Back to Posts
2019년 10월 21일
WIP_웹 로봇

웹 로봇(스스로 움직이는 사용자 에이전트)에 대해서 알아본다. 웹 로봇은 사람과의 상호작용 없이 연속된 웹 트랜잭션들을 자동으로 수행하는 소프트웨어 프로그램이다.
- 방식에 따라 크롤러, 스파이더, 웜, 봇 등 각양각색의 이름으로 불린다.
주식 그래프 봇 (매분 HTTP GET 요청을 보내 얻은 데이터로 그래프 생성) 웹 통계조사 로봇 (통계 정보를 수집) 검색엔진 로봇 (모든 문서를 수집) 가격 비교 로봇 (상품 가격 DB를 만들기 위해 온라인 쇼핑몰 웹페이지 수집)
1. 크롤러와 크롤링
- 웹 크롤러는
- 먼저 웹페이지를 한 개 가져오고,
- 그 다음 그 페이지가 가리키는 모든 웹페이지를 가져오고,
- 다시 그 페이지를 가리키는 모든 웹페이지들을 가져온다.
- 이런 재귀적으로 반복하는 방식으로 웹을 순회하는 로봇이다.
- 크롤러 (스파이더): 웹 링크를 재귀적으로 따라가는 로봇
- HTML 하이퍼링크로 만들어진 웹을 따라 기어다니기(crawl) 때문이다.
- 인터넷 검색엔진은 웹을 돌아다니면서 만나는 모든 문서를 끌어오기 위해 크롤러를 사용한다.
그렇다면 크롤러들은 어떻게 동작할까?
1.1 시작은 ‘루트 집합’에서 🏃
- 출발지점을 주어야한다.
- 루트 집합 (root set): 크롤러가 방문을 시작하는 URL들의 초기 집합
- 루트 집합을 고를때, 모든 링크를 크롤링하면서 관심있는 웹페이지들을 많이 가져올 수 있도록, URL들을 선택해야한다
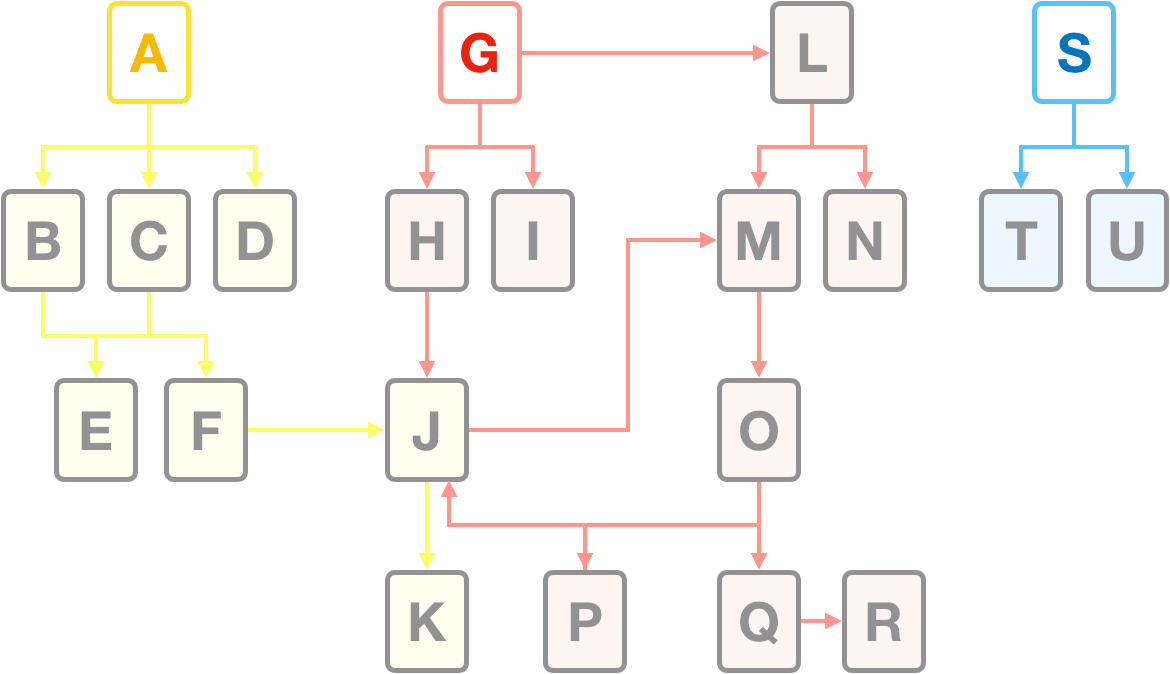
- S,T,U는 아직 누구도 찾아내지 못한 것들일 것이다. 혹은 정말 오래되었거나
- 오직 A,G,S가 루트집합에 있기만 하면 모든 페이지에 도달할 수 있다.
- 좋은 루트 집합
- 크고 인기 있는 웹사이트 (like 유투브)
- 새로 생성된 페이지들의 목록
- 자주 링크되지 않는 잘 알려져 있지 않은 페이지들의 목록
- 페이지들을 추가하는 기능을 제공
- 대규모 크롤러 제품들은 (인터넷 검색엔진에서 쓰이는 것과 같은) 루트 집합에 새 페이지나 사용자들에게 잘 알려져 있지 않은 페이지들을 추가하는 기능을 제공한다.
- 이 루트집합은 시간이 지남에 따라 성장하며
- 새로운 크롤링을 위한 seed 목록이 된다.
1.2 링크 추출과 상대 링크를 절대링크로
- 크롤러는
- 검색한 각 페이지 안에 들어있는 URL 링크들을 파싱해서
- 크롤링할 페이지들의 목록에 추가해야한다.
- 크롤러가 크롤링을 진행하면서 탐색해야 할 새 링크를 발견함에 따라 => 이 목록은 보통 급속히 확장된다.
- 상대 링크를 발견할 경우 절대 링크로 변활할 필요가 있다.
1.3 순환 피하기
- 로봇이 웹을 크롤링할때, 루프나 순환에 빠지지 않도록 조심해야한다.
- 로봇들은 순환을 피하기 위해 반드시 그들이 어디를 방문했는지 알아야 한다.
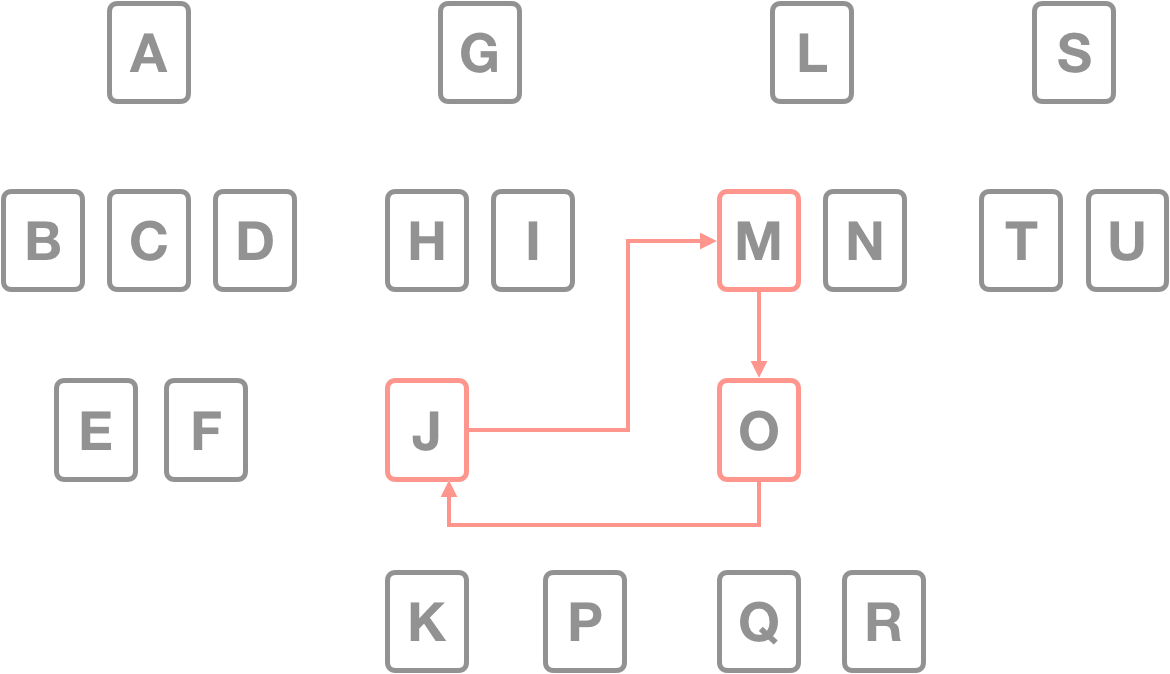
1.3.1 순환이 해로운 이유
순한은 크롤러에게 해롭다.
- 같은 페이지들을 반복해서 가져오는데 모든 시간을 허비하게 만들 수 있다.
- 네트워크 대역폭을 다 차지하고 때문에 그 어떤 페이지도 가져올 수 없게 되어버릴 수 있다.
- 웹 서버에 부담이 된다.
- 크롤러의 네트워크 접근 속도가 빠르다면, 웹사이트를 압박하여 어떤 실제 사용자도 사이트에 접근할 수 없도록 막아버리게 될 수도 있다.
- 루프 자체가 문제가 되지 않더라도, 크롤러는 많은 수의 중복된 페이지들을 가져오게 된다.
- dups
- 크롤러의 어플리케이션은 자신을 쓸모없게 만드는 중복된 콘텐츠로 넘쳐나게 될 것이다.
1.3.2 빵순환을 피하기 위해 방문을 기록 (부스러기의 흔적 Breadscrumb)
- 방문한 곳을 지속적으로 추적하는 것은 쉽지 않다.
- URL이 상당히 많기 때문에, 어떤 URL을 방문했는지 빠르게 판단하기 위해서는 복잡한 자료 구조를 사용할
필요가 있다.
- 자료구조는 속도와 메모리 사용 면에서 효과적이어야 한다.
- 검색 트리나 해시 테이블을 필요로 할 것이다.
트리와 해시테이블 / 느슨한 존재 비트맵 / 체크포인트 / 파티셔닝
- 트리와 해시테이블
- 방문한 URL을 추적하기 위해 검색 트리나 해시 테이블을 사용했을 수도 있다.
- 느슨한 존재 비트맵 Lossy presence bit maps
모르겠다. url을 숫자형태의 비트로 만들어서 저장하고, 같은 존재비트가 있으면 이미 크롤링되었다고 간주하는 듯
- 느슨한 자료구조
- 각 URL은 해시 함수에 의해 고정된 크기의 숫자로 변환되고, 배열 안에 대응하는 존재 비트를 갖는다. presence bit
- URL이 크롤링 되었을 때, 해당하는 존재 비트가 만들어진다. 존재비트가 이미 존재한다면 크롤러는 그 URL을 이미 크롤링 되었다고 간주한다.
- 체크포인트 checkpoint
- 로봇 프로그램이 갑작스럽게 중단될 경우를 대비해, 방문한 URL의 목록이 디스크에 저장되었는지 확인한다.
- 파티셔닝 Partitioning
- 웹이 성장하면서 한대의 컴퓨터에서 하나의 로봇이 크롤링을 완수하는 것이 불가능
- 로봇들이 서로 도와 웹을 크롤링한다.
- 개별 로봇들은 URL들을 이리저리 넘겨주거나, 오동작하는 동료를 도와주거나, 그 외의 이유로 그들의 활동을 조정하기 위해 커뮤니케이션을 한다.
1.4 URL 정규화
별칭(alias)과 로봇 순환
- 올바른 자료 구조를 갖추었더라도, URL이 별칭을 가질 수 있는 이상 어떤 페이지를 이전에 방문했었는지 말해주는 게 쉽지 않을 때도 있다.
- 한 URL이 또 다른 URL에 대한 별칭이라면, 그 둘이 서로 달라 보이더라도 사실은 같은 리소스를 가리키고 있다.
같은 문서를 가리키는 다른URL들
- 기본 포트가 80번일 때
- 이스케이프 문자가 원래 문자와 같을때
- 태그에 따라 페이지가 바뀌지 않을 때
- 서버가 대소문자를 구분하지 않을 때
- 기본 페이지가 index.html일 때
- 도메인과 ip 주소
URL 정규화를 통해 alias 회피
- 웹 로봇은 URL들을 표준 형식으로 정규화 함으로써 다른 URL과 같은 리소스를 가리키고 있음이 확실한 것들을 미리 제거하려 시도한다.
WIP..
- HTTP 완벽가이드 책을 보고 이해한 내용을 정리 한 글입니다.
참고자료
Related
2020년 2월 3일
2020년 1월 20일
2020년 1월 13일