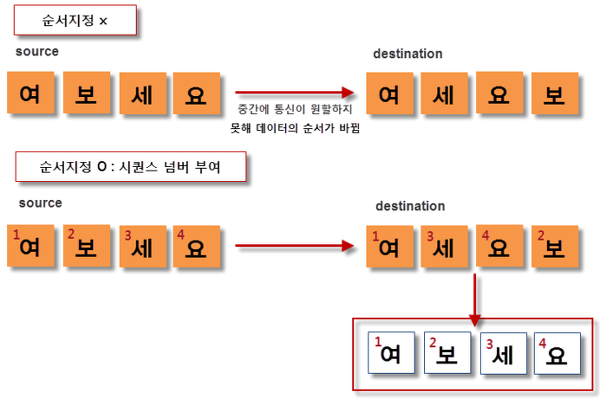
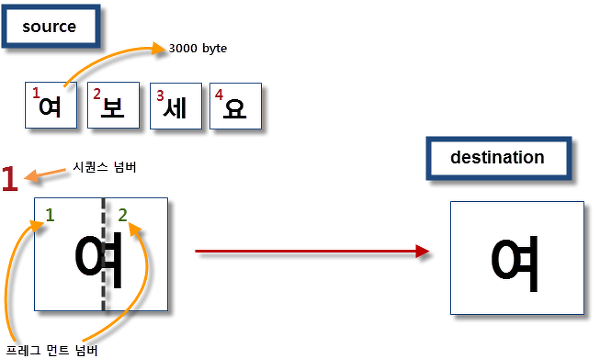

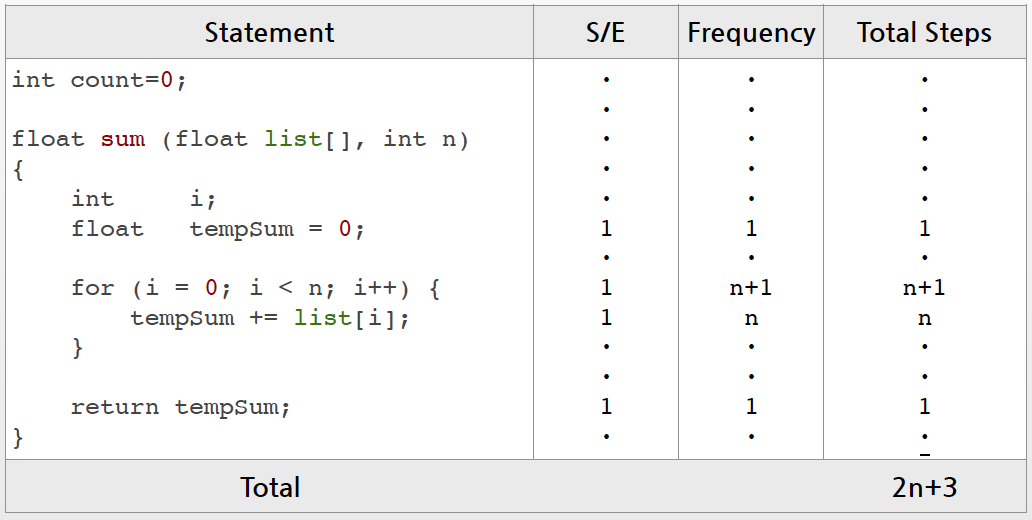
 MERGE-SORT는 combine하는 함수이다.
MERGE-SORT는 combine하는 함수이다.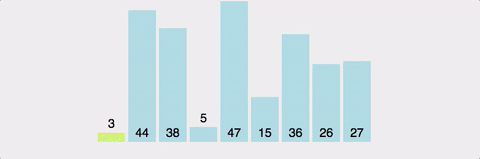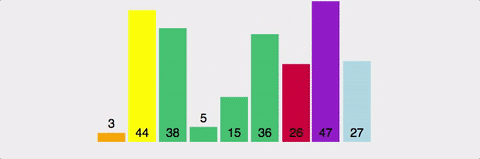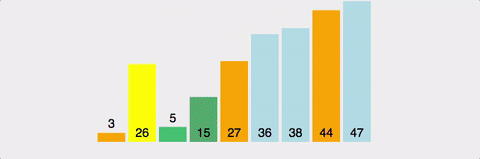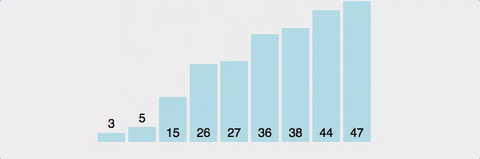

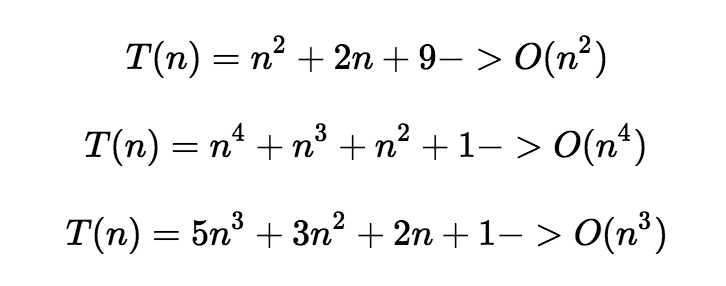
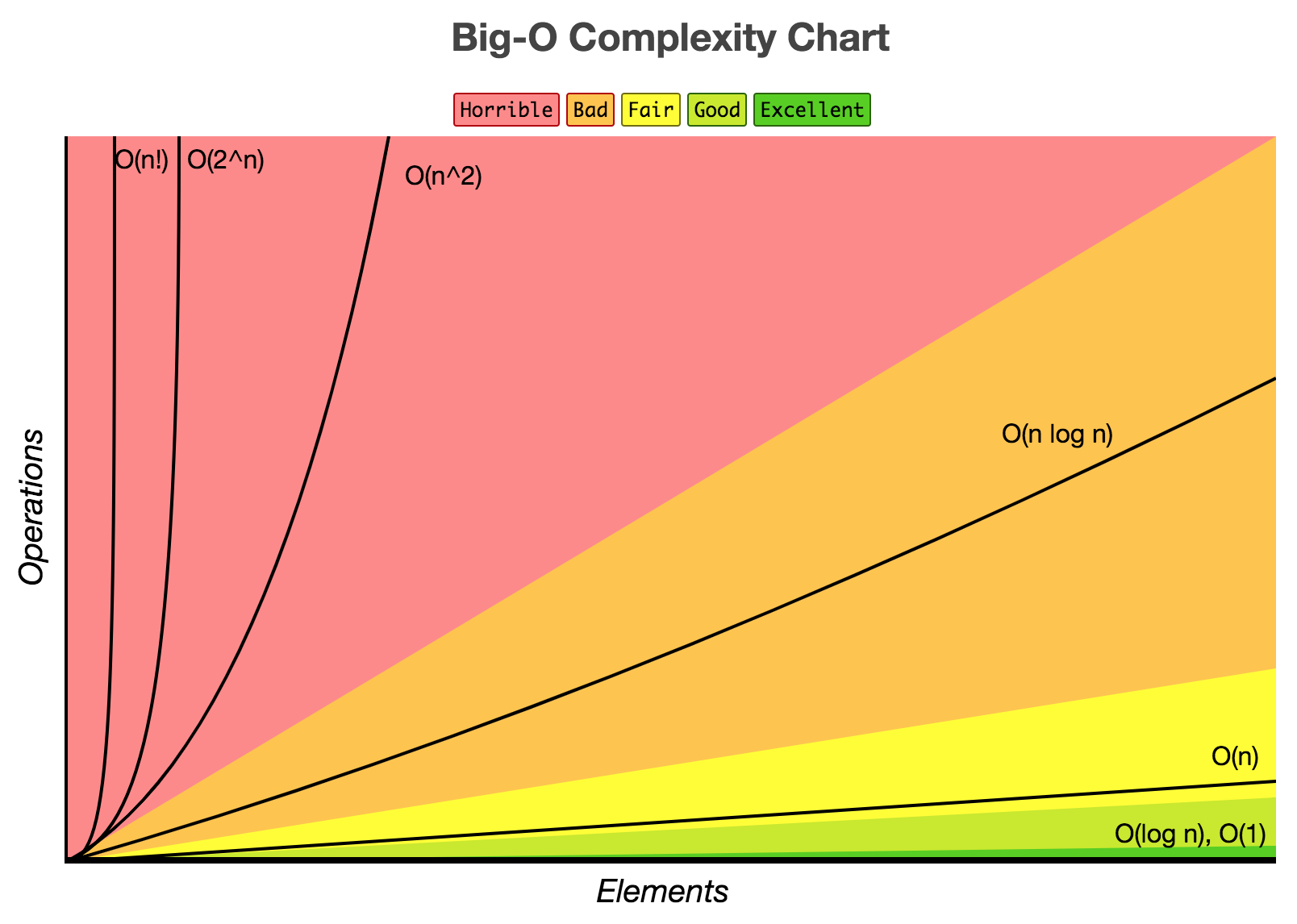
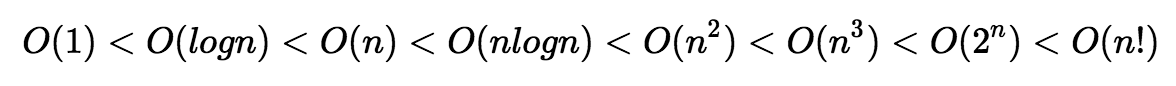
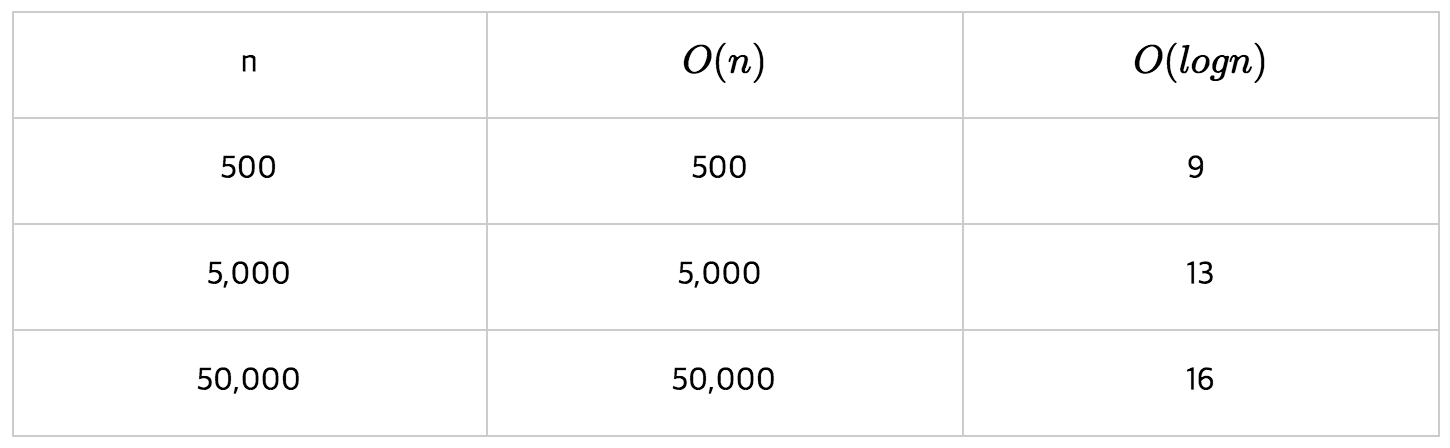
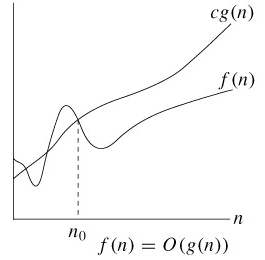 n0를 기준으로 n0보다 오른쪽에 있는 모든 n 값에 대해 함수 f(n)은 함수 cg(n)보다 작거나 같다는 의미이다. 그래프가 아래에 있을 수록 수행시간이 짧은 것이므로 성능이 좋은 것이다.
n0를 기준으로 n0보다 오른쪽에 있는 모든 n 값에 대해 함수 f(n)은 함수 cg(n)보다 작거나 같다는 의미이다. 그래프가 아래에 있을 수록 수행시간이 짧은 것이므로 성능이 좋은 것이다.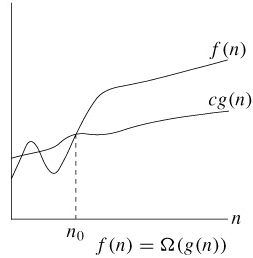 n0를 기준으로 n0보다 오른쪽에 있는 모든 n 값에 대해 함수 f(n)은 함수 cg(n)보다 크거나 같다는 의미이다.
n0를 기준으로 n0보다 오른쪽에 있는 모든 n 값에 대해 함수 f(n)은 함수 cg(n)보다 크거나 같다는 의미이다.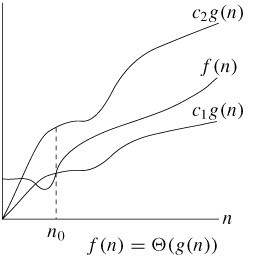 n0를 기준으로 n0보다 오른쪽에 있는 모든 n 값에 대해 함수 f(n)은 함수 c1g(n)보다 크거나 같거나 c2g(n)보다 작거나 같다는 의미이다
n0를 기준으로 n0보다 오른쪽에 있는 모든 n 값에 대해 함수 f(n)은 함수 c1g(n)보다 크거나 같거나 c2g(n)보다 작거나 같다는 의미이다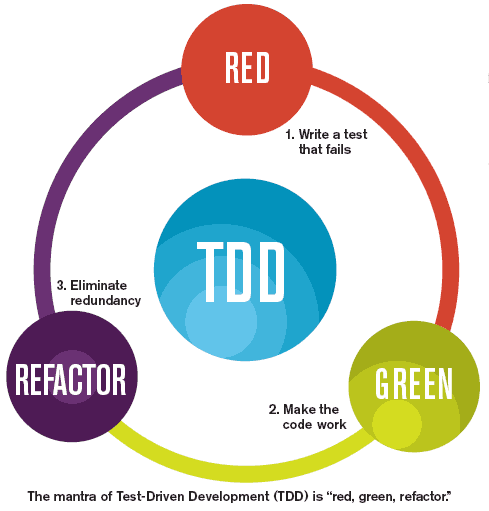 일반적으로 RED, GREEN, REFACTOR 세단계를 거쳐 이루어진다.
일반적으로 RED, GREEN, REFACTOR 세단계를 거쳐 이루어진다. Mocha is a feature-rich JavaScript test framework running on Node.js and in the browser, making asynchronous testing simple and fun. Mocha tests run serially, allowing for flexible and accurate reporting, while mapping uncaught exceptions to the correct test cases.
Mocha is a feature-rich JavaScript test framework running on Node.js and in the browser, making asynchronous testing simple and fun. Mocha tests run serially, allowing for flexible and accurate reporting, while mapping uncaught exceptions to the correct test cases.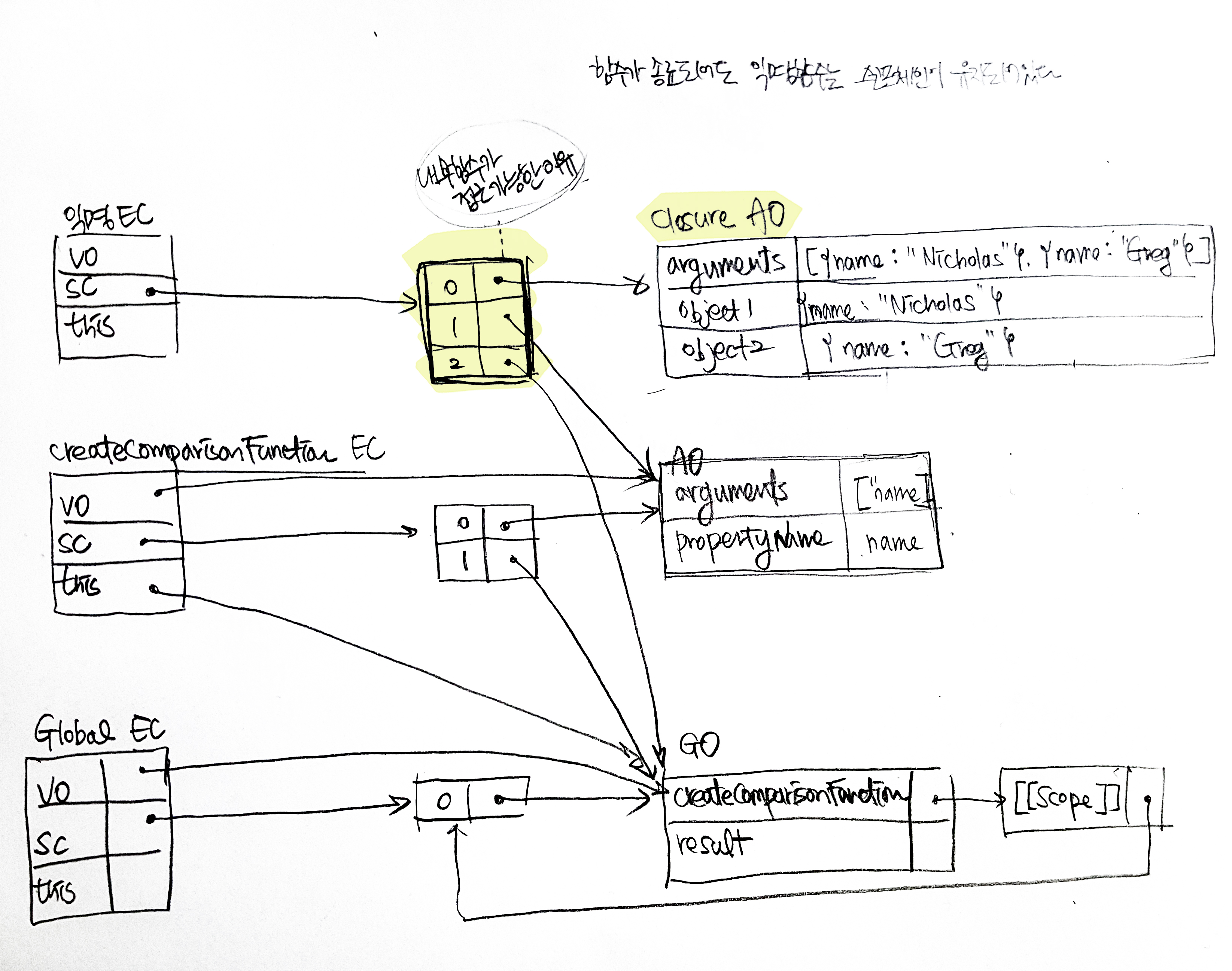 내부 함수가 반환되어 다른 컨텍스트에서 실행되는 동안에도 `propertyName`에 접근하 수 있다. 이런 일이 가능한 것은 내부 함수의 스코프 체인에 `createComparisonFunction()`의 스코프가 포함되기 때문이다.
내부 함수가 반환되어 다른 컨텍스트에서 실행되는 동안에도 `propertyName`에 접근하 수 있다. 이런 일이 가능한 것은 내부 함수의 스코프 체인에 `createComparisonFunction()`의 스코프가 포함되기 때문이다.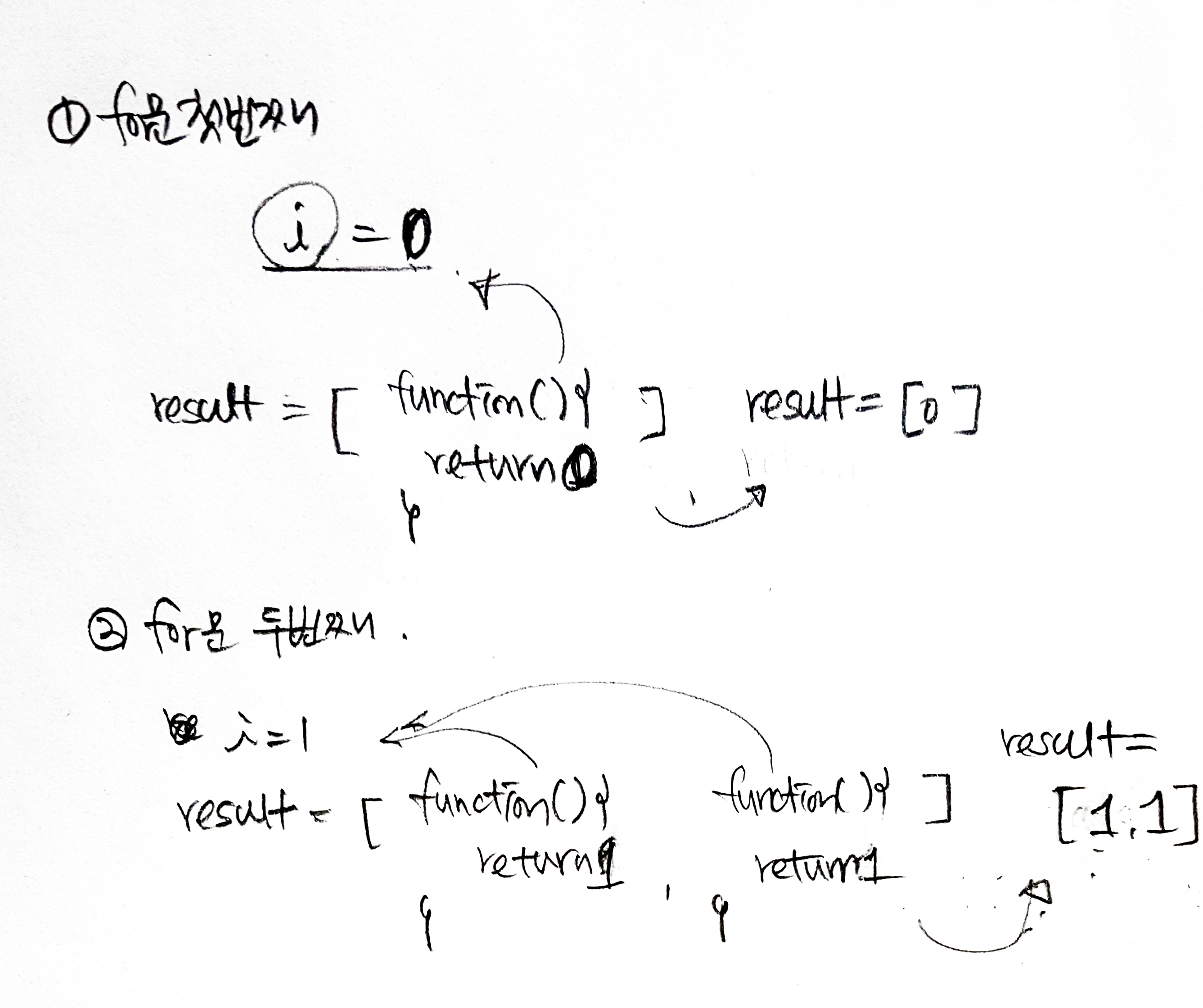
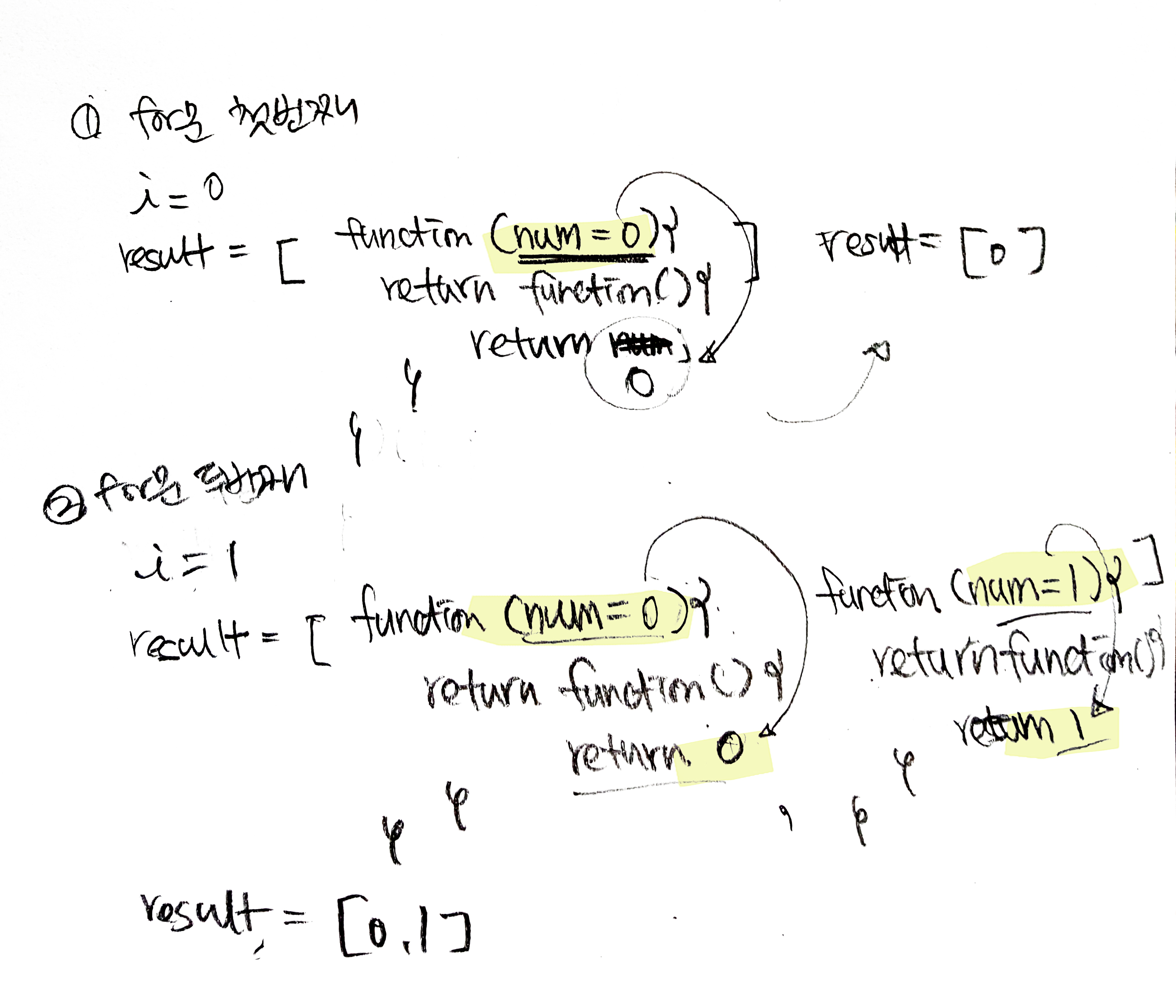 1. 즉시실행함수이기 때문에 함수가 실행되면서 내부함수가 반환된다. - 즉시실행함수는 한번만 호출시 처음 한번만 실행된다. 2. num에 i를 매개변수로 넘기기 때문에(복사) result에 들어가는 익명함수에는 자유변수 num이 생겼다고 보면되다.3. 배열에 들어가는 함수는 즉시실행함수 매개변수로 i를 받는다. i는 num에 매개변수로 **복사**가되고, num은 해당 함수의 자유변수가 된다. 반환된 내부함수는 자유변수 num에 엮여있는 함수 클로저가 된다. 때문에 외부함수에서 매개변수로 받는 i값에 따라 고유한 num과 클로저를 갖게 된다.
1. 즉시실행함수이기 때문에 함수가 실행되면서 내부함수가 반환된다. - 즉시실행함수는 한번만 호출시 처음 한번만 실행된다. 2. num에 i를 매개변수로 넘기기 때문에(복사) result에 들어가는 익명함수에는 자유변수 num이 생겼다고 보면되다.3. 배열에 들어가는 함수는 즉시실행함수 매개변수로 i를 받는다. i는 num에 매개변수로 **복사**가되고, num은 해당 함수의 자유변수가 된다. 반환된 내부함수는 자유변수 num에 엮여있는 함수 클로저가 된다. 때문에 외부함수에서 매개변수로 받는 i값에 따라 고유한 num과 클로저를 갖게 된다.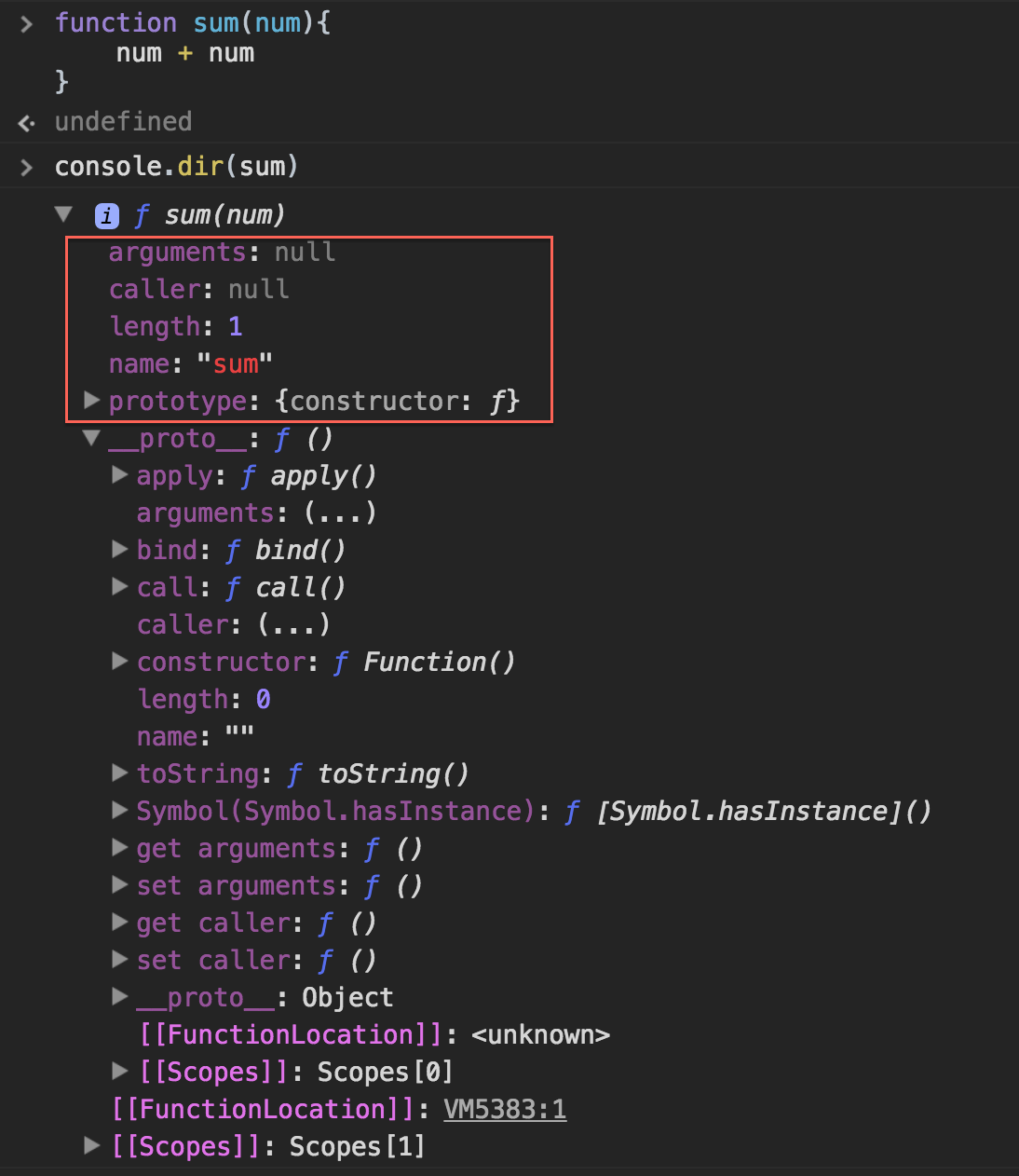
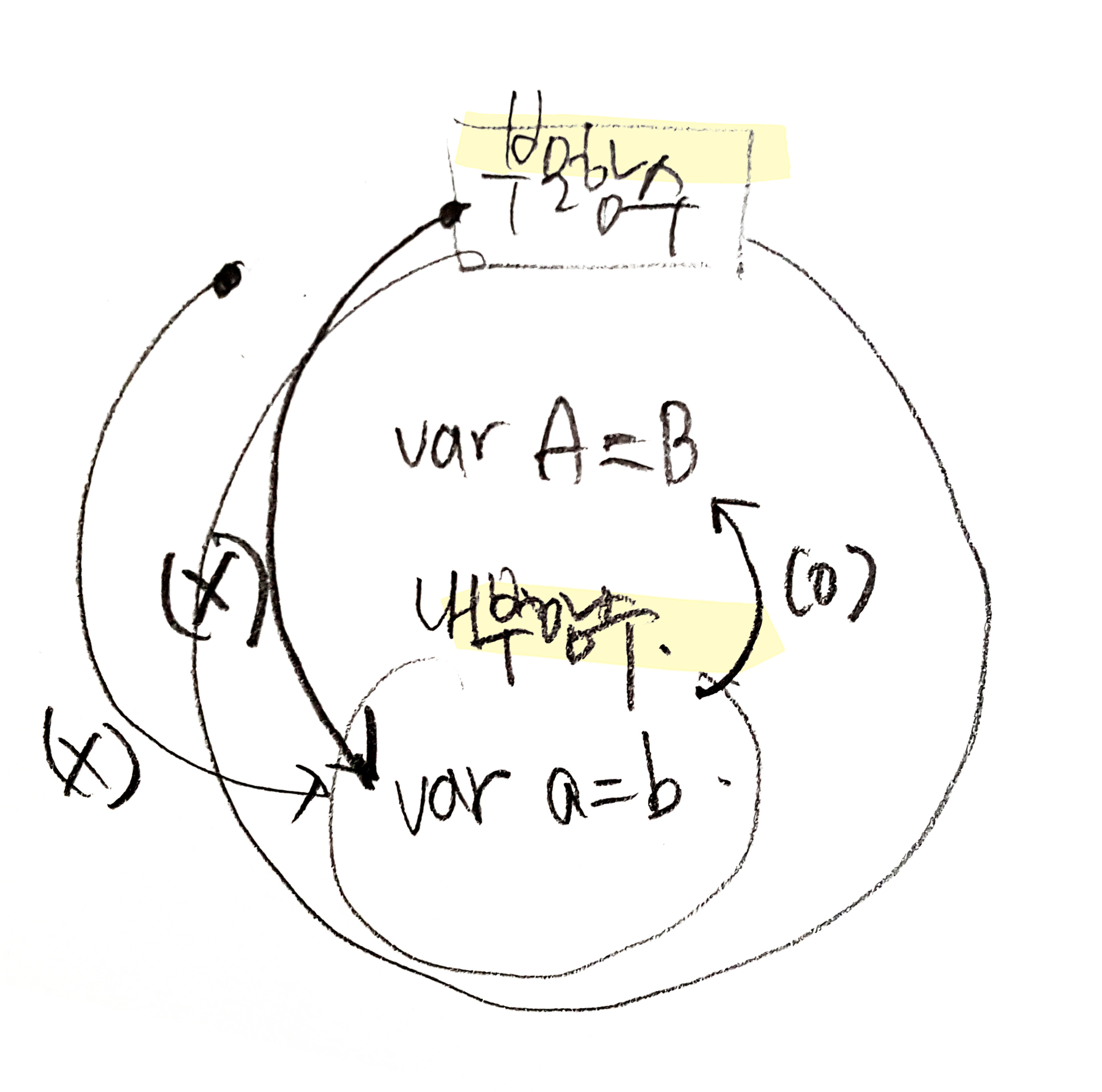
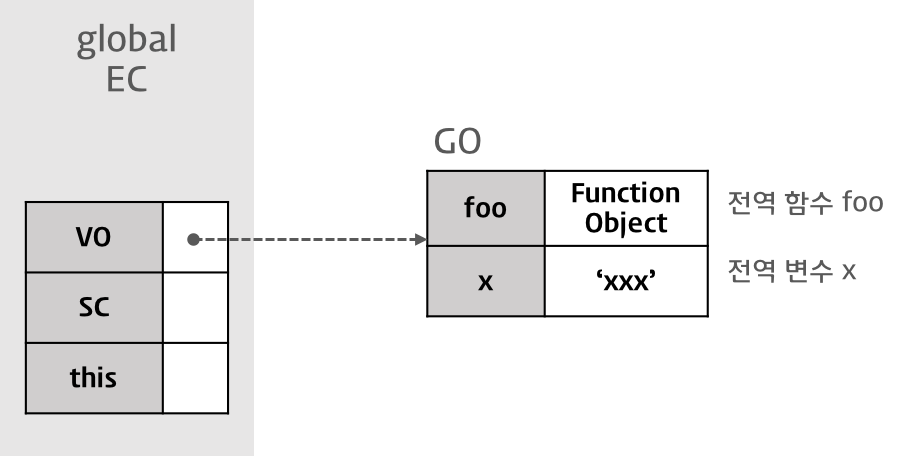
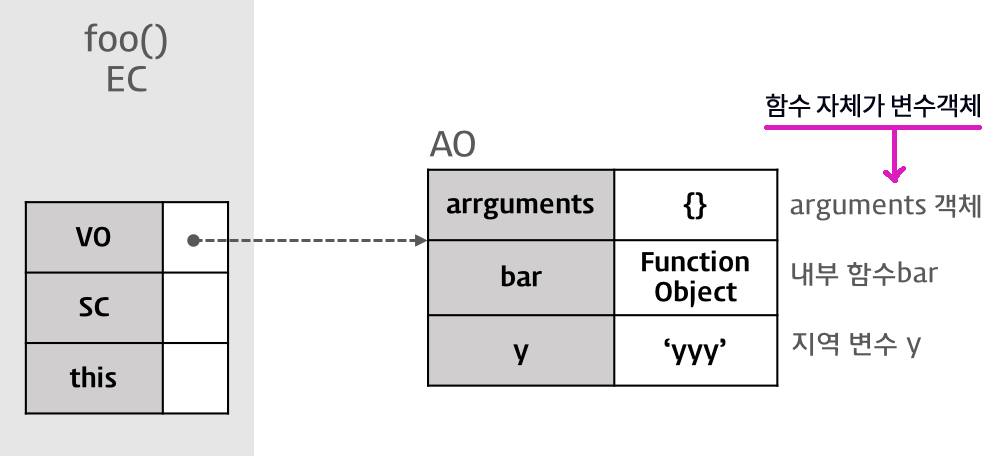
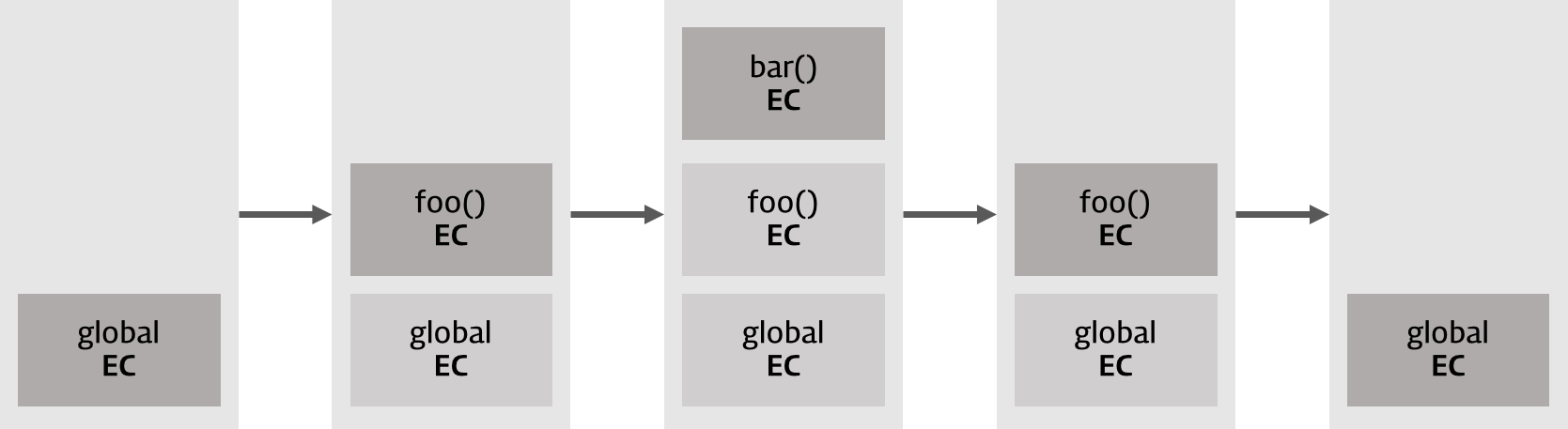 1. 컨트롤이 실행 가능한 코드로 이동하면 논리적 스택 구조를 가지는 새로운 실행 컨텍스트 스택이 생성된다. 스택은 LIFO(Last In First Out, 후입 선출)의 구조를 가지는 나열 구조이다.2. 전역 코드(Global code)로 컨트롤이 진입하면 전역 실행 컨텍스트가 생성되고 실행 컨텍스트 스택에 쌓인다. 전역 실행 컨텍스트는 애플리케이션이 종료될 때(웹 페이지에서 나가거나 브라우저를 닫을 때)까지 유지된다.3. 함수를 호출하면 해당 함수의 실행 컨택스트가 생성되며 직전에 실행된 코드블럭의 실행 컨텍스트 위에 쌓인다.4. 함수 실행이 끝나면 해당 함수의 실행 컨텍스트를 파기하고 직전의 실행 컨텍스트에 컨트롤을 반환한다.ECMAScript 프로그램은 모두 이런 식으로 실행된다.
1. 컨트롤이 실행 가능한 코드로 이동하면 논리적 스택 구조를 가지는 새로운 실행 컨텍스트 스택이 생성된다. 스택은 LIFO(Last In First Out, 후입 선출)의 구조를 가지는 나열 구조이다.2. 전역 코드(Global code)로 컨트롤이 진입하면 전역 실행 컨텍스트가 생성되고 실행 컨텍스트 스택에 쌓인다. 전역 실행 컨텍스트는 애플리케이션이 종료될 때(웹 페이지에서 나가거나 브라우저를 닫을 때)까지 유지된다.3. 함수를 호출하면 해당 함수의 실행 컨택스트가 생성되며 직전에 실행된 코드블럭의 실행 컨텍스트 위에 쌓인다.4. 함수 실행이 끝나면 해당 함수의 실행 컨텍스트를 파기하고 직전의 실행 컨텍스트에 컨트롤을 반환한다.ECMAScript 프로그램은 모두 이런 식으로 실행된다.
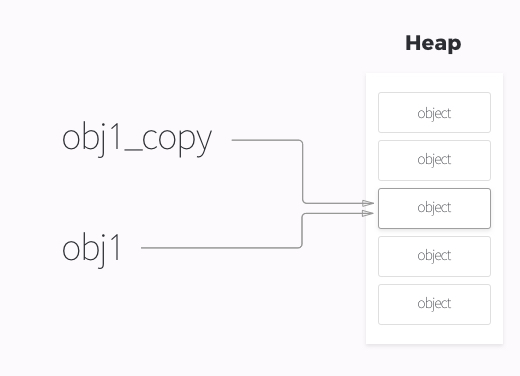

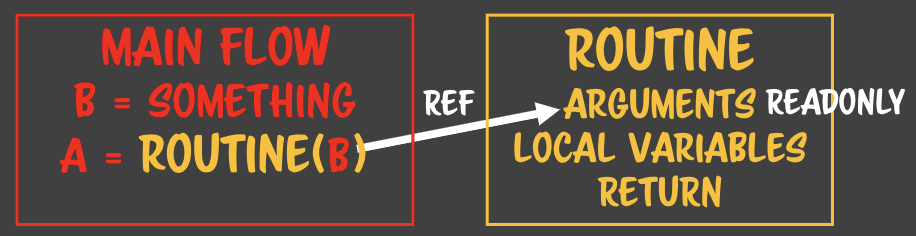
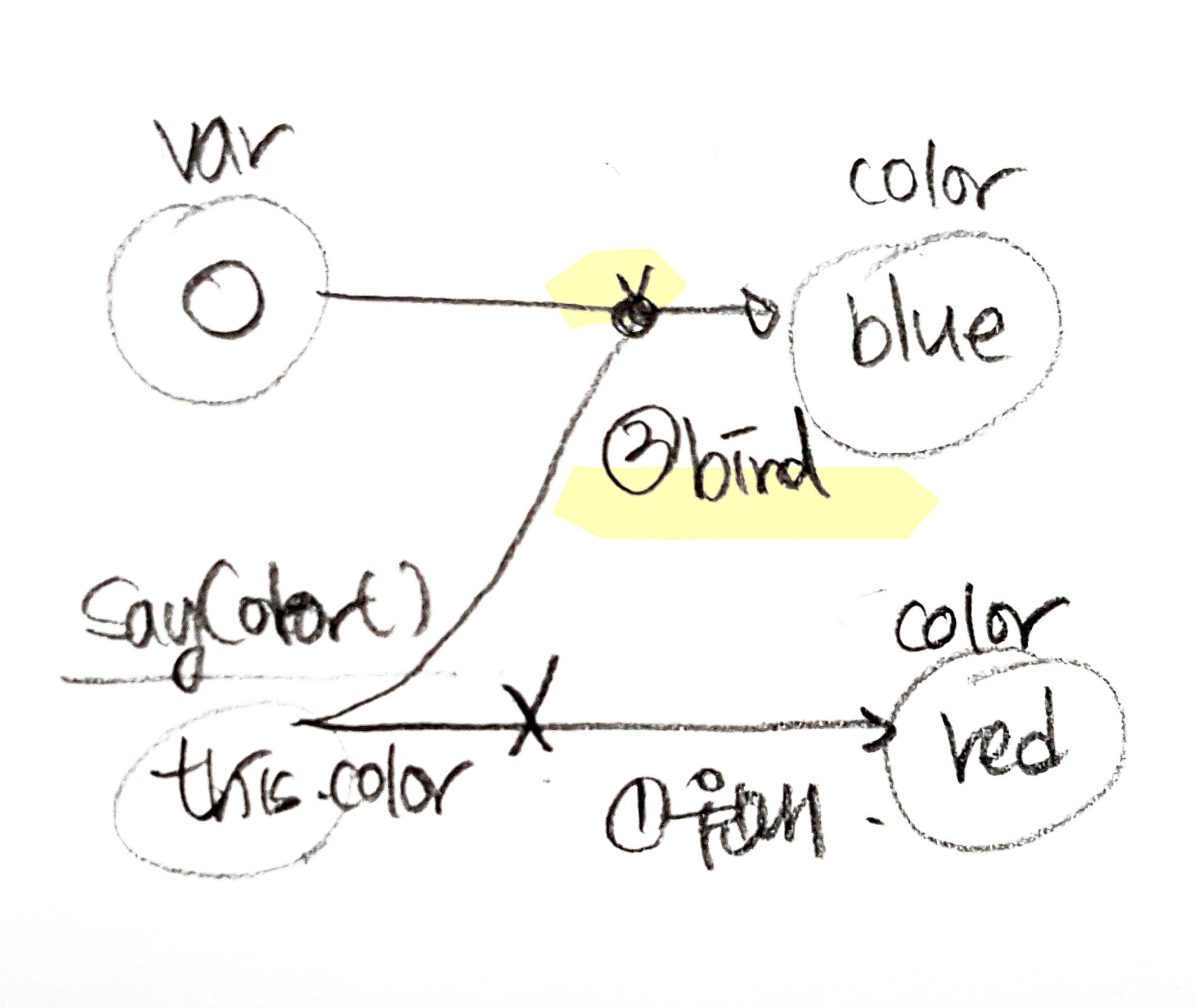
 함수에 `값`을 전달했기 때문에 함수 내부에서 매개변수의 값이 바뀌었음에도 불구하고 원래 객체에 대한 참조를 그대로 유지한 것이다. = 즉 객체가 넘어갈때는 참조 형태로 전달되는 것이 아니라 **값으로 넘어간다.** (== 포인터가 넘어간다)
함수에 `값`을 전달했기 때문에 함수 내부에서 매개변수의 값이 바뀌었음에도 불구하고 원래 객체에 대한 참조를 그대로 유지한 것이다. = 즉 객체가 넘어갈때는 참조 형태로 전달되는 것이 아니라 **값으로 넘어간다.** (== 포인터가 넘어간다) 함수 내부에서 obj를 덮어쓰면 obj는 지역객체를 가리키는 포인터가 되고, 이 지역 객체(obj.name)는 함수 실행이 끝나면 파괴된다.
함수 내부에서 obj를 덮어쓰면 obj는 지역객체를 가리키는 포인터가 되고, 이 지역 객체(obj.name)는 함수 실행이 끝나면 파괴된다.
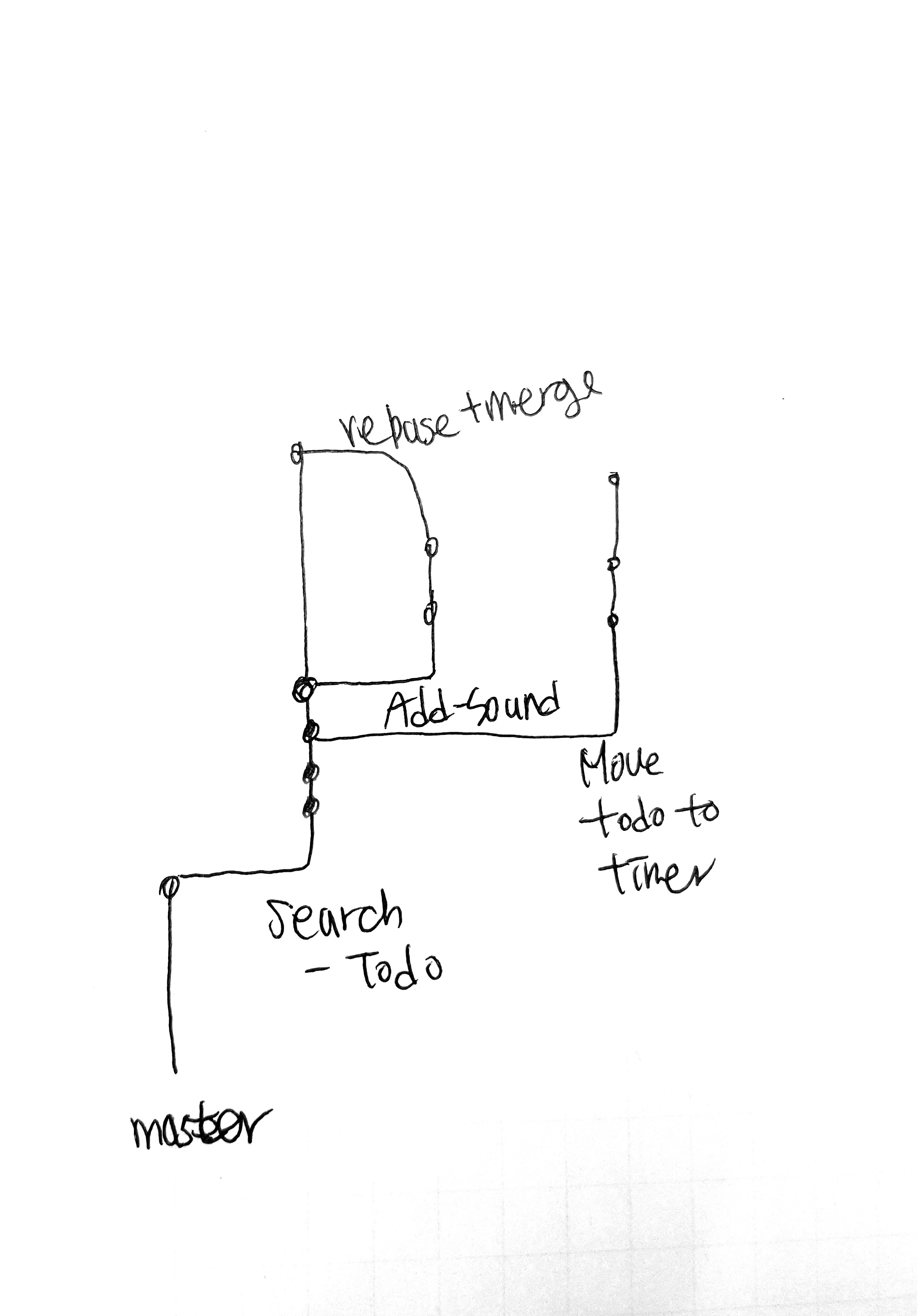
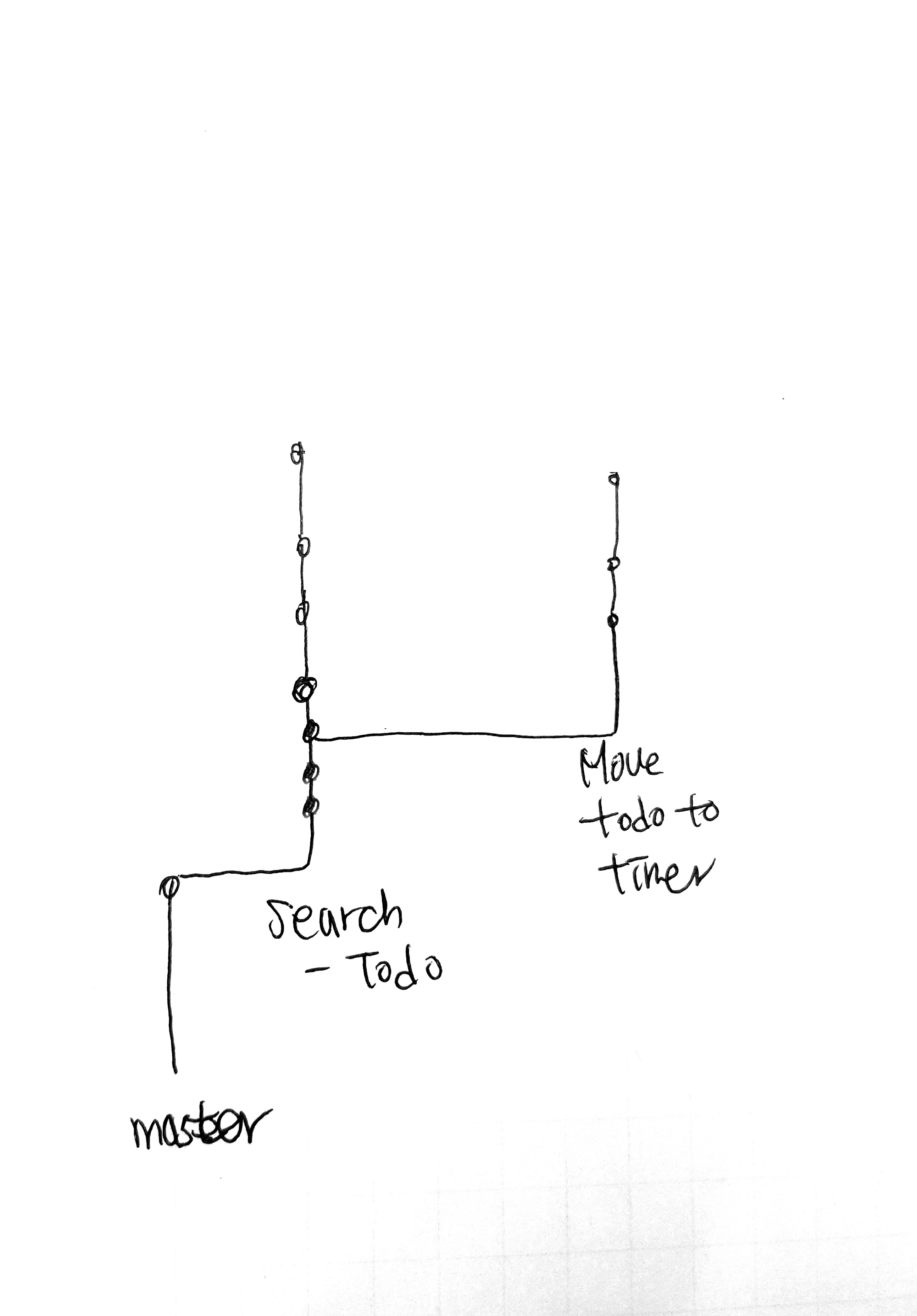
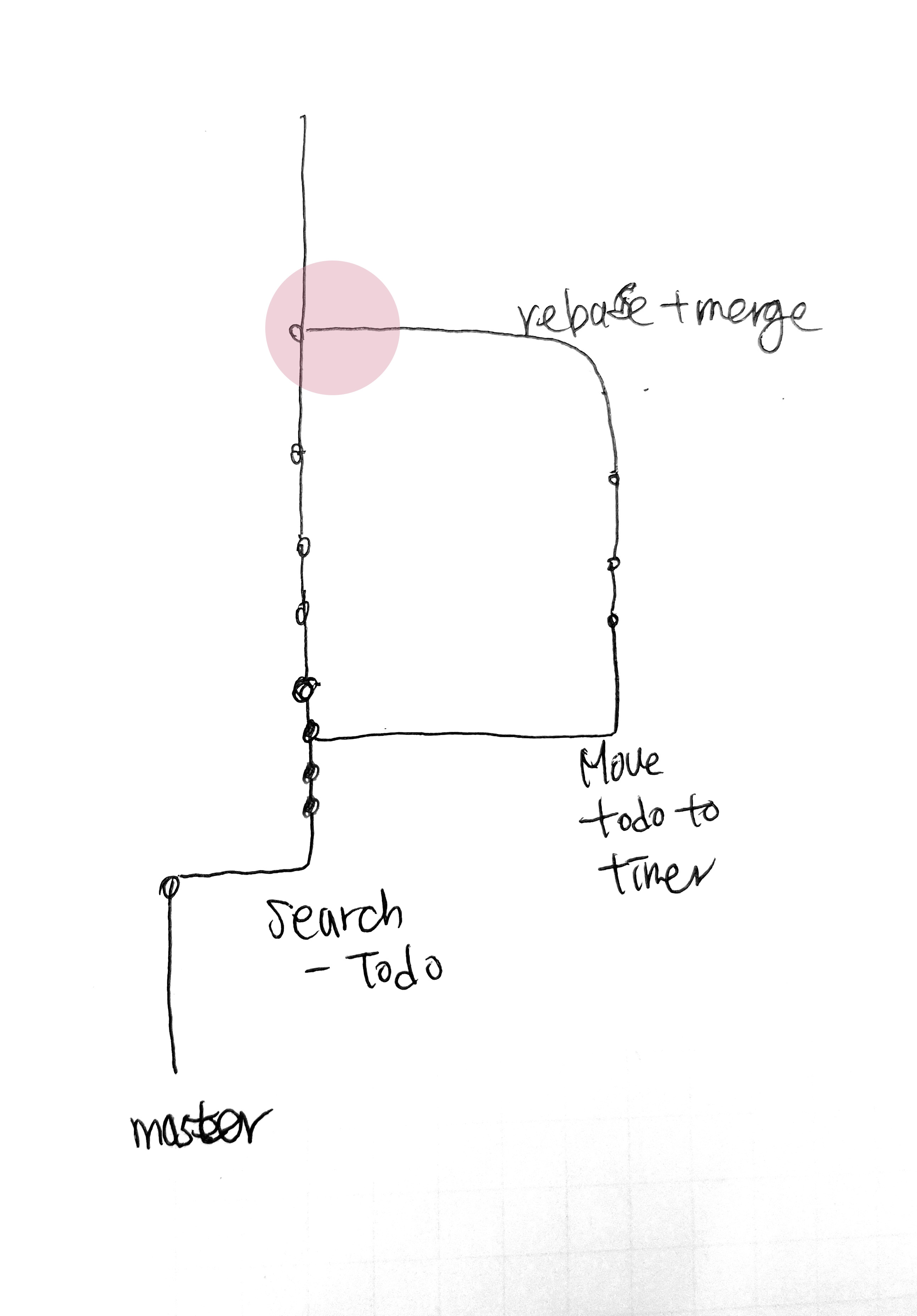
 > 퍼블리싱 끝나고 merge 후
> 퍼블리싱 끝나고 merge 후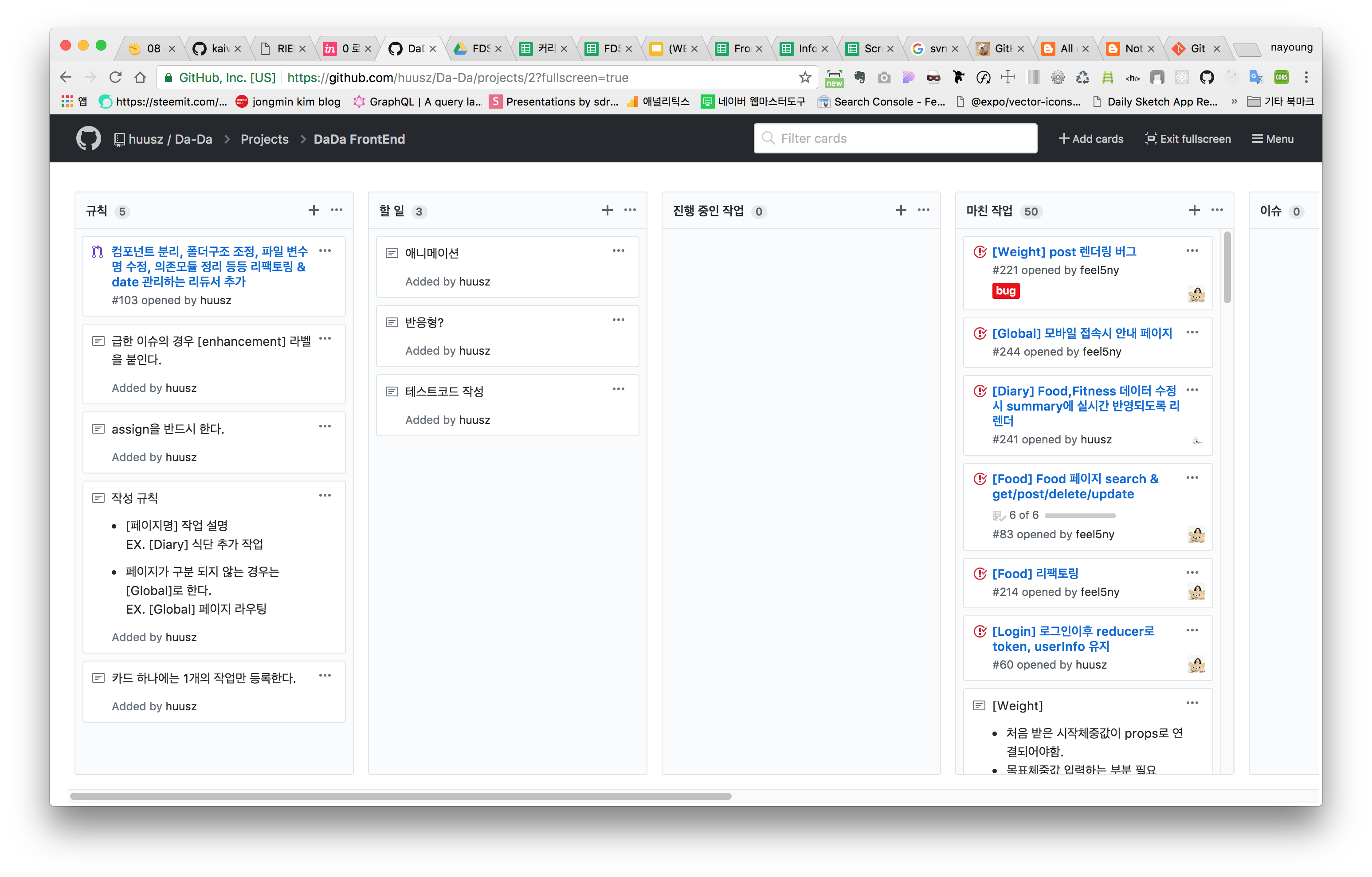 프로젝트 탭은 총 5가지로 구성하였다.1. 규칙2. 할 일3. 진행 중인 작업4. 마친 작업
프로젝트 탭은 총 5가지로 구성하였다.1. 규칙2. 할 일3. 진행 중인 작업4. 마친 작업


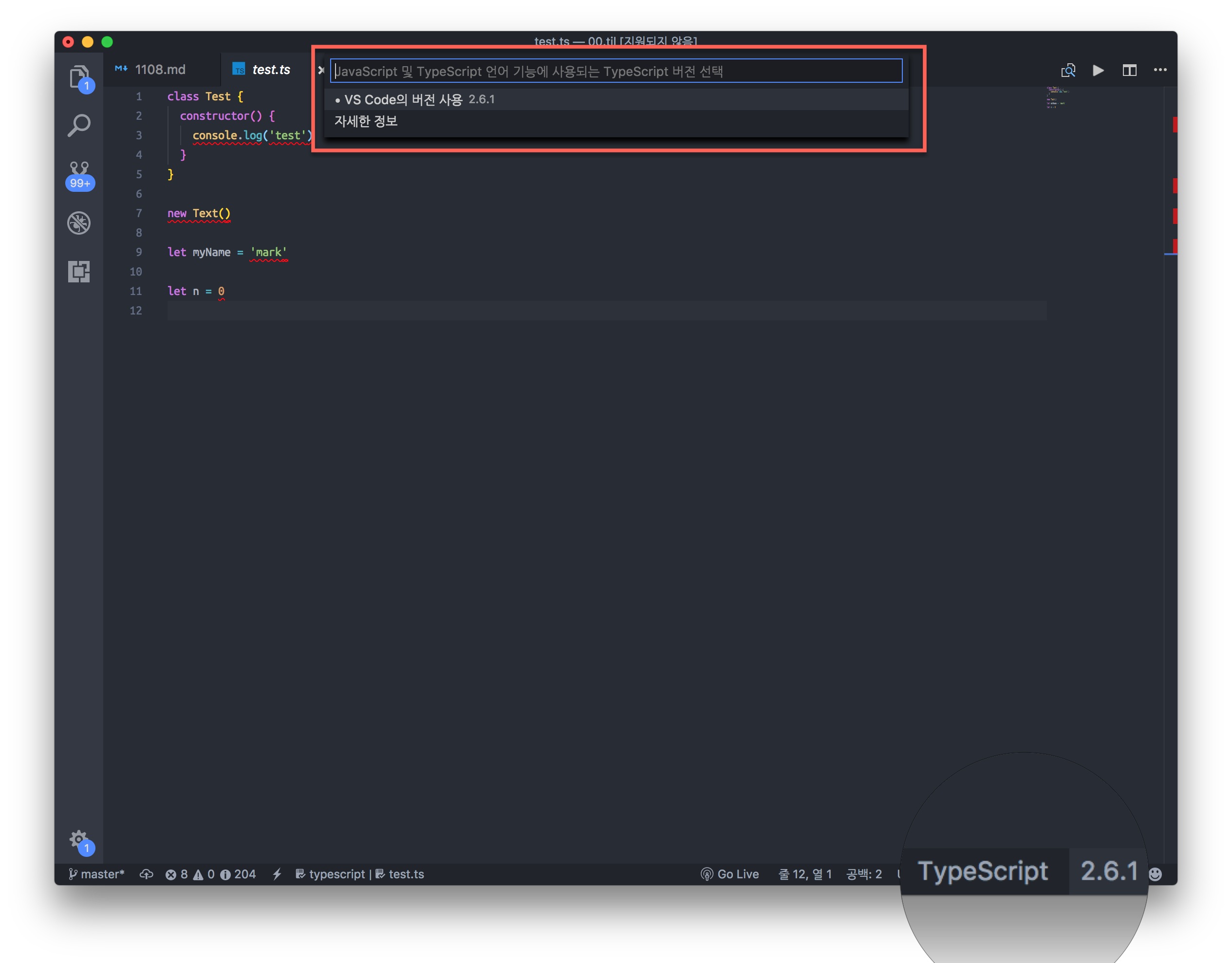 ts파일을 선택 후 하단 bar를 보면 Typescript라는 단어와 버전이 보인다. 버전을 누르면 옵션창이 보이게 되는데, 이는 VS Code에 내장되어있는 컴파일러 리스트 중 선택하라는 옵션창이다. 내장된 컴파일러 버전은 VS Code 가 업데이트 되면서 자동으로 올라가며, 컴파일러 버전과 VS Code 의 버전은 상관 관계가 있다. 내장된 컴파일러를 선택할수 있고, 직접 설치한 컴파일러를 선택할 수도 있다.
ts파일을 선택 후 하단 bar를 보면 Typescript라는 단어와 버전이 보인다. 버전을 누르면 옵션창이 보이게 되는데, 이는 VS Code에 내장되어있는 컴파일러 리스트 중 선택하라는 옵션창이다. 내장된 컴파일러 버전은 VS Code 가 업데이트 되면서 자동으로 올라가며, 컴파일러 버전과 VS Code 의 버전은 상관 관계가 있다. 내장된 컴파일러를 선택할수 있고, 직접 설치한 컴파일러를 선택할 수도 있다. [Git](https://backlogtool.com/git-tutorial/kr/intro/intro1_1.html)이란 소스코드를 효과적으로 관리하기 위해 개발된 '분산형 버전 관리 시스템'입니다.git은 저장소에서 관리를 하는데, 내 컴퓨터에 있는 저장소를 `로컬저장소`라고 하고, 웹 상에 있는 저장소를 `원격저장소`라고 합니다. 우리가 흔히 알고 있는 원격저장소를 제공하는 서비스에는 **깃헙, 비트버킷, 깃랩**등이 있습니다다. 헥소를 이용한 블로그 개설을 위해서는 **깃헙**을 사용해야합니다.### 0-2. 원격저장소 Github이 제공하는 정적웹사이트, Github Pages
[Git](https://backlogtool.com/git-tutorial/kr/intro/intro1_1.html)이란 소스코드를 효과적으로 관리하기 위해 개발된 '분산형 버전 관리 시스템'입니다.git은 저장소에서 관리를 하는데, 내 컴퓨터에 있는 저장소를 `로컬저장소`라고 하고, 웹 상에 있는 저장소를 `원격저장소`라고 합니다. 우리가 흔히 알고 있는 원격저장소를 제공하는 서비스에는 **깃헙, 비트버킷, 깃랩**등이 있습니다다. 헥소를 이용한 블로그 개설을 위해서는 **깃헙**을 사용해야합니다.### 0-2. 원격저장소 Github이 제공하는 정적웹사이트, Github Pages Github에서 제공하는 Static Website, Github Pages가 있다. 깃헙 저장소에 리소스를 `push`만 해도(push란 저장소에 리소스를 넣을때 사용하는 명령어) 간단하게 웹사이트를 만들 수 있다. 즉, 다른 호스팅 서비스의 도움없이, 원격저장소에 올리기만해도 호스팅이 가능하다.### 0-3. 호스팅을 편리하게 만들어주는 generator, Jekyll & HEXO
Github에서 제공하는 Static Website, Github Pages가 있다. 깃헙 저장소에 리소스를 `push`만 해도(push란 저장소에 리소스를 넣을때 사용하는 명령어) 간단하게 웹사이트를 만들 수 있다. 즉, 다른 호스팅 서비스의 도움없이, 원격저장소에 올리기만해도 호스팅이 가능하다.### 0-3. 호스팅을 편리하게 만들어주는 generator, Jekyll & HEXO
 ### 1-1. 로컬에 저장소 생성하기내 컴퓨터 원하는 장소에 폴더를 생성한다.terminal없이도 생성해도 된다. 아래는 terminal을 이용한 생성방법
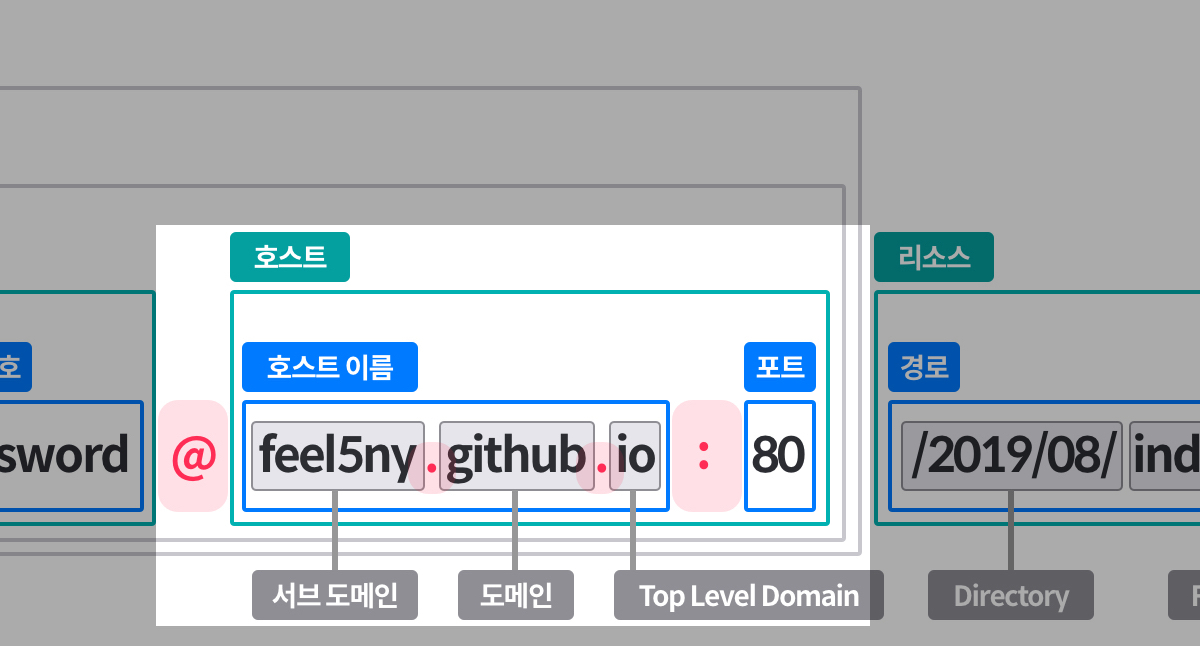
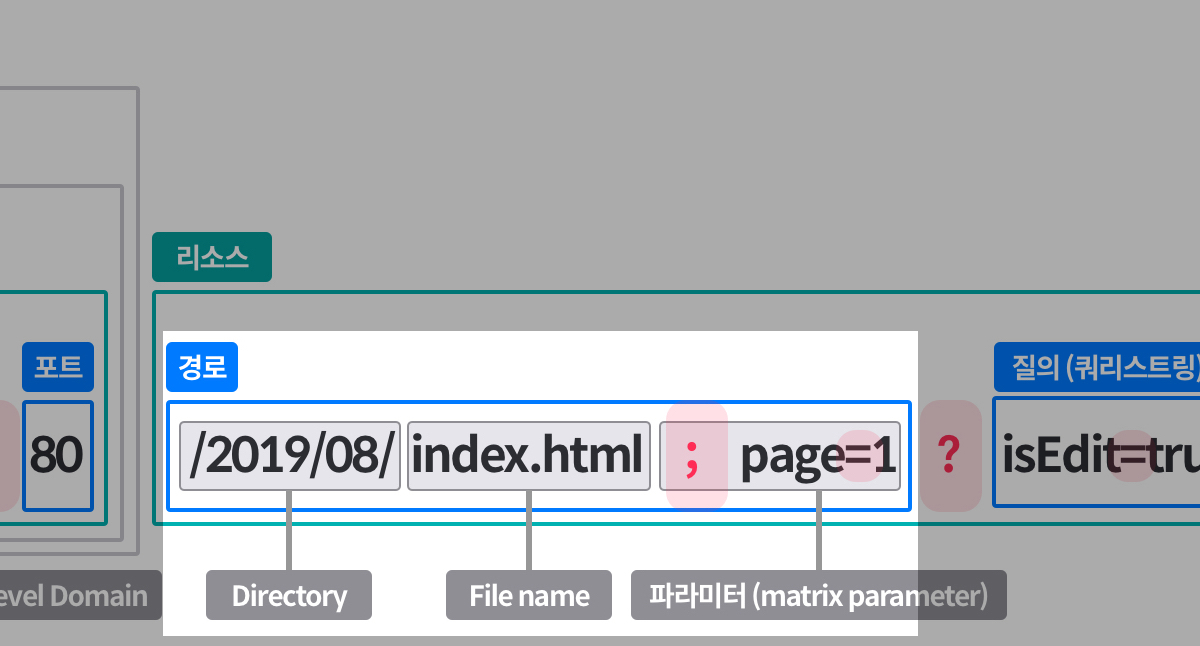
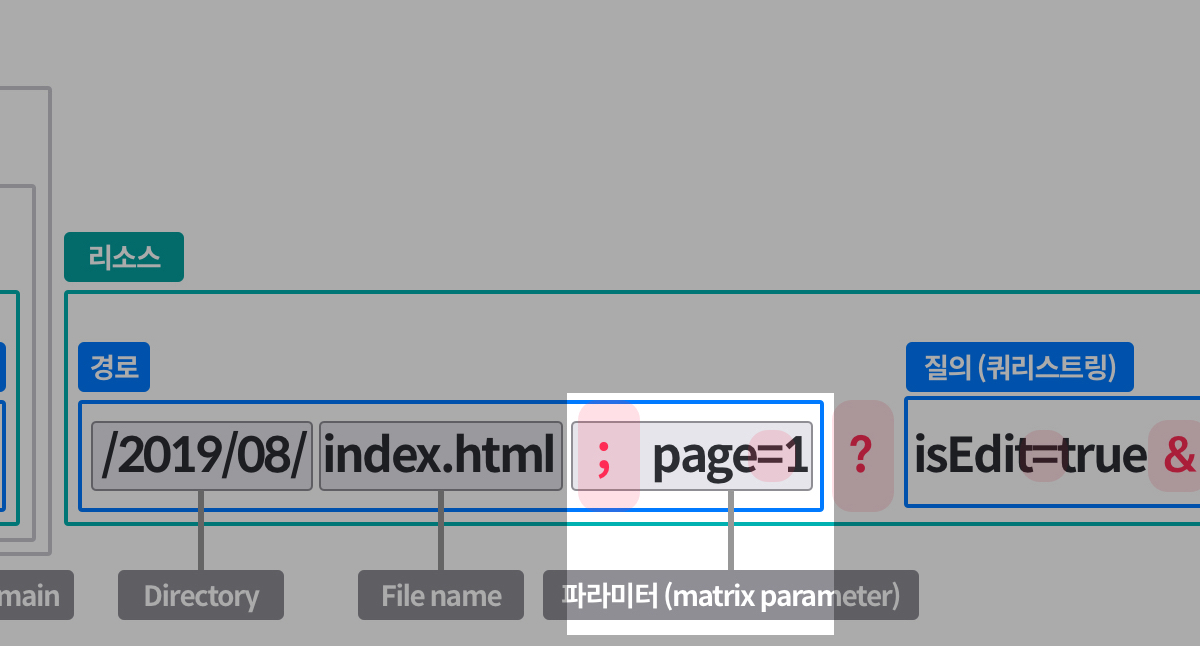
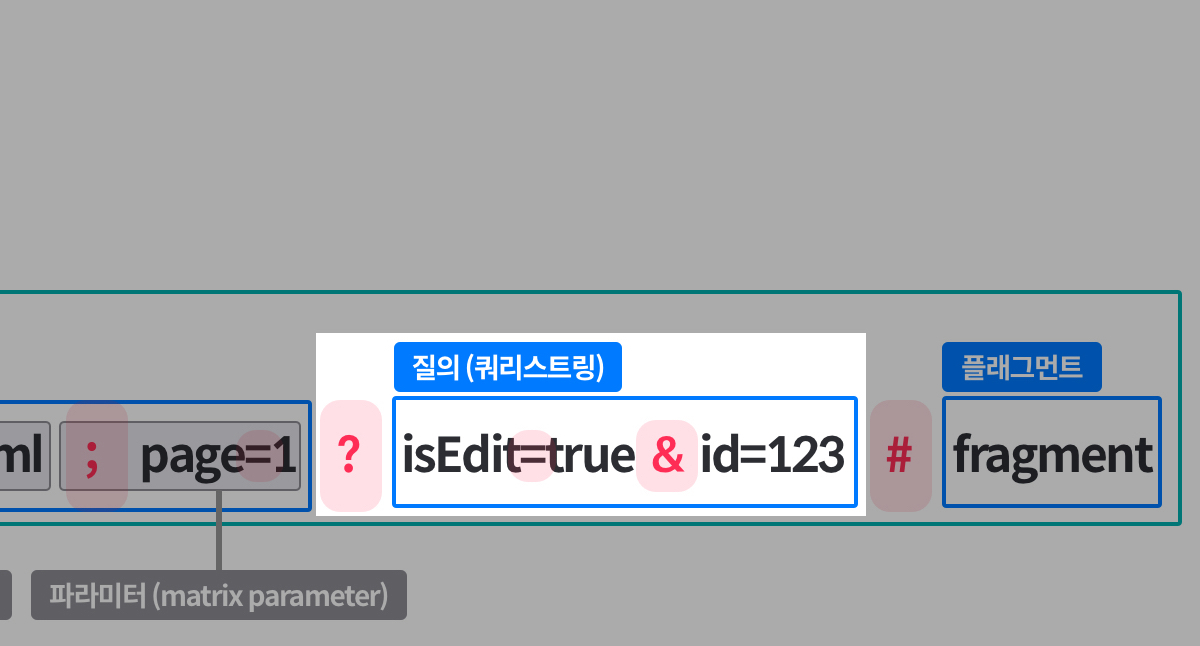
### 1-1. 로컬에 저장소 생성하기내 컴퓨터 원하는 장소에 폴더를 생성한다.terminal없이도 생성해도 된다. 아래는 terminal을 이용한 생성방법 github pages를 통해 손쉽게 `USERNAME.github.io`를 통해 정적 페이지를 호스팅 할 수 있다. > 번외 > gh-pages 브랜치를 생성하면, 각 repository마다 `USERNAME.github.io/레포이름`으로 호스팅이 가능하다.
github pages를 통해 손쉽게 `USERNAME.github.io`를 통해 정적 페이지를 호스팅 할 수 있다. > 번외 > gh-pages 브랜치를 생성하면, 각 repository마다 `USERNAME.github.io/레포이름`으로 호스팅이 가능하다. ### 1-3. 원격 저장소와 로컬 저장소 연결하기
### 1-3. 원격 저장소와 로컬 저장소 연결하기 내 컴퓨터에 저장소를 만들고, 원격에도 만들었으니, 연결을 해야한다. 연결하는 방법은 간단하다. 지금은 터미널을 열고 명령어를 입력해야하는 타이밍이다.
내 컴퓨터에 저장소를 만들고, 원격에도 만들었으니, 연결을 해야한다. 연결하는 방법은 간단하다. 지금은 터미널을 열고 명령어를 입력해야하는 타이밍이다.
