Back to Posts
2019년 11월 15일
클라이언트 식별

현대의 웹 사이트들은 개인화된 서비스를 제공하고 싶어한다. 개인화를 하는 방법은 여러 가지가 있다.
- 개별 인사 / 사용자 맞춤 추천 / 저장된 사용자 정보
- 세션 추적: 웹사이트는 각 사용자에게서 오는 HTTP 트랜잭션을 식별할 방법이 필요하다.
- 사용자 식별 관련 정보를 전달하는 HTTP 헤더
- IP 주소로 사용자를 식별
- 사용자 로그인 인증을 통한 사용자 식별
- URL에 식별자를 포함하는 뚱뚱한 URL
- 식별 정보를 지속해서 유지하는 쿠키
1. HTTP 헤더
From(요창): 사용자 이메일 주소User-Agent(요청): 사용자의 브라우저Referer(요청): 사용자가 현재 링크를 타고 온 근원 페이지
From
- 사용자의 이메일 주소를 포함한다.
- 악의적인 서버가 이메일 주소를 모아서 스팸 메일을 발송하는 문제가 있어서 From 헤더를 보내는 브라우저는 많지 않다.
- 로봇이나 스파이더는 데이터를 수집하는 과정에서 본의 아니게 웹 사이트에 문제를 일으켰을 때, 해당 사이트의 웹 마스터가 항의 메일을 보낼 수 있도록 From 헤더에 이메일 주소를 기술한다.
User-Agent
- 사용자가 쓰고 있는 브라우저의 이름과 버전 정보
- 운영체제에 대한 정보까지 포함하여 서버에게 알려준다.
- 특정 사용자를 식별하는 데는 큰 도움이 되지 않는다.
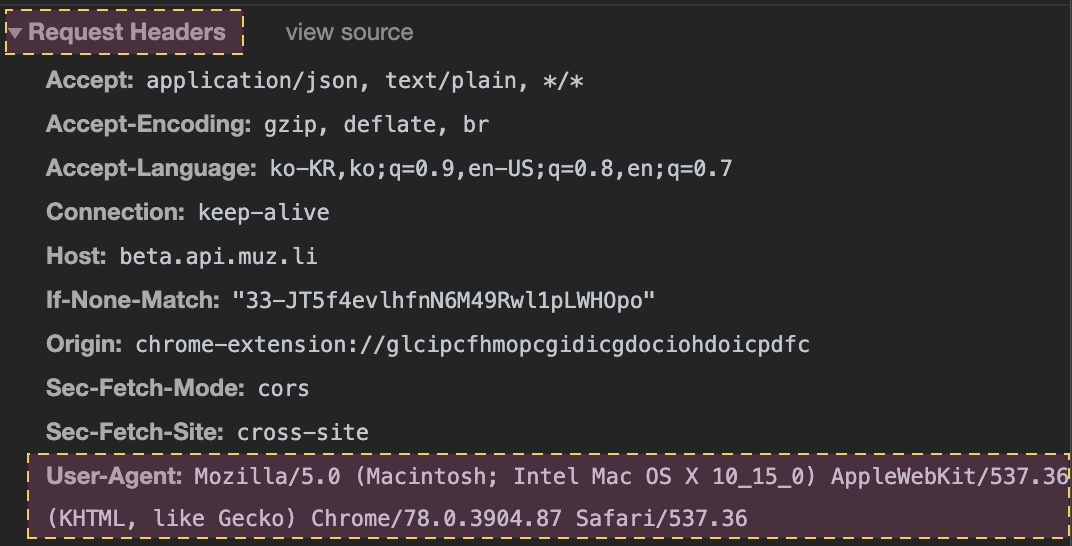
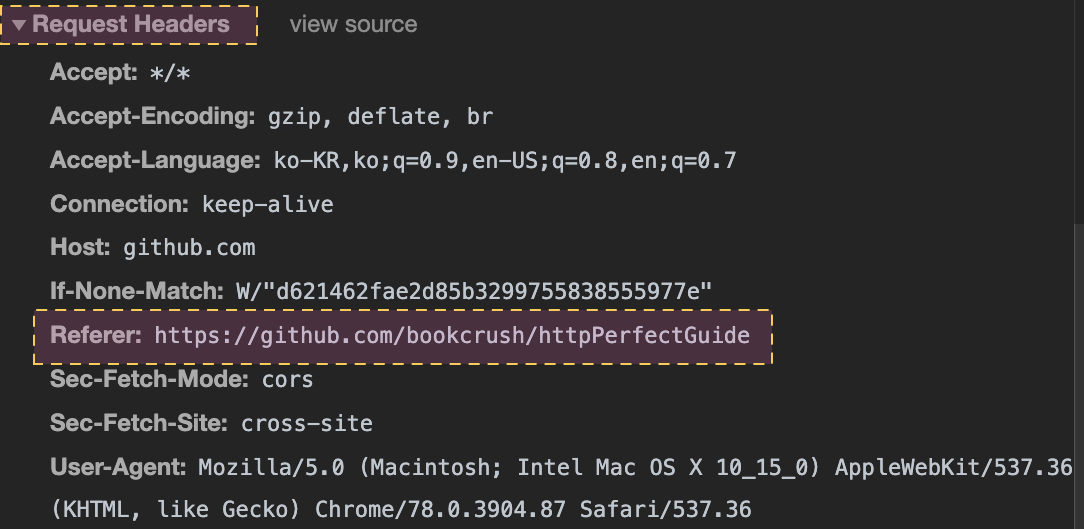
Referer
- 사용자가 현재 페이지로 유입하게 한 웹페이지의 URL을 가리킨다.
- 사용자의 웹 사용 형태나 사용자이 취향을 더 잘 파악할 수 있다.(?)
2. 클라이언트 IP 주소
- 초기 웹 선구자들은 사용자 식별에 클라이언트 IP 주소를 사용하려 했다.
- 주소가 좀처럼 바뀌지 않고, 웹 서버가 요청마다 클라의 IP를 알 수 있다면 문제없이 동작한다.
- 웹 서버는 HTTP 요청을 보내는 반대쪽 TCP 커넥션의 IP 주소를 알아낼 수 있다.
- 이 방식을 제대로 동작하지 않아서 사용하지 않는다.
단점
- IP 주소는 사용자가 아닌, 사용하는 컴퓨터를 가리킨다. 즉, 여러 사용자가 같은 컴퓨터를 사용하면 식별할 수 없다.
- ISP(인터넷 서비스 제공자)는 사용자가 로그인하면 동적으로 IP 주소를 할당한다. 로그인 시간에 따라 사용자는 매번 다른 주소를 받으므로, 웹 서버는 사용자를 IP 주소로 식별할 수 없다.
- 보안을 강화하고, 부족한 주소를 관리하려고 많은 사용자가 네트워크 주소 변환 방화벽을 통해
인터넷을 사용한다. (Network Address Translation, NAT)
- 이 NAT 장비들은 클라의 실제 IP 주소를 방화벽 뒤로 숨기고, 클라의 실제 IP 주소를 내부에서 사용하는 하나의 방화벽 IP 주소로 변환한다.
-
- HTTP 프락시와 게이트웨이는 원서버에 새로운 TCP 연결을 한다. 웹 서버는 클라 IP 주소 대신 프락시 서버 IP 주소를 본다.
- 일부 프락시는 원본 IP 주소를 보존하려고
Client-ip나X-Forwarded-For같은 확장 헤더를 추가하여 이 문제를 해결하려 했다.X-Forwarded-For HTTP 프록시나 로드 밸런서를 통해 웹 서버에 접속하는 클라이언트의 원 IP 주소를 식별하는 사실상의 표준 헤더다.
- 모든 프락시가 이런 식으로 동작하진 않는다.
3. 사용자 로그인 인증
-
웹 서버는 사용자 이름과 비밀번호로 인증할 것을 요구해서, 사용자에게 명시적으로 식별 요청을 할 수 있다.
-
웹 사이트 로그인이 더 쉽도록
WWW-Authenticate와Authorization헤더를 사용해 웹 사이트에 사용자 이름이 전달하는 자체적인 체계를 가지고 있다.- WWW-Authenticate
- Authorization HTTP Authorization 요청 헤더는 서버의 사용자 에이전트임을 증명하는 자격을 포함하여, 보통 서버에서 401 Unauthorized 상태를 WWW-Authenticate 헤더로 알려준 이후에 나옵니다.
-
한번 로그인하면, 브라우저는 사이트로 보내는 모든 요청에 이 로그인 정보를 함께 보내므로, 웹서버느 그 로그인 정보는 항상 확인할 수 있다.
-
서버에서, 사용자가 사이트에 접근하기 전에 로그인을 시키고자 한다면 HTTP 401 Unauthorized 응답코드를 브라우저에 보낼 수 있다.
- www.joy.com 사이트로 요청
- 사용자의 식별 정보를 알지 못하므로 401 Unauthorized 코드를 내리고,
WWW-Authenticate헤더를 반환하여 로그인하라고 요청한다. - 로그인 후
Authorization헤더에 토큰을 포함하여 전송하여, 사용자 식별을 시도한다. - 한번만 로그인하면, 브라우저는 요청마다 해당 사용자의 식별 토큰을 Authorization헤더에 담아서 서버로 전송해서, 한 세션이 진행되는 내내 그 사용자에 대한 식별을 유지한다.
4. 뚱뚱한 URL
- 사용자의 URL마다 버전을 기술하여 사용자를 식별하고, 추적하였다.
- 사용자의 상태 정보를 포함하고 있는 URL을 뚱뚱한 URL이라고 부른다.
- 웹 서버와 통신하는 독립적인 HTTP 트랜잭션을 하나의 ‘세션’ 혹은 ‘방문’으로 묶는 용도로 뚱뚱한 URL을 사용할 수 있다.
- 사용자가 웹사이트에 처음 방문하면
- 유일한 ID가 생성되고,
- 그 값은 서버가 인식할 수 있는 방식으로 URL에 추가되며,
- 서버는 클라를 이 뚱뚱한 URL로 리다이렉트 시킨다.
- 서버가 뚱뚱한 URL을 포함한 요청을 받으면, 사용자 아이디와 관련된 추가적인 정보를 찾아서 밖으로 향하는 모든 하이퍼링크를 뚱뚱한 URL로 바꾼다.
단점
사용자를 식별하는 데 사용할 수 있지만, 문제가 있다.
- 😵못생긴 URL 뚱뚱한 URL은 새로운 사용자들에게 혼란을 준다.
- 🙅개인 정보때문에 공유하지 못하는 URL 뚱뚱한 URL은 특정 사용자와 세션에 대한 상태 정보를 포함하기 때문에 외부 공유 시 개인 정보를 공유하게 된다.
- 🔥부하
- 📦캐시를 사용할 수 없음 URL로 만든 것은, URL이 달라지기 때문에 기존 캐시에 접근할 수 없다.
- 서버 부하 가중 뚱뚱한 URL에 해당하는 HTML 페이지를 다시 그려야 한다.
- 🏃♀️이탈
- 초기화 사용자가 링크를 타고 다른 사이트로 이동하거나, 특정 URL을 요청해서 의도치 않게 뚱뚱한 URL 세션에서 이탈하기 쉽다. 이탈하게 되면 모든 진척사항들이 초기화되고 다시 처음부터 시작해야 될 것이다.
- 세션 간 지속성의 부재 북마킹하지 않는 이상, 로그아웃하면 모든 정보를 잃는다.
- HTTP 완벽가이드 책을 보고 이해한 내용을 정리 한 글입니다.
참고자료
Related
2020년 2월 3일
2020년 1월 20일
2020년 1월 13일