Back to Posts
2020년 7월 2일
예측 분석이란? (2장)

예측 분석이란?
마케터가 알아야할 예측분석
- 자율학습 (군집화모델)
- 데이터속의 숨겨져있는 패턴을 찾아낸다.
- 감독학습 (경향성 모델 또는 예측)
- 입력 샘플과 목적변수를 학습하여, 어떤 입력값이 주어졌을 때, 출력값을 추정하는 데 사용
- 고객평생가치 engage 가능성 / 다음에 구매할 가능성이 있는 특정한 제품을 추정
- 강화학습 (추천기능)
- 데이터속의 숨겨진 패턴과 유사성을 지렛대 삼아 사용자 또는 특정 이벤트에서 최적의 다음단계, 결과, 제품, 콤텐츠를 정확하게 에측할 수 있게해준다.
1. 자율학습: 군집화 모델 cluster
- 당신이 찾고 있는 것이 무엇인지 미리 알지 못하거나, 명시적 변수명을 사용하지 않고도 데이터의 패턴을 인식해내는 것
- 이러한 접근법 중 하나를 군집화 cluster
- 행위가 유사한 고객을 그룹화함으로써 이 그룹의 패턴이 어떤 것인지 드러날 수도 있다.
군집화와 세분화의 차이점 clustering, segmentation
- 세분화
segmentation
- 유사성을 기반으로 고객들을 여러 그룹에 각기 수동으로 배치하는 프로세스
- 타깃으로 삼을 사람을 사전에 알고 있다.
- 군집화
clustering
- 고객을 그룹으로 묶을 수 있도록 그들 내의 유사성들을 찾아내는 자동화된, 통계적으로 엄격한
프로세스이다.
- 누구를 타깃으로 삼을 것인지 발견하는 것 ⇒ 고객에 대해 이미 알고있는 속성들을 사용하여 회사의 고객 기반 속에 존재하는 세그먼트들을 자동으로 발견해내는 방법
- 군집화 알고리즘
- K-means
- Apriori
- 군집화를 알고리즘은 더 많은 차원을 검토한다.
- 마케터들은 이제 브랜드 선호도, 할인 선호도, 웹사이트에 머문시간, 웹페이지 열람행위, 통화길이 등 수백가지 고객특성 feature을 확보하고 있다.
- 하나의 고객군집은 일반적으로 약 8~15개의 속성을 통해서 설명된다.
- 자동으로 발견된, 마케팅 대상으로 삼을 수 있는 페르소나로 간주할 수 있다.
2. 감독학습: 경향성 모델 (= 반응모델 response models = 우도모델 likelihood)
-
경향성 모델은
과거의 사례들을 통해 학습함으로써, 고객의 미래 행위를 예측해낸다는 점- 예_ 고객이 제품을 구매할 가능성 또는 예상 고객이 웹사이트에서 뭔가 행동할 가능성
-
반응모델 **
response models**라고도 종종 불린다.- 다이렉트 메일을 수신한 결과로 제품을 구매하게 될지 아닐지와 같은 고객반응을 예측하기 때문
-
우도 모델 (
likelihood,가능성)- 알고리즘
- 신경망 neural networks
- 로지스틱 회귀 logistic regression
- 랜덤 포레스트 random forest
- 회귀 트리 regresstion trees
- 알고리즘
-
가이드 학습 guided-learning 모델이다. = 데이터를 학습하는데 시간이 걸린다는 것 = 시간이 지남에 따라 모델이 더 나아진다는 것을 의미
- 대부분의 경향성 모델은 예측을 위해 사용하기 전에 짧은 훈련기간과 검증 기간을 필요로 한다.
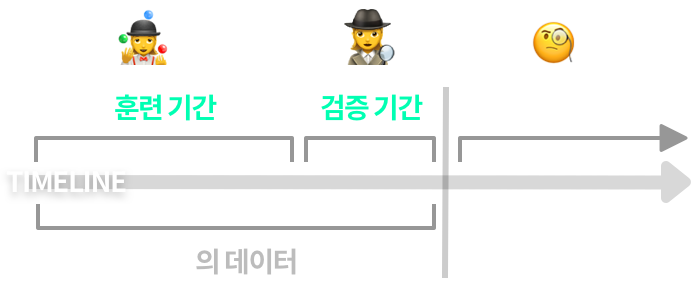
경향성 십분위를 사용하는 법 deciles
십분위
- 개별 고객 점수 대신에 대부부의 실무자는 고객을 10분위로 나눈다.
- 예_고객이 평생동안 얼마나 돈을 쓸 것인지 예측하려면? 평생가치 예측 모델이라고 불리느 것을 사용한다.
- 2가지 측명에서 유용
- 평생가치 또는 지출과 같이 기업이 기대하는 행위에 대한 평균값을 제공한다.
- 고객들을 동일한 크기의 묶음 bucket 10개로 나누어, 그 중에서 가장 가치가 높은 것부터 가장 낮은것까지, 또는 구매할 가능성이 가장 높은 것부터 가장 낮은 것까지 순위를 매길 수 있도록 해준다.
- 예
- 값비싼 카탈로그를 누구에게 보낼지 결정할때
- a/b 행상도 테스트를 설계하 ㄹ때
- 이탈한 웹사이트 방문자를 대상으로 한 캠페인
- 비구매자들을 추적할 수 있는 많은 리타겟팅 솔루션들을 이용할 수 있다.
- 구매 가능성에 따라 고객에게 제공하는 혜택을 차별화할 수 있다면?
- 구매 가능성이 높은 사람 ⇒ 리마인드 메세지만으로 지갑을 열게 함
- 구매 가능성이 낮은 사람 ⇒ 할인 또는 무료배송 제안
- 이 유형의 모델은 예상 고객과 기존 고객의 미래 행위를 예측하는데 사용할 수 있다.
- 예_ 구찌 핸드백을 구입한 순간부터
- 이 사치품 업체는 내가 앞으로 핸드백을 몇개나 더 구매할지에 대해서 높은 정확도로 예측할 수 있다.
- 구찌의 알고리즘은 나의 구매, 웹사이트 방문, 이메일 클릭이나 나의 연령, 성별, 지역 등을 이전에 구매한 수천명의 다른 고객의 행동 미 인구사회학적 특징과 비교한다.
- 미래 구매행위를 나보다 더 잘 예측할 수 있다.
경향성 모델과 RFM 모델링의 비교
RFM 모델링
-
예측분석이 널리 보급되기 전에는 RFM이라고 불리는 모델이 구매 가능성이 높은 사람을 파악하는 업계 표준 방식이었다.
- 그 효용이 제한적, 현실 생활에 적용하기가 생각보다 너무 어렵다.
- 통계적, 예측적 기반이 없는, 단순한 경험적 접근방식일 뿐이다. (주먹구구식으로 나름 지적인 추측을 하는)
-
이 모델의 핵심 아이디어는
- 한 고객이 다른 제품을 최근에 구입했거나, 자주 구입했거나, 당신의 제품에 많은 돈을 지출하였다면 그 고객은 당신의 제품을 다시 구매할 가능성이 높다는 것이다.
- 시기 : 이 고객이 우리 제품을 마지막으로 구입한 이래로 며칠이 지났는가?
- 빈도 : 그 고객은 우리 제품을 얼마나 자주 구매했는가?
- 금액 : 그 고객은 우리에게 얼마나 많은 매출을 가져다 주었는가?
-
데이터에서 파생될 수 있는 많은 다른 변수들 중에는 추가적으로 우수한 예측 변수로 사용할 수 있는 것들이 있지만, 이 모델리에서는 변수 사용을 많이 안하는 방법이다.
-
과거의 결과가 미래의 성과를 보장하지 못한다가 적용되는 방법이다.
-
한 고객의 현재 행동을 과거 다른사람들의 이후 행동과 비교하기 보다는, 오로지 해당 고객의 과거에 대해서만 되돌아본다.
-
높은 가치의 고객이 실제로 구매를 하기 전에는 이들을 인지할 수 없다.
-
예
- 대부분의 고객이 3번 구매한 다음 사라진다면
- 이미 3번 구매한 어떤 고객이 다시 구매할 가능성은 사실 매우 낮지만
- RFM모델은 이 고객을
구매 가능성 매우 높음이라는 세그먼트에 배치할 것이다.
- RFM모델은 이 고객을
- 반응을 할 가능성이 높은 좋은 고객이 ⇒ 가치가 그다지 높지 않은 세그먼트에 포함될 수도 ⇒ 프로모션 발송대상에서 제외될 수도
-
구매가 빈번한 환경에서만 향후 구매할 가능성에 대한 예측을 할 수 있다.
- 감독학습 모델은 이러한 모든 고객 행위를 예측하는 데 사용할 수 있다.
- 경향성 모델은 RFM모델보다 평균 40% 더 정확
3. 강화학습 및 협업 필터링
(reinforcement learning, collavorative filtering)
- 강화학습은 일반적으로 협업필터링 모델과 함께 사용된다.
- 협업필터링 모델의 일반적인 마케팅 응용 프로그램은 ⇒
추천 - 추천모델
- 협업 필터링
- 베이지안 네트워크 bayesian networks
- 빈발 항목집합 frequent item sets
- 시간가중치 time-decay
- 최근 행동이 이전 행동보다 예측에 대한 가중치가 더 크다는 사실을 감안하기 위해서
- 강화학습은 고객의 선호에 조응하도록(꼭 맞게 대응함) 모델을 교육하기 위해 적용된다.
고객이 처한 맥락에 맞는 추천을 하는 것이 중요하다.
- 잘못된 추천 또는 맥락을 벗어난 추천은
- 불쾌한
- 간섭하는
- 부적합한 것으로 간주된다.
- 추천하는 시점도 적절해야한다.
- 예
- 장바구니 결제시 ‘이것을 구입한 고객은 또한 XX도 추가했다’
- 2일 후에 후속구매를 제안하는 감사 이메일
- 예
- 추천이유를 제공하기 시작
- 간섭적 특성을 제거하기 위해
- 아마존
- 당신이 이 제품을 보았으므로, 이런 제품들에도 관심이 있으실 것입니다.
- 어떤 제품이 추천되는지에 대해서 소비자에게 통제 권한을 부여하기 시작
- 설정메뉴에서 추천알고리즘이 특정한 항목을 고려대상에서 배제하도록 설정가능
- 추천 알고리즘의 중요한 3가지
- 고객과의 관련성을 유지하기 위해 이상적으로는 추천이
실시간으로 갱신되어야 함 - 추천모델이 재고가 없는 제품, 반품 비율이 높은 제품, 사용후기가 나쁜 제품을 추천하는 것은 바람직하지 않다.
다양한 유형의 추천모델
- 상향 판매 upsell 추천
- 고객에게 더 나은 가격 조건을 제안하거나, 상품의 품질을 강조하는 등 고객이 희망했던 상품보다 단가가 높은 상품 판매 구입을 유도하는 판매방법입니다.
- 판매 증대는 물론 고객 만족을 위해서도 중요한 마케팅 활동입니다.
- ex) 500원 추가하면 라지사이즈 가능한데 변경하시겠습니까?
- 후속 판매 next sell 추천
- 후속 판매는 구매하고 며칠 후에 구매자의 기존 구매를 바탕으로 구매자에게 다른 제안을 독점적으로
진행하는, 후속 조치를 취하는 판매 행위입니다.
- ex) 구매자가 콤보 식사를 구매 한 경우 패스트 푸드 체인은 그들에게 독점적 인 월별 버거 클럽 제공을 실제 버거 애호가에게만 제공 할 수 있습니다.
- ex_ 컴퓨터를 구매하는 경우, 상점은 그들에게 ‘99 달러 할인 가격으로 ‘컴퓨터 사용 방법’워크숍에 참석할 수있는 독점적 인 제안을 보낼 수 있습니다.
- 참고: Upselling, Cross-selling and Next selling
- 교차 판매 cross sell 추천
- 한 제품을 구입한 고객이 다른 제품을 추가로 구입할 수 있도록 유도하는 것을 목적으로 합니다.
- 금융회사들이 자체 개발한 상품에만 의존하지 않고 다른 금융회사가 개발한 상품까지 파는 적극적인
판매방식입니다.
- ex) 햄버거만 시킬때, 점원이 ‘음료수는 안하시겠습니까?
일반적으로 함께 구입하는 제품들
- 고객별로 특화된 것이 아니다.
- 제품 대 제품 추천
- 이 제품을 구입한 고객은 일반적으로 어떤 다른 제품들을 구입했습니까? 라는 질문에 대한 답
- 동일한 제품을 검색하는 두 사람에게 동일한 추천을 적용한다.
- 이러한 유형의 일반적인 추천은 당신의 웹사이트를 처음 방문한 사람들처럼, 당신이 특정한 고객에 대해 별로 알지 못하고 있는 경우에 특히 적합하다
사용자에게 특화된 추천
- 제품 대 사용자 추천
- 비키니 세트를 탐색하는 동안 비키니 탑을 추천하는 것이 적절할 수 있다.
- 이 고객이 물건을 구입한 뒤, 2일 후에 그에게 감사 이메일을 보내면서 다음 구매 항목에 대한 추천을
이메일로 보내는 경우라면?
- 이 고객이 가장 최근에 검색한 내용들뿐만 아니라
- 그와 과거 기록 전체를 고려하여 이 사용자만을 위해 특화된 추천을 하는 것이 좋다
- 이 고객이 물건을 구입한 뒤, 2일 후에 그에게 감사 이메일을 보내면서 다음 구매 항목에 대한 추천을
이메일로 보내는 경우라면?
- ex_사쟘
- 사용자가 자신이 좋아하는 음악을 태그하면 그의 음악적 취향을 기록
- 취향에 근거해서 샤잠은 관심 있어 할 만한 콘서트들을 추천하는데 그 콘서트가 실제로 당신이 살고
있는 지역 근방에서 열리는 경우에만 추천한다.
- 샤잠이 고객의 취향뿐만 아니라, 고객의 지리적 위치를 알아야 한다.
예측분석 프로세스
데이터의 수집, 클랜징, 정비 preparation
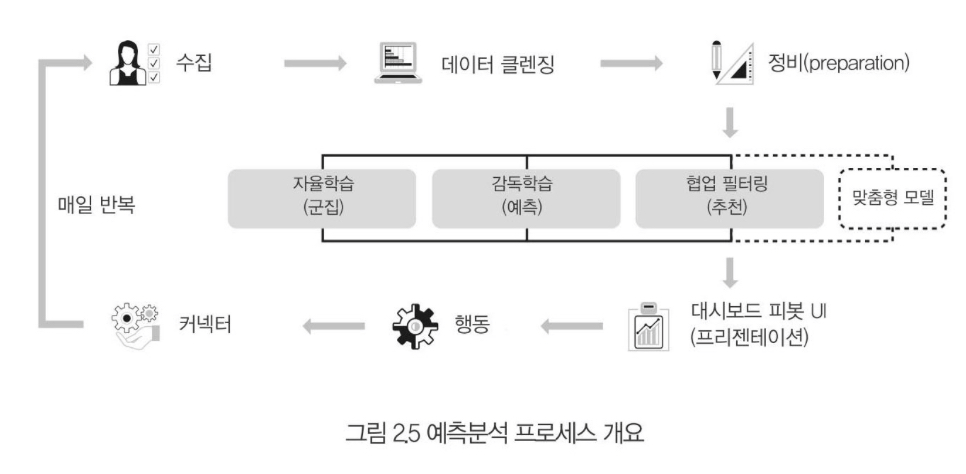
- 수집된 모든 데이터를 즉시 사용할 수 있는 것은 아니다.
- 누락된 데이터 또는 아웃라이어로 인해서 결과가 왜곡될 수 있고 (지나치게 높거나 낮은 데이터)
- 보유한 데이터 생성 시스템과 맞지 않는 데이터 유형이 있을 수도 있다.
이상치 검출
- 아웃라이어
- 일반 지속적 구매 소비자가 아닌 소수의 단기적 고액 소비자가 생길 경우 지표를 왜곡시킬 수 있음
- 상황을 인지하지 못한다면 vip 고객이라고 생각할 것이다.
- vip 고객 정의가 왜곡되어 진정한 vip 고객을 놓치게 됨
- 마케팅 전략의 방향을 읽게됨
- 아웃라이어를 제거해야함
- 결측값 대체
- 방법
- 평균값으로 대체
- 데이터가 가지고 있는 분포유형에서 무작위로 숫자를 선택
- 사용가능한 다른 변수를 기반으로 데이터 모델링
- 방법
feature의 생성 및 추출
- 데이터가 그대로 사용하기에 너무 큰 경우
- 현재 방식으로 표현된 데이터가 모델에 적합하지 않은 경우
- 특징 추출은 불필요한 정보를 삭제하거나 노이즈 제거를 위해 변환한다.
- 최적의 추출은 데이터에 포함된 노이즈를 감소시킴으로써, 예측분석의 정확성을 높인다.
분류 변수 classifier 및 시스템 설계
- 올바른 알고리즘을 선택
- 올바른 문제에 올바른 알고리즘 선택하기 위해서는 문제를 잘 이해하는 것이 중요
- 편향 분산 딜래마 bias-variance
- 특정한 문제에 편향된 biased 시스템은 다른 문제들을 해결하기 위한 성능이 점점 더 떨어지게 된다는 것이다. 참고 : 쉽게 이해해보는 bias-variance tradeoff
- 설계하고
- 미세조정하는 것
- back-test를 통해 실제로 작동하는지 테스트
- 자체 개발시 필요
- 80%훈련 + 10% 테스트 + 10% 유효성 검사
- 빅데이터를 활용한 예측마케팅 전략 책을 보고 이해한 내용을 정리 한 글입니다.
참고자료
Related
2020년 7월 3일
2020년 7월 1일
2019년 9월 22일