국제화

국제적인 콘텐츠를 다루기 위해 필요한 HTTP 지원
-
- HTTP에서 엔터티 본문이란 그저 비트들로 가득 찬 상자에 불과하다.
- 서버는 클라에게 문서의 문자와 언어를
Content-Type charset매개변수와Content-Language헤더를 통해 알려준다. - 클라는 서버에게 사용자가 어떤 언어를 이해할 수 있고, 어떤 알파벳의 코딩 알고리즘이 브라우저에
설치되어 있는지 말해줄 필요가 있다. **
Accept-Charset**과Accept-Language헤더를 보낸다
Accept-Language: fr, en;q=0.8
Accept-Charset: iso-8859-1, utf-8- 모국어를 선호하지만, 피치 못할 경우 영어도 사용하는 프랑스어 사용자가 보낸 케이스
- iso-8859-1 => 서유럽 차셋 인코딩과 utf-8 유니코드 차셋 인코딩을 지원할 것이다.
- q는 품질 인자로 프랑스어보다 영어에 낮은순위를 주었다. (기본은 1.0)
1. 문자 집합과 HTTP
1.1 Charset은 글자를 비트로 변환하는 인코딩이다.
-
- HTTP Charset 태그는 비트들을 글자로 변환하거나 (디코딩) 글자를 비트들로 변환하는 (인코딩)
알고리즘을 명명한다.
- HTTP Charset 태그는 비트들을 글자로 변환하거나 (디코딩) 글자를 비트들로 변환하는 (인코딩)
알고리즘을 명명한다.
- 몇몇 문자 인코딩 (utf-8이나 iso-2022-jp)은 글자당 비트 수가 일정하지 않아, 더 복잡한 가변길이 코드다.
- 이런 종류의 코딩은 중국어나 일본어와 같이, 많은 글자로 이루어진 문자체계를 지원하기 위해 추가적인 비트를 사용할 수 있게 해준다.
- 아랍어는 28개의 문자만을 갖는다. 8비트 256개의 유일한 값을 제공하므로, 라틴어, 아랍어, 그 밖의 유용한 기호들을 위한 충분한 공간이 된다.
1.2 문자집합과 인코딩은 어떻게 동작하는가
- 비트들을 문자로 변환하는 디코딩 알고리즘을 지칭하고 적용하는 표준화된 방법이 필요하다.
- 비트 => 문자로 변환 (의미 해석) - 02. HTTP
- 문자 => 모양으로 표현 (시각적 표현) - 브라우저, 운영체제, 글꼴이 결정
1.3 잘못된 Charset은 잘못된 글자들을 낳는다.
브라우저가 본문으로부터 225 (11100001)을 가져온 경우
- iso-8859-1 (서유럽 문자 코드) 인코딩 양음 악센트가 붙은 소문자 a =
á - iso-8859-6 (아랍 코드) :
FEH=ف - iso-8859-7 (그리스어) : 알파 =
α - iso-8859-8 (히브리어) :
BET=ב
1.4 표준화된 MIME Charset 값
- 특정 문자 인코딩과 특정 코딩된 문자집합의 결합을 MIME 차셋이라고 부른다.
-
- HTTP는 표준화된 MIME 차셋 태그를 Content-Type과 Accept-Charset 헤더에 사용한다.
MIME 차셋 인코딩 태그
- us-ascii : ascii로도 불리지만, 여러가지 국제 변형때문에 us라는 접두어를 붙이는 것을 선호한다.
- iso-8856-1(Latin1) : 서유럽 언어를 지원하기 위한 ascii를 확장
- iso-8856-2 : (체코어, 폴란드어, 루마니아어와 같은) 중부유럽 혹은 동부유럽 언어에서 사용되는 문자들을 포함시키기 위해 ascii를 확장
- iso-8856-5 : (러시아어, 세르비아어, 불가리아어 등에 사용되는) 키릴 문자를 포함하기 위해 ascii를 확장
- iso-8856-6 : 아랍 문자들을 포함하기 위해 ascii를 확장
- iso-8856-7 : 현대 그리스 문자를 포함하기 위해 ascii를 확장
- iso-8856-8 : 히브리어와 이디시어 문자를 위해 ascii를 확장
- iso-8856-15(Latin0) : 몇몇 구두점, 분수 기호들을 고대 프랑스어와 핀란드어 글자들로 대체하고, 국제 통화 기호를 새로운 유로 통화 기호로 대체하기 위해 iso-8859-1을 갱신한 것이다.
- iso-2202-jp : 일본어 전자우편과 웹 콘텐츠를 위해 널리 사용되는 인코딩
- euc-jp : 여러 종류의 모드나 이스케이프 문자열 없이 각 글자를 식별하기 위해 명시적 비트 패턴을 사용하는 iso 2022 호환 가변길이 인코딩이다.
- Shift-JIS : 마소에 의해 개발. 역사적인 호환성문제때문에 복잡, 모든 문자에 대응하지도 못하지만 여전히 흔하게 쓰이고 있다.
- koi8-r : 러시아어를 위한 인기있는 8비트 인터넷 문자집합 인코딩 이다.
- utf-8 : 전 세계의 문자들에 대한 보편적인 문자집합인 UCS를 표현하기 위한 흔히 쓰이는 가변길이 문자 인코딩 구조다.
- windows-1252 : 마소는 자신의 코딩됭 문자집합을 코드 페이지라고 부른다. 윈도우 코드페이지 1252는 iso-8859-1의 확장이다
euc-kr과 utf-8 참고 euc-kr 방식은 원래 영어만을 고려한 1byte 길이의 ASCII 라는 인코딩 방식을 확장하여 한글을 사용할 수 있도록 만든 2byte 길이의 국가 언어 코드입니다. 국가 언어코드. 즉 우리나라에서만 쓸 수 있도록 만든 코드이며 세계 어디에서나 공통으로 사용되는 인코딩 방식이 아니기 때문에, 다른 언어를 사용하는 환경(외국 등)에서는 한글 페이지를 제대로 볼 수 없는 문제가 발생합니다. 이를 해결하기 위해 새로운 인코딩 방식이 개발되었는데, 그중 가장 보편화된 인코딩이 UTF-8입니다. (3byte) 예전에는 용량이 작은 euc-kr 방식을 선호하는 곳들도 많았으나, 현재는 용량 문제보다 표준화 및 글로벌 환경을 고려해야 하므로 UTF-8 인코딩 방식을 강력하게 권고하는 바입니다.
1.5 Content-Type charset 헤더와 메타태그
- 웹 서버는 클라에게 MIME charset 태그를 charset 매개변수와 함께 Content-Type 헤더에 담아 보낸다.
Content-Type: text/html; charset=utf-8-
만약 나열되지 않았다면, 수신자는 문서의 콘텐츠로부터 문자집합을 추측하려고 시도한다.
-
받은 HTML 파일에서
meto태그중HTTP-EQUIV라는 속성을 갖고 있는 태그를 찾는다.<meta http-equiv="Content-Type" content="text/html; charset=utf-8" > -
만약 문서가 html이 아니라면, 혹은 meta Content-Type 태그가 없다면, 소프트웨어는 언어와 인코딩에 대한 일반적인 패턴을 찾기 위해 실제 텍스트를 스케닝하여 문자 인코딩을 추측한다.
-
클라가 문자 인코딩을 추측하지 못했다면
iso-8859-1인것으로 가정한다.
1.6 Accept-Charset 헤더
- 대부분의 클라는 모든 종류의 문자 코딩과 매핑 시스템을 지원하지는 않는다.
-
- HTTP 클라는 서버에게 정확히 어떤 문자 체계를 그들이 지원하는지 Accep-Charset 요청 헤더를 통해 알려준다.
- Accept-Charset 헤더의 값은 클라가 지원하는 문자 인코딩 목록을 제공해준다.
- 이 문자 인코딩 구조 중 어떤 것으로 콘텐츠를 반환할지는 서버의 자유다.
Accept-Charset: iso-8859-1, utf-82. 다중언어 문자 인코딩에 대한 지침
문자집합 용어
- 문자 : 글쓰기의 최소단위.
- 글리프 glyph
- 하나의 글자를 표현하기 위한, 획의 패턴이나 다른 것과 구분되는 유일한 시각적 형태
- 글자를 여러 방식으로 쓰는 것이 가능하다면, 글리프를 여러 개 가질 수도 있다.
- 코딩된 문자 coded character
- 각 글자에 할당된 유일한 숫자
- 국제 문자 셋트
- 코드 공간 coding space
- 각 문자 코드의 비트 개수
- ex) UTF-8 인코딩은 유니코드 한 문자를 나타내기 위해 1바이트에서 4바이트까지를 사용한다.
- 사용 가능 문자집합 character repertoire
- 글자들에 대한 특정한 작업 집합
- 코딩된 문자집합 coded character set
- 사용 가능 문자집합을 받아서, 각 글자에 코드 공간의 코드를 할당해주는 코딩된 문자들의 집합.
- 실제 글자들에 숫자로 된 문자코드를 대응시킨 것
- 문자 인코딩 구조
- 숫자로 된 문자 코드들을 콘텐츠 비트의 연속으로 인코딩하는 알고리즘.
자세히 알아보기
- 문자
- 하나의 문자는 하나의 알파벳 글자, 숫자, 구두점, 표의문자(중국어에서와 같은), 수학기호, 그 외에 다른 쓰기의 기본 단위
- 문자는 글꼴이나 스타일에 독립적이다.
- 같은 글자라도 그 글자가 단어에서 어디에 위치하느냐에 따라 각각 다른 모양을 갖는 표기 체계도 많다.
- 글리프(glyphs), 연자(ligatures), 표현형태
- 글리프는 각 글자를 그리는 특정한 방법니다.
- 글꼴이나 사소한 미적 양식에 의존하지 않는, 글자에 내재된 모양새이다.
- 연자 ligatures
- FI 연자 / LA연자
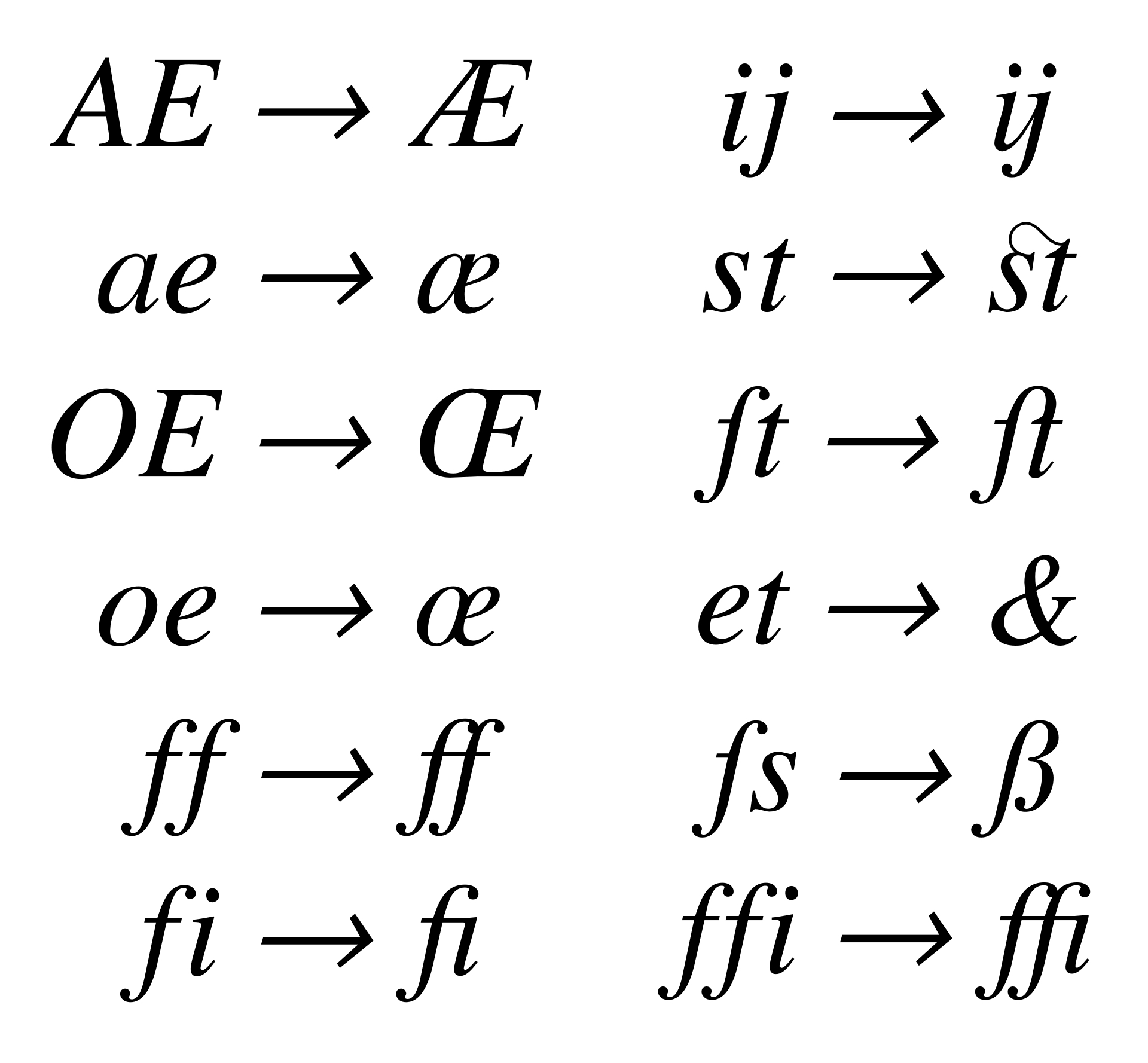
- FI 연자 / LA연자
- 코딩된 문자집합 Coded Character Set
- 코딩된 문자집합은 정수를 글자로 대응시킨다.
- 코딩된 문자집합은 보통 코드번호로 인덱싱된 배열로 구현된다.
- 그 배열의 원소들은 문자들이다.
-
US-ASCII (모든 문자집합의 어머니)
- 1968년 ANSI 표준 X3.4 ‘정보교환을 위한 미국 표준 코드’로 표준화된 가장 유명한 코딩된 문자집합이다.
- 아스키는 오직 코드 값 0~127만 사용한다.
- 코드 공간을 전체 표현하는데 7비트만 필요하다.
- 다른 국제 변종과 구분하기 위해 ‘US-ASCII’를 더 선호한다.
-
iso-8859
- US-ASCII 의 8비트 확대 집합들이다.
- 국제적인 글쓰기를 위해 필요한 글자들을 하이비트를 이용하여 추가
- 추가비트에 의해 제공되는 추가공간은 모든 유럽 글자를 담기에는 충분히 크지 않으므로,
iso-8859는 지역에 따라 커스터마이징된 문자집합을 제공한다.
- iso-8859-1 : 서유럽어 (영어, 프랑스어) (= Latin1) - HTML을 위한 기본 문자집합
- iso-8859-2 : 중앙 및 동유럽어 (체코어, 폴란드어)
- iso-8859-3 : 남유럽어
- iso-8859-4 : 북유럽어
- iso-8859-5 : 키릴 (불가리아어, 러시아어, 세르비아어)
- iso-8859-6 : 아랍어
- iso-8859-7 : 그리스어
- iso-8859-8 : 히브리어
- iso-8859-9 : 터키어
- iso-8859-10 : 노르딕어 (아이슬랜드어, 이뉴잇어)
- iso-8859-15 : 새로운 유로 통화 문자를 포함하기 위한 iso-8859-1의 변형
- US-ASCII 의 8비트 확대 집합들이다.
-
JIS X 0201
- 일본어 가타카나 반각문자를 더해, 확장한 극단적으로 작은 문자집합
- = JIS ROMAN 으로 불린다. (JIS = Japanese Industrial Standard = 일본 산업 표준)
-
JIS X 0208과 JIS X 0212
- 일본어는 여러 문자 체계로부터 온 수천개의 글자를 담고 있다.
- JIS X 0201의 63개 표음 가타카나 문자보다 완전한 문자집합이 필요하다.
- JIS X 0208은 최초의 멀티바이트 일본어 문자집합이다. = 일본식 한자인 6879개의 코딩문자를 정의했다.
- JIS X 0212 문자집합은 6607개의 문자를 추가했다.
-
UCS
- 국제 문자 셋트 Univeral Character Set 은 전 세계의 모든 글자를 하나의 코딩된 문자집합으로 통합하려 노력하는 세계적인 표준이다.
- UCS는 ISO 10646으로 정의된다.
- 유니코드는 UCS 표준을 따르는 상업적인 컨소시업이다.
- UCS는 기본 집합은 단 50,000 글자만으로 이루어져 있음에도 불구하고, 수백만개의 글자를 위한 코드공간을 갖고 있다.
-
문자 인코딩 구조
- 숫자로 된 문자 코드를 콘텐츠 비트들로 변환
- 다른 쪽에서는 그들을 다시 문자코드로 환원한다.
- 문자 인코딩 구조는 3종류로 분류할 수 있다. (고정폭/가변폭(비모달)/가변폭(모달))
-
고정폭
- 각 코딩된 문자를 고정된 길이의 비트로 표현한다.
- 빠르게 처리될 수 있지만 공간을 낭비할 우려가 있다.
-
가변폭 (비모달)
- 다른 문자 코드 번호에 다른 길이의 비트를 사용한다.
- 자주 사용하는 글자의 비트 길이를 줄일 수 있고, 국제 문자에 대해서는 여러 바이트를 사용하도록 함으로써 이전의 8비트 문자집합과의 호환성도 유지할 수 있다.
-
가변폭 (모달)
- 다른 모드로의 전환을 위해 특별한 escape 패턴을 사용한다.
- 예를 들어 어떤 모달 인코딩은 텍스트에서 중첩된 여러가지 문자집합 간의 전환을 위해 사용될 수 있다.
- 모달 인코딩은 처리하기 복잡하지만, 복잡한 표기 체계를 효과적으로 지원해 줄 수 있다.
-
[고정폭] 8비트
- 간단히 각 문자 코드를 그에 대응하는 8비트 값으로 인코딩한다.
- 256개 문자의 코드 범위에 대한 문자집합만을 지원한다.
- iso-8859 문자집합군은 8비트 아이덴티티 인코딩을 사용한다.
-
[가변폭(비모달)] UTF-8
- 인기있는 UCS를 위해 설계된 문자 인코딩 구조다. (UTF = UCS Transformation Format)
- 첫 바이트의 서두 비트들은 인코딩된 문자의 길이를 바이트 단위로 나타내고, 그 이후의 바이트들은 각 6비트 코드값을 담는다. (0ccccccc, 110ccccc,…)
- 문자 코드 90(아스키 ‘Z’)는 1바이트로 인코딩 되었을 것이며(01011010), 코드 5073(13비트 이진값 100111101001)은 3바이트로 인코딩되었을 것이다.
-
[가변폭(모달)]iso-2022-jp
- 일본어 인터넷 문서를 위해 널리 사용되는 인코딩이다.
- 128보다 작은 값으로만 이루어진 가변길이 모달 인코딩이다.
- 인코딩 콘텍스트는 4가지 미리 정의된 문자집합 중 하나로 설정된다.
- 특별한 이스케이프 문자열(
ESC ( B,ESC ( J,ESC $ @,ESC $ B)은 한 집합에서 다른 집합으로 전환시켜준다. (모달)
- 특별한 이스케이프 문자열(
-
[가변폭(비모달)]euc-jp
- 일본어 인코딩
- EUC는 Extended Unix Code의 약자
- 유닉스 운영체제에서 아시아 문자들을 지원하기 위해 처음 개발되었다.
- 모드간의 전환을 위한 이스케이프 문자열이 없다.
- euc-jp는 4가지 코딩된 문자집합을 지원한다. (JIS X 0201, JIS X 0208, 반각 가타카나, JIS X 0212)
-
[가변폭(비모달)]euc-kr
- 한글 인터넷 문서를 위해 널리 사용되는 가변길이 인코딩
- 2가지 문자집합을 지원한다. (KS X 1003, KS X 1001)
- KS X 1001은 총 2350자만 담고 있었고 표현하기에는 부족
- 이를 보완하기 위해 한글 채움문자를 이용해 한글을 표현하는 방식을 규정하고 있다.
Charset은 문자집합이 아닌 매핑 알고리즘의 이름이다.
- MIME charset 태그는 문자집합을 의미하는 것이 아니다.
- MIME charset 값은 데이터 비트를 고유한 문자의 코드로 매핑하는 알고리즘의 이름이다. = 문자 인코딩 구조 + 코딩된 문자집합
언어태그와 HTTP
- 영어 en / 독일어 de / 한국어 ko 많은 다른 언어에 대한 언어 태그가 존재한다.
- 브라질 포르투갈어 pt-BR / 미국 영어 en-US / 허난 중국어 zh-ziang 지역에 따라 변형된 언어나 방언을 표현할 수 있다.
- Content-Language 헤더
- Content-Language 엔터티 헤더 필드는 엔터티가 어떤 언어 사용자를 대상으로 하고 있는지 서술한다.
- Accept-Lanugage 헤더
-
- HTTP는 우리에게 우리의 언어 제약과 선호도를 웹 서버에 전달할 수 있게 해준다.
- Accept-Lanugage와 Accept-Charset을 사용할 수 있다.
- 언어 태그의 종류 ([RFC 3066] 기준)
- 언어태그는 다음을 표현하기 위해 사용될 수 있다.
- 일반적인 언어의 종류 ex_
es(스페인어) - 특정 국가의 언어 ex_
en-GB(영국 영어) - 방언 ex_
no-bok(노르웨이어의 Book Language를 의미) - 지방어 ex_
sgn-US-MA(마서스 비니어드 섬의 수화) - 그외의 다른 언어의 변형이 아닌 표준언어 (ex_
i-navajo) - 비표준 언어 ex_
x-snowboarder-slang(스노우보드 타는 사람..)
- 일반적인 언어의 종류 ex_
- 서브태그
- 언어 태그는 하이픈으로 분리된 하나 이상의 서브태그로 이루어져 있다.
- ex_
sgn-US-MA
- 주 서브태그 : 표준화되어 있다. - 알파벳만
- 두번째 서브태그: 자신만의 이름 표준을 따름 (선택적) - 알파벳 + 숫자가능 (최대 8글자)
- 서브태그는 등록되어 있지 않다.
-
첫번째 서브태그 : 이름공간
- ISO 639 표준 언어 집합에서 선택된 표준화된 언어 토큰
- 첫번째 서브태그가
- 두 글자라면, ISO 639와 639-1 표준의 언어코드다.
- 세 글자라면, ISO 639-2표준과 확장에 열거된 언어코드다.
- 글자가
i라면, IANA에 등록된 것 - 글자가
x라면, 특정 개인이나 집단 전용의 비표준 확장 서브태그다.
- 한국어 : ko(ISO 639) / kor(ISO 639-2)
- 영어 : en(ISO 639) / eng(ISO 639-2)
-
두번째 서비태그: 이름공간
- ISO 3166 국가 코드와 지역 표준 집합에서 선택된 표준화된 국가토큰이다.
- IANA에 등록된 다른 문자열일 수도 있다.
- 두번째 서브태그는
- 두글자라면 ISO 3166에 정의된 국가/지역이다.
- 3~8 글자라면, IANA에 등록된 것이다.
- 한글자라면, 문가 잘못된 것..
- 일본: JP
- 인도: IN
- ISO 3166 국가 코드와 지역 표준 집합에서 선택된 표준화된 국가토큰이다.
-
나머지 서브태그: 이름공간
- 8자 이하의 알파벳과 숫자로 이루어져야 한다는 것을 제외하면 다른 규칙은 없다.
국제화된 URI
- 오늘날 URI는 US-ASCII의 부분집합으로 구성되어 있다.
- 국제적 가독성 vs 의미있는 문자들
- URI에 들어가고 조작하고, 공유하기 쉽게 하기 위하여 설계자들은 매우 제한된 공통 문자집합을
선택했다.
- 기본적인 라틴 알파벳 문자, 숫자, 특수문자
- 단점
- URI는 비영어권 사람들도 쉽게 사용하고, 기억할 수 있도록 설계되지는 못했다.
- 전 세계 사람들이 라틴 알파벳을 인식조차 하지 못하기 때문에 URI를 추상화 패턴으로 기억하는 것은 거의 불가능
- URI 저자들은 리소스 식별자의 가독성과 공유 가능성의 보장이 대부분의 의미 있는 문자들로 구성될 수 있도록 하는 것이 더 중요하다고 여겼다.
- 그래서 아스키 문자들의 제한된 집합으로 이루어진 URI를 갖게 되었다.
- URI에서 사용될 수 있는 문자들
- URI에서 사용할 수 있는 US-ASCII 문자들의 부분집합은
- 예약된 문자들,
- 예약되지 않은 문자들,
- 이스케이프 문자들로 나뉜다.
- 예약되지 않은 문자들은 일반적으로 사용될 수 있다.
- 예약된 문자들은 URI에서 특별한 의미를 가지며, 일반적으로는 사용될 수 없다.
- 예약되지 않은 문자: [A-Za-z0-9]
-_.!~*'() - 예약된 문자:
;/?:@&=+$, - 이스케이프:
%<HEX><HEX>
- 이스케이핑과 역이스케이핑
- URI 이스케이프는 예약된 문자나 다른 지원하지 않은 글자들(space)을 안전하게 URI에 삽일할 수 있는 방법을 제공한다.
- 이스케이프 : 퍼센트 글자 하나와, 뒤이은 16진수 글자 둘로 이루어진 3글자 문자열이다.
%(아스키 25): %25
- URI를 해석할 때,
- 이스케이핑된 코드 바이트들을 (
encodeURIComponent메서드를 사용하면 URI 인코딩을 진행할 수 있다.) - 원래 ASCII 코드 바이트로 변한하여 해석한다.
- 이스케이핑된 코드 바이트들을 (
- 두번 인코딩 되지 않도록 주의한다.
- 국제 문자들을 이스케이핑하기
- 이스케이프 값들은 US-ASCII 코드의 범위(0~127)에 있어야한다.
- 어떤 어플리케이션은 iso-8859-1 확장 문자들(128~255)을 표현하기 위해 이스케이프 값을 사용하려 한다.
- 그러나 오늘날에는 아스키 범위 밖의 문자를 인코딩하는 일은 상당히 흔하다.
- URI에서의 모달 전환
- 몇몇 URI는 다른 문자집합의 글자를 표현하기 위해 아스키 문자열을 사용한다.
- 예를 들어 iso-2022-jp 인코딩은 JIS-Roman으로 변경하기 위해
ESC ( J를 삽입할 수 있으며ESC ( B로 다시 아스키로 돌아올 수 있다.
- 예를 들어 iso-2022-jp 인코딩은 JIS-Roman으로 변경하기 위해
- 현재 URI는 그다지 국제화에 친화적이지 않다.
- 당분간 HTTP 어플리케이션은 아스키와 함께 써야한다.
기타 고려사항
- 헤더와 명세에 맞지 않는 데이터
-
- HTTP 헤더는 반드시 US-ASCII 문자집합의 글자들로만 이루어져야 한다.
- 많은 HTTP 어플리케이션은 글자들을 처리하기 위해 운영체제와 라이브러리 루틴을 사용한다.
- 이 모든 라이브러리가 아스키 범위(0~127)를 벗어난 글자를 지원하지 않는다.
- 날짜
-
- HTTP명세는 올바른 GMT 날짜 형식을 명확히 정의하고 있지만, 모든 웹 서버와 클라가 규칙을 따르고 있지 않음을 주의하라.
- 도메인 이름
- 국제화 문자를 포함하는 도메인 이름을 = 국제화 도메인 이름 Internationalizing Domain Name
- 오늘날 대부분의 웹브라우저가 퓨니코드를 이용해 이를 지원한다. punycode
- 퓨지코드란 유니코드 문자열을 호스트 명에서 사용 가능한 문자만으로 이루어진 문자열로 변환하는 방법 (RFC 3492)
- 웹브라우저들은 이 기법을 이용해, 사용자가 입력한 다국어로 된 도메인 이름을 알파벳과 숫자 등으로
된 도메인 이름으로 변환한다. (
한글.com=>xn--bj0bj06e.com)
- HTTP 완벽가이드 책을 보고 이해한 내용을 정리 한 글입니다.
참고자료