렌더링 엔진(1) - 파싱과 DOM트리 구축
https://d2.naver.com/helloworld/59361 를 읽고 정리했습니다.
- 브라우저의 주요 기능
- 렌더링 엔진 동작 과정
- HTML 파싱 (for DOM 트리 구축)
- 렌더 트리 구축
- 렌더 트리 배치
- 렌더 트리 그리기
파싱과 DOM 트리 구축
- 파싱에 대하여 문법 / 파서-어휘 분석기 조합 / 변환 / 파싱 예 / 어휘와 구문에 대한 공식적인 정의 / 파서의 종류 / 파서 자동 생성
- HTML 파서 => DOM 트리 문맥자유문법이 아니다 / HTML DTD / DOM / 파싱 알고리즘 / 파싱이 끝난 이후의 동작 / 브라우저의 오류 처리
- CSS 파서 => CSSOM 트리
- 스크립트와 스타일 시트의 진행 순서
1. 파싱 일반
- 문서 파싱 : 브라우저가 코드를 이해하고 사용할 수 있는 구조로 변환하는 것
- 파싱 트리(문법트리 syntax tree) : 파싱결과는 보통 문서 구조를 나타내는 노드 트리
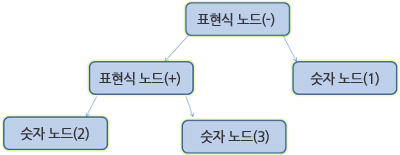 2 + 3 - 1
2 + 3 - 1
1-1. 문법
- 파싱은 문서에 작성된 언어 또는 형식의 규칙에 따른다.
- 파싱할 수 있는 모든 형식은 정해진 용어와 구문 규칙에 따라야 한다.
- 문맥 자유 문법 (Context-free grammar, CFG)
- 인간의 언어는 이런 모습과 다르기 때문에 기계적인 파싱이 불가능하다.
1-2. 파서-어휘 분석기 조합
- 파싱은
어휘 분석과구문 분석으로 구분할 수 있다.- 어휘 분석 : 자료를 토큰으로 분해하는 과정 ( 사전에 등장하는 모든 단어를 말한다고 볼수 있다. )
- 구문 분석 : 언어의 구문 규칙을 적용하는 과정
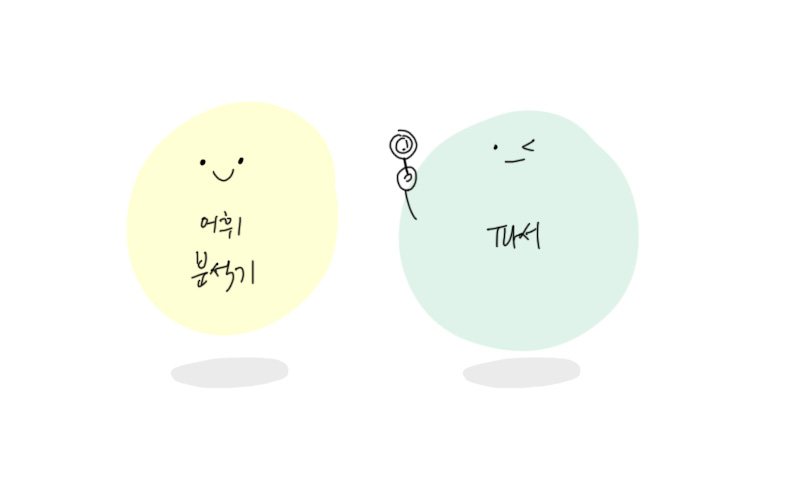
자료를 유효한 토큰으로 분해하는 **어휘 분석기(lexical analysis)**가 있고, 언어 구문 규칙에 따라 문서 구조를 분석함으로써 파싱 트리를 생성하는 파서가 있다.
- 어휘 분석기는 공백과 줄 바꿈 같은 의미 없는 문자를 제거한다.
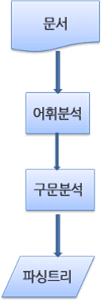
- 파싱과정은 반복됨
- 파서는 보통 어휘 분석기로부터 새 토큰을 받아서 구문 규칙과 일치하는지 확인 (언어 규칙들..)
- 규칙과 맞으면 토큰에 해당하는 노드가 파싱 트리에 추가되고 파서는 또 다른 토큰을 요청
- 규칙과 맞지 않으면 파서는 토큰을 내부적으로 저장, 토큰과 일치하는 규칙이 발견될 때까지 요청한다.
- 맞는 규칙이 없는 경우 예외로 처리하는데 => 문서가 유효하지 않고 구문 오류를 포함하고 있다는 의미
1-3. 변환 (컴파일!!)
- 파싱트리는 최종 결과물이 아니다.
- 파싱은 보통 문서를 다른 양식으로 변환하는데
- 컴파일이 하나의 예가 된다.
- 소스 코드를 기계 코드로 만드는 컴파일러는 파싱 트리 생성 후 이를 기계 코드 문서로 변환한다!

1-4. 파싱 예
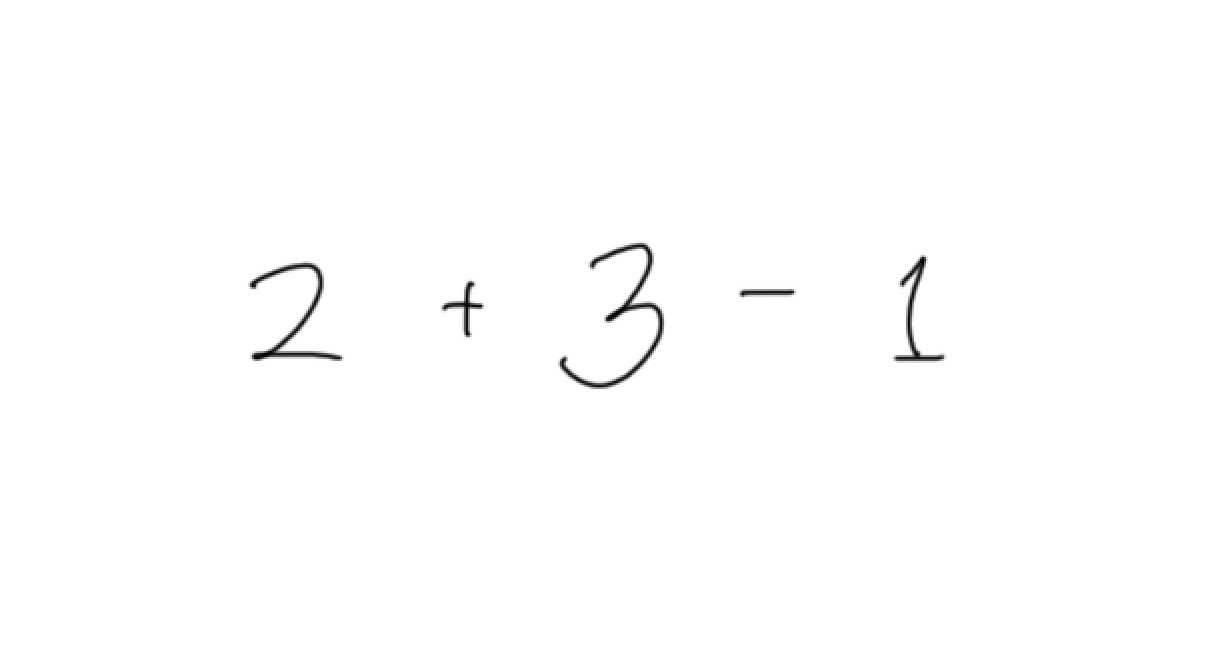
- 어휘 : 수학언어는 정수, 더하기 기호, 빼기 기호를 포함한다.
- 구문
- 언어 구문의 기본적인 요소는 표현식, 항(정수), 연산자(+,-)이다.
- 언어에 포함되는 표현식의 수는 제한이 없다.
- 표현식은 “항” 뒤에 “연산자” 그 뒤에 또 다른 항이 따르는 형태로 정의한다.
- 연산자는 더하기 토큰 또는 빼기 토큰이다.
- 정수 토큰 또는 하나의 표현식은 항이다.
- 2++는 어떤 규칙과도 맞지 않기 때문에 유효하지 않은 입력이 된다.
1-5. 어휘와 구문에 대한 공식적인 정의
어휘는 보통 정규표현식으로 표현한다.
INTEGER : 0|[1-9][0-9]*
PLUS : +
MINUS : -구문은 보통 BNF ( <기호> ::= <표현식>)라고 부르는 형식에 따라 정의한다.
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression문법이 문맥자유문법 (= 완전히 BNF 로 표현 가능한 문법)이라면, 언어는 정규 파서로 파싱할 수 있다.
1-6. 파서의 종류
- 하향식 파서 : 구문의 상위 구조로부터 일치하는 부분을 찾는다.
- 상향식 파서 : 낮은 수준에서 점차 높은 수준으로 찾는다.
1-7. 파서 자동 생성
파서 생성기 : 파서를 생성해 줄 수 있는 도구
- 언어에 => 어휘나 구문규칙 같은 문법을 부여하면 => 동작하는 파서를 만들어줌
- 파싱에 대한 깊은 이해를 필요로 하고 수동으로 파서를 최적화하여 생성하는 것은 쉬운일이 아니기 때문에 파서 생성기는 유용
웹킷
-
플렉스 Flex (fast lexical analyzer generator) : lex 의 기능을 개선한 자유 소프트웨어 (문법정의 프로그램) : 어휘 생성을 위한 어휘 분석기 발생기 : 토큰의 정규 표현식 정의를 포함한 파일을 입력 받는다. (?)
-
바이슨 Bison : 파서 생성을 위한 파서생성기 : BNF 형식의 언어 구문 규칙을 입력 받는다. : 상향식 이동 감소 파서
2. HTML 파서

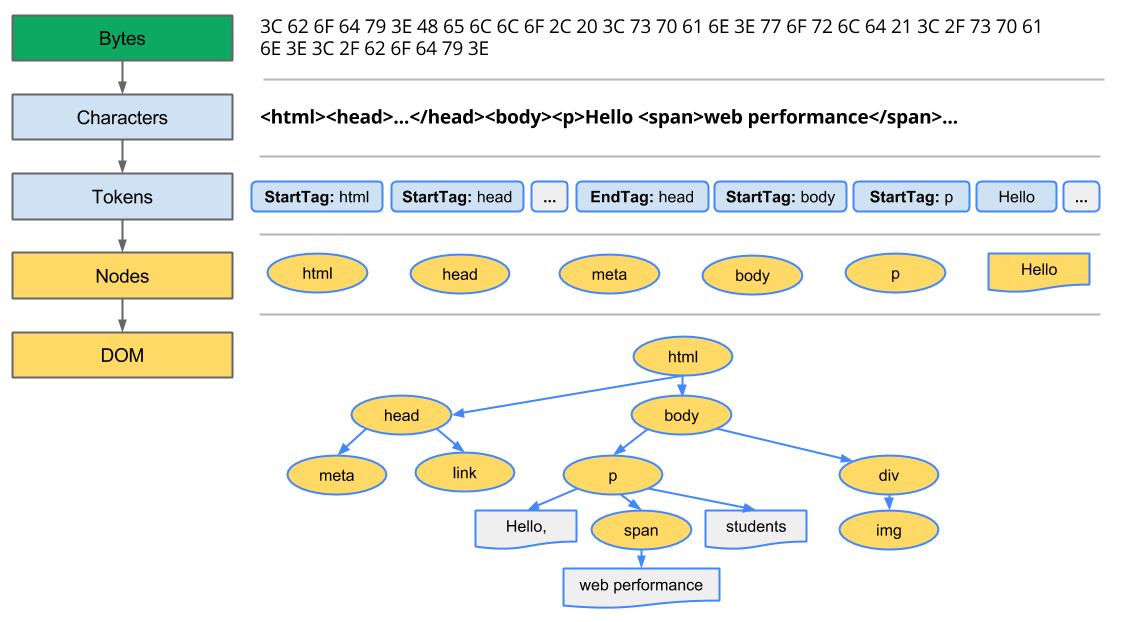
HTML 파서는 HTML 마크업을 파싱 트리로 변환한다.
2-1. HTML 문법 정의
2-2. 문맥 자유 문법이 아님
- 모든 전통적인 파서는 HTML 에 적용할 수 없다.
- 파싱은 CSS 와 자바스크립트를 파싱하는 데 사용된다.
- HTML 은 파서가 요구하는 문맥 자유 문법에 의해 쉽게 정의할 수 없다.
- HTML 은
너그럽다.- 암묵적으로 태그 생략이 가능하다.
- 시작태그, 종료 태그등을 생략한다.
- 뻣뻣하고 부담스러운 XML 에 반하여 HTML 은 유연한 문법이다.
- 공식적인 문법으로 작성하기 어렵게 만드는 문제가 있다..
2-3. HTML DTD (문석 형식 정의: Document Type Definition)
- DTD 는 문맥 자유 문법이 아니다.
- HTML 정의는 DTD 형식 안에 있다. (SGML 계역 언어의 정의를 이용한 것)
- HTML5, XHTML, HTML의 세가지 문서 유형이 존재하며, 기술한 유형에 따라 마크업 문서의 요소와 속성등을 처리하는 기준이 되며 유효성 검사에 이용된다.
- 이전 버전의 HTML(HTML2~HTML4)은 SGML(Standard Generalized Markup Language)에 기반을 두어 만들어졌기 때문에 DTD 참조가 필요하며, 이 때문에 DOCTYPE 선언을 하려면 공개 식별자와 시스템 식별자가 포함된 긴 문자열을 작성해야 한다.
- HTML5에서는 SGML 에 기반을 두지 않아서 DTD 참조가 필요 없으며, 최소한의 코드 작성이 기본 방향이라 매우 간단히 선언할 수 있다.
2-4. DOM (문서 객체 모델)
- 파싱트리는 DOM 요소와 속성 노드의 트리로서 출력 트리가 된다.
- 문서 객체 모델 : HTML 문서의 객체 표현이다.
- HTML 요소의 연결지점. 즉, 트리의 최상위 객체는 문서이다.
- HTML 정의
- DOM 정의
2-5. 파싱 알고리즘
HTML 은 일반적인 하향식 혹은 상향식 파서로 파싱이 안된다.
- 언어의 너그러운 속성
- 잘 알려져 잇는 HTML 오류에 대한 브라우저의 관용
- 변경에 의한 재파싱. 일반적으로 소스는 파싱하는 동안 변하지 않지만 HTML 에서
**
document.write**을 포함하고 있는 스크립트 태그는 토큰을 추가할 수 있기 때문에 실제로는 입력 과정에서 파싱이 수정된다.
일반적인 파싱 기술을 사용할 수 없기 때문에 브라우저는 HTML 파싱을 위해 별도의 파서를 생성한다.
TL;DR
- 바이트 → 문자 → 토큰 → 노드 → 객체 모델.
- HTML 마크업은 DOM(Document Object Model)으로 변환되고, CSS 마크업은 CSSOM(CSS Object Model)으로 변환됩니다.
- DOM 및 CSSOM 은 서로 독립적인 데이터 구조입니다.
- Chrome DevTools Timeline 을 사용하면 DOM 및 CSSOM 의 생성 및 처리 비용을 수집하고 점검할 수 있습니다.
- 알고리즘 은 토큰화와 트리구축 이렇게 2 단계로 되어 있다.
- byte stream decoder
- 브라우저가 HTML 의 원시 바이트를 디스크나 네트워크에서 읽어와서, 해당 파일에 대해 지정된 인코딩(예: UTF-8)에 따라 개별 문자로 변환합니다.
- 토큰화
- 어휘 분석(lexical analysis)으로서 입력 값을 토큰으로 파싱한다.
- HTML 에서 토큰은 시작 태그, 종료 태그, 속성 이름과 속성 값이다.
- 트리구축
- 토큰을 인지해서 트리 생성자로 넘기고 => 다른 토큰을 확인하기 위해 다음 문자를 확인
- 이 과정을 반복
(HTML 파싱 과정그림)
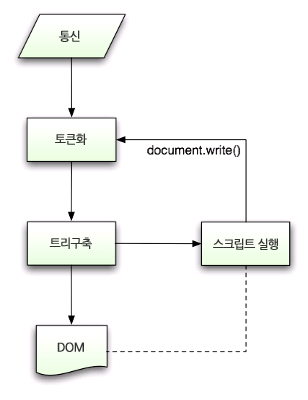
아래가 더 세분화된 과정

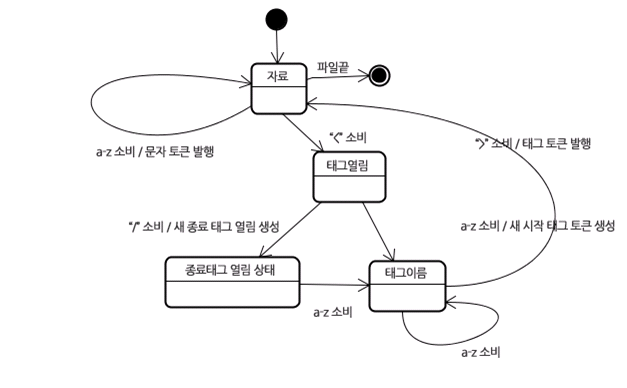
2-5-1. 토큰화 알고리즘
- 알고리즘의 결과물은 HTML 토큰
- 알고리즘은 상태기계라고 볼 수 있다.
- 각 상태는 하나 이상의 연속된 문자를 입력받아 이 문자에 따라 다음 상태를 갱신
예시 >
<html>
<body>
Hello world
</body>
</html>0.초기상태 : 자료 상태
<html> <body>
- 태그 열림 상태 :
<문자를 만나면 변함 - 태그 이름 상태 : a 부터 z 까지의 문자를 만나면 시작 태그 토큰생성 :
>를 만날 때까지 유지한다. : 각 문자에는 새로운 토큰 이름이 붙는다. 이때 생성된 토큰은 html 토큰 - 자료 상태 :
>문자에 도달하면 현재 토큰이 발행된다.
Hello world
- 문자 토큰 생성 발행
<문자를 만날 때까지 진행
</body> </html>
- 태그 열림 상태
- 태그 이름 상태 :
/문자는 종료 태그 토큰 생성 - 자료 상태 :
>문자에 도달하면 현재 토큰이 발행된다.
2-5-2. 트리 구축 알고리즘
- 파서 생성 후 문서 객체 생성
- 트리 구축이 진행되는 동안, 문서 최상단에서는 DOM 트리가 수정되고 요소가 추가된다.
- 토큰화에 의해 발행된 각 노드는 트리 생성자에 의해 처리된다.
- 각 토큰을 위한 DOM 요소의 명세는 정의되어 있다.
- DOM 트리에 요소를 추가하는 것이 아니라면 열린 요소는 스택(임시 버퍼 저장소)에 추가된다.
- 이 스택은 부정확한 중첩과 종료되지 않은 태그를 교정한다.
- 알고리즘은 상태 기계라고 설명할 수 있고 상태는 삽입 모드 라고 부른다.
예시 >
<html>
<body>
Hello world
</body>
</html>- 트리 구축 단계의 입력 값은 토큰화 단계에서 만들어지는 일련의 토큰이다.
- 노드화
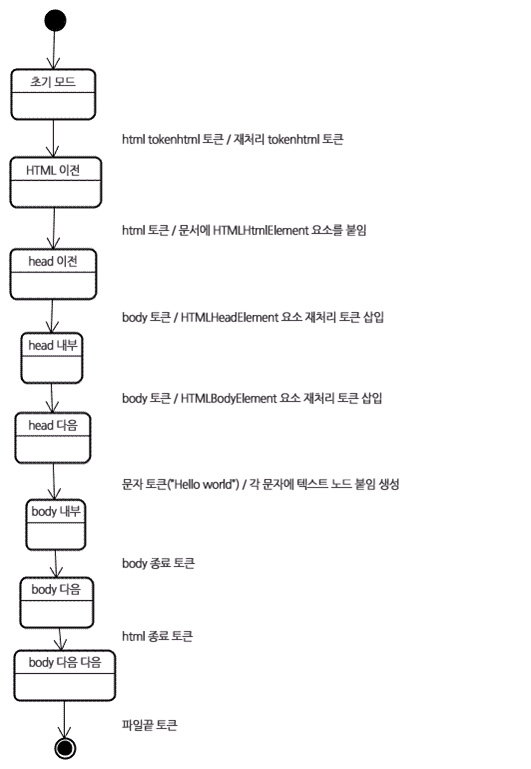
- 초기모드 : 받은 html 토큰은 html 이전 모드가 되면서 이 모드에서 처리된다. : 이것은 HTMLHtmlElement 요소를 생성하고 문서 객체의 최상단에 추가된다.
- head 이전 모드 : “body” 토큰을 받았다.
- head 안쪽 모드 : “head” 토큰이 없더라도 HTMLHeadElement 는 묵시적으로 생성되어 트리에 추가될 것이다.
- head 다음 모드 : body 토큰이 처리 되었고 (토큰화) HTMLBodyElement 가 생성되어 추가됐으며 “body 안쪽” 모드가 되었다.
- body 안쪽 모드 : 문자토큰 받음(Hellow world) : 첫 번째 토큰이 생성되고 “본문” 노드가 추가되면서 다른 문자들이 그 노드에 추가될 것이다.
- body 다음 모드 : body 종료 토큰을 받으면
- body 다음 다음 모드 : html 종료 토큰을 받으면
2-8. 파싱이 끝난 이후의 동작
- 문서 파싱 이후에 실행되어야 하는 “지연” 모드 스크립트를 파싱하기 시작한다.
- 문서 상태는 “완료 complete”가 되고 load이벤트가 발생한다. 보다 자세한 내용은 HTML5 의 토큰화 알고리즘과 트리 구축 에서 볼 수 있다.
2-9. 브라우저의 오류 처리
HTML 페이지에서 “유효하지 않은 구문”이라는 오류는 볼 수 없는데, 이는 브라우저가 모든 오류 구문을 교정하기 때문이다.
파서는 토큰화된 입력 값을 파싱하여 문서를 만들고 문서 트리를 생성한다. 때문에 파서는 적어도 다음과 같은 오류를 처리해야한다.
- 어떤 태그의 안쪽에 추가하려는 태그가 금지된 것일 때 일단 허용된 태그를 먼저 닫고 금지된 태그는 외부에 추가한다.
- 파서가 직접 요소를 추가해서는 안된다. 문서 제작자에 의해 뒤늦게 요소가 추가될 수 있고 생략 가능한 경우도 있다. HTML, HEAD, BODY, TBODY, TR, TD, LI 태그가 이런 경우에 해당한다.
- 인라인 요소 안쪽에 블록 요소가 있는 경우 부모 블록 요소를 만날 때까지 모든 인라인 태그를 닫는다.
- 이런 방법이 도움이 되지 않으면 태그를 추가하거나 무시할 수 있는 상태가 될 때까지 요소를 닫는다.
< 웹킷의 오류 처리하는 예 >
2-9-1. <br /> 대신 </br>
- 어떤 사이트는
<br />대신</br>을 사용한다. - 인터넷 익스플로러, 파이어폭스와 호환성을 갖기 위해 웹킷은 이것을
<br />으로 간주한다.
2-9-2. 어긋난 표
어긋난 표는 표 안에 또 다른 표가 th 또는 td 셀 내부에 있지 않은 것을 의미한다. 웹킷은 표의 중첩을 분해하여 형제 요소가 되도록 처리한다.
2-9-3. 중첩된 폼 요소
폼 안에 또 다른 폼을 넣은 경우 안쪽의 폼은 무시된다.
2-9-4. 태그 중첩이 너무 깊을 때
최대 20 개의 중첩만 허용하고 나머지는 무시한다.
2-9-5. 잘못 닫힌 html 또는 body 태그
깨진 html 을 지원한다. 일부 바보 같은 페이지는 문서가 끝나기 전에 body 를 닫아버리기 때문에 브라우저는 body 태그를 닫지 않는다. 대신 종료를 위해 end()를 호출한다.
DOM 트리는 문서 마크업의 속성 및 관계를 포함하지만 요소가 렌더링될 때 어떻게 표시될지에 대해서는 알려주지 않습니다. 이것은 CSSOM 의 역할.
3. CSS 파싱
- 문맥 자유 문법이다. 때문에 일반적인 파서 유형을 이용하여 파싱이 가능하다.
- CSS 명세
- 어휘 문법은 각 토큰을 위한 정규 표현식으로 정의되어 있다.
- 구문 문법은 BNF 로 설명되어 있다.
3-1. 웹킷 CSS 파서
- 웹킷은 자동으로 파서를 생성하기 위해 플렉스와 바이슨 파서 생성기를 사용한다.
- 웹킷의 바이슨을 사용하여 상향식 이동 감소 파서를 생성
- 파이어폭스 : 직접 작성한 하양식 파서를 사용한다.
- 모두 CSS 파일은 스타일 시트 객체로 파싱되고, CSS 규칙을 포함한다.
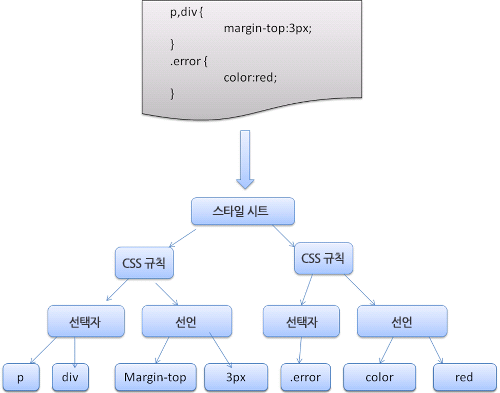
3-2. 브라우저별 사용자 에이전트 스타일
- 위의 트리는 완전한 CSSOM 트리가 아니고 스타일시트에서 재정의하도록 결정한 스타일만 표시한다는 점에 유의
- 모든 브라우저는 ‘사용자 에이전트 스타일’이라고 하는 기본 스타일 집합, 즉 개발자가 고유한 스타일을 제공하지 않을 경우 표시되는 스타일을 제공합니다.
- 개발자가 작성하는 스타일은 이러한 기본 스타일(예: 기본 IE 스타일)을 간단하게 재정의합니다.
4. 스크립트와 스타일 시트의 진행 순서
4-1. 스크립트
- 웹은 파싱과 실행이 동시에 수행되는 동기화 모델이다.
<script>태그를 만나서 실행되는 동안 문서의 파싱은 중단된다. (그래서 바디 전에 넣음)- 스크립트가 외부에 있는 경우 우선 네트워크로부터 자원을 가져와야 하는데 이 또한 실시간으로 처리되고 자원을 받을 때까지 파싱은 중단된다.
- 스크립트를 “지연(defer)”으로 표시할 수 있는데 지연으로 표시하게 되면 문서 파싱은 중단되지 않고 문서 파싱이 완료된 이후에 스크립트가 실행된다. (비동기)
4-2. 예측 파싱 (Speculative parsing)
- 스크립트를 실행하는 동안 다른 스레드는 네트워크로부터 다른 자원을 찾아 내려받고 문서의 나머지 부분을 파싱한다.
- 이런 방법은 자원을 병렬로 연결하여 받을 수 있고 전체적인 속도를 개선한다.
- 참고로 예측 파서는 DOM 트리를 수정하지 않고 메인 파서의 일로 넘긴다. 예측 파서는 외부 스크립트, 외부 스타일 시트와 외부 이미지와 같이 참조된 외부 자원을 파싱할 뿐이다.
4-3. 스타일 시트
- 이론적으로 스타일 시트는 DOM 트리를 변경하지 않기 때문에 문서 파싱을 기다리거나 중단할 이유가 없다.
- 그러나 스크립트가 문서를 파싱하는 동안 스타일 정보를 요청하는 경우라면 문제가 된다.
- 스타일이 파싱되지 않은 상태라면 스크립트는 잘못된 결과를 내놓기 때문에 많은 문제를 야기한다.
- 파이어폭스는 아직 로드 중이거나 파싱 중인 스타일 시트가 있는 경우 모든 스크립트의 실행을 중단한다.
- 웹킷은 로드되지 않은 스타일 시트 가운데 문제가 될만한 속성이 있을 때에만 스크립트를 중단한다.
참고링크
- https://d2.naver.com/helloworld/59361
- https://developers.google.com/web
- https://developers.google.com/web/fundamentals/performance/critical-rendering-path/constructing-the-object-model?hl=ko
- [WEBDIR] http://webdir.tistory.com/40
- https://developers.google.com/web/fundamentals/performance/critical-rendering-path/constructing-the-object-model?hl=ko